Age for letter recognition
FAQ: Your Reading Child
Q: How old should a child be when he or she learns to recognize letters?
A: Most children learn to recognize letters between ages 3 and 4. Typically, children will recognize the letters in their name first. By age 5, most kindergarteners begin to make sound-letter associations, such as knowing that “book” starts with the letter B.
Q: How old should a child be when he or she learns to read?
A: By age 6, most 1st graders can read some words aloud with ease. Typically, children recognize their names and some sight words. At this age most children can sound out some letter combinations. By 2nd grade, most children are able to sound out a simple book.
Q: What is phonics?
A: Phonics is simply the method of teaching someone to read by sounding out letters and letter groups. Phonics practice can involve reading books with only simple words, many of which rhyme or have similar letter patterns.
Q: How do you read with a child who is just learning letters and sounds?
A: To introduce the concept of letters and sounds, start by showing your child the letters in her name. Name each letter and sound out each sound. You can do this with other words that interest her (mom, dad, baby, etc.). Once your child knows most of the letters in the alphabet, point to letters in the books you read with her, and ask her what they are. Show her how you sound out simple words:
This word starts with “D” which is the “duh” sound. Then there’s an “o” and a “g”. The “g” makes a “guh” sound. “Duh”-o-“guh”. Do you think that word is dog?
As your child learns to read, try alternating pages in a simple book — you read one page, she tries to read the next.
Q: What are appropriate books for my child’s age and/or level?
A: Using Lexile Measures or Leveled Reading, your child’s school has probably determined the level at which your child is reading. Your goal is to help your child pick books that are challenging, but not too hard to enjoy. Librarians, teachers, and online databases like those at www.lexile.com can help.
Q: What is leveled reading?
A:Leveled reading is a way to match a reader to a book that is at the just-right level for him. An emerging reader needs to be challenged to read more difficult books, but the books can’t be too hard for him to attempt on his own. When entering a leveled reading program, a student first takes a test to determine his level.
An emerging reader needs to be challenged to read more difficult books, but the books can’t be too hard for him to attempt on his own. When entering a leveled reading program, a student first takes a test to determine his level.
Q: What is a Lexile Measure?
A: Both books and readers can be measured using the Lexile Framework. If your student has taken a test at school and received a Lexile Measure, you can visit www.Lexile.com to learn how to best use this information, including ways to find the perfect level book for your child.
Q: My child isn’t reading at his grade level and he says she “hates” reading. What should I do?
A: If your child falls behind even in early elementary school, you may want to have her evaluated for a learning disability. Even if the result is inconclusive, it’s best to know if your child has any special issues, as there are methods to teaching reading to children with special needs that work better than some traditional reading programs. Alternately, your child might just need more engaging books. There are many books available, such as the Captain Underpants series, as well as comic books, which “reluctant readers” love. Keep your child engaged with reading by encouraging her to read what she enjoys.
Alternately, your child might just need more engaging books. There are many books available, such as the Captain Underpants series, as well as comic books, which “reluctant readers” love. Keep your child engaged with reading by encouraging her to read what she enjoys.
Q: Where can I find lists of quality children's books?
A: The Association for Library Service to Children grants book and media awards to the best offerings for children. This is where you can find information on recent Newbery Award winners (most distinguished contribution to American literature for children) and Caldecott Medal winners (most distinguished American picture books), among others. This site also houses multiple book lists for children
Q: How can I encourage my child to read despite all the other distractions?
A: The best way to show that reading books can be fun and rewarding is to model the behavior you want from your children After dinner or on a lazy weekend afternoon, instead of turning on a movie or the TV, curl up with your own book, and encourage your child to do the same. Young children also love being read to, and if you are tired of the books in your house, a trip to the library can give you a new stack to read. Even if this only happens once a week, it may become a cherished family tradition.
Young children also love being read to, and if you are tired of the books in your house, a trip to the library can give you a new stack to read. Even if this only happens once a week, it may become a cherished family tradition.
At What Age Should a Child Know the Alphabet? – Smaller Scholars
As children grow, they naturally hit learning milestones. One of the most critical educational milestones a child must reach is learning the alphabet, which prepares them for reading and writing.
But at what age should a child know the alphabet?
In this article, you will learn at what age a child should know how to recite the alphabet, recognize and write individual letters, learn letter sounds, and eventually learn how to read. Read on to make sure your little one is on the right track!
At What Age Should a Child Know the Alphabet?
Recitation
Typically, by the age of three, children should be able to recite the alphabet. However, every child is different. Some toddlers may learn in their twos, and others might not pick it up until the late threes.
Some toddlers may learn in their twos, and others might not pick it up until the late threes.
Children generally learn how to recite the alphabet through repetition. If you sing the ABC song to your kids often, they are more likely to pick it up quicker, just as they would any song.
Recognition
Most children can recognize letters between the ages of three and four. Most kids will recognize the letters in their name first.
For example, a boy named Jace will probably be able to remember what the letter “J” looks like as well as recognize most other letters in his name. Similar to alphabet recitation, use repetition to teach your children about recognizing individual letters. You may ask them, “What letter is that?” whenever you see an isolated letter.
Writing
By ages four to five, children will start writing letters. Children will learn to write the alphabet in preschool and kindergarten, but it may be beneficial to have your child practice writing his/her letters at home. Most children at this age know that written symbols represent messages and may be interested in writing on their own. One of the easiest ways children learn how to write letters is to begin tracing them.
Most children at this age know that written symbols represent messages and may be interested in writing on their own. One of the easiest ways children learn how to write letters is to begin tracing them.
Additionally, teaching your child how to write his/her name is an important step that will ultimately help them become familiar with writing the rest of the alphabet.
Sounds
By five years old, children will start to associate letters with their accompanying sounds, otherwise known as phonics. In other words, around the age of five, children should be able to reason that the word “book” starts with the letter B.
Children begin learning phonics in kindergarten, which is a vital step to decoding written text and begin reading.
Reading
By six years old, first graders should be able to read words aloud with ease. For the most part, children can recognize sight words and their names. Moreover, children can decode some words by sounding out their letter combinations.
By second grade, a child should be able to sound-out a simple book. By the third grade, your child should be able to read independently and fluently. By this point, your child should be a master of the alphabet and is ready to master the art of reading!
What If Your Child Isn’t Learning at the Rate S/He Should?
It’s important to remember that every child is different and may learn at a different rate. If your child isn’t learning the alphabet at the pace s/he should, one reason may be because s/he isn’t interested or is simply undergoing a minor setback.
However, if your child is falling severely behind, it’s important to find out if your child truly has a problem learning or if it is nothing to worry about. Therefore, work one-on-one with your child to determine if there is a problem. For example, practice reading and writing with your child. If s/he is having a hard time comprehending the instruction or if it’s taking him/her an abnormally long time to do the task, consider talking with your child’s teacher about it.
In the end, if you suspect your child might have a reading or learning disability, discuss it with a doctor. If your child is truly suffering from a reading disability, it can cause him/her to fall behind in his/her education. The sooner you seek help, the sooner you will be able to find a solution that works for your precious little one!
Learn the Alphabet at a Top-Tier School!
So at what age should a child know the alphabet? Learning the alphabet is an ongoing process. That being said, it’s crucial to enroll your little one in a school that will not only teach him/her but also helps develop in him/her a love of learning.
Smaller Scholars Montessori Academy helps children become more confident, creative, and independent through the acclaimed Montessori experience. You can enroll your child in the toddler program, which is for kids between the ages of eighteen months and three years, or in the primary program, for children between three and six years. In both programs, children have a rich classroom environment in which they are encouraged to explore, learn, and thrive. Then, as children grow older, they can explore the elementary program for kids up to twelve years old.
Then, as children grow older, they can explore the elementary program for kids up to twelve years old.
What are you waiting for? Ensure your child learns the alphabet and how to read by enrolling your child in Smaller Scholars Montessori Academy! Contact them to learn more.
From pixels to letters: how OCR works
What is OCR?
OCR (eng. optical character recognition , optical character recognition) is a technology for automatically analyzing text and turning it into data that a computer can process.
When a person reads a text, he recognizes the characters with the help of his eyes and brain. For a computer, the scanner camera acts as an eye, which creates a graphic image of a text page (for example, in JPG format). For a computer, there is no difference between a photo of text and a photo of a house: both are a collection of pixels.
It is OCR that turns an image of text into text. And you can do anything with the text.
How does it work?
Imagine there is only one "A" in the alphabet. Will this make the task of converting an image to text easier? No. The fact is that each letter (and any other grapheme) has allographs - different styles.
Variants of the letter "a".A person will easily understand that all this is the letter "A". For a computer, on the other hand, there are two ways to solve the problem: to recognize characters as a whole (pattern recognition) or to highlight the individual features that make up a character (feature detection).
Pattern recognition
In the 1960s, a special OCR-A font was created for use in documents such as bank checks. Each letter in it was the same width (the so-called fixed-width font or monospace font).
Sample font OCR-A Receipt printers worked with this font and software was developed to recognize it. Since the font has been standardized, recognizing it has become a relatively easy task. The next step was to train OCR programs to recognize characters in several more common fonts ( Times, Helvetica, Courier , etc.).
The next step was to train OCR programs to recognize characters in several more common fonts ( Times, Helvetica, Courier , etc.).
Feature detection
This method is also called intelligent character recognition (eng. intelligent character recognition, ICR ). Imagine that you are an OCR program that has been given many different letters written in different fonts. How do you select all the letters "A" from this set, if each of them is slightly different from the other?
You can use this rule: if you see two lines converging at the top in the center at an angle, and in the middle between them a horizontal line, then this is the letter "A". This rule will help recognize all the letters "A" regardless of the font. Instead of pattern recognition, the characteristic individual features that make up the symbol are highlighted. Most modern omnifont (able to recognize any font) OCR programs work on this principle. Most often, they use classifiers based on machine learning (since, in fact, we are faced with the task of classifying images by letter classes), recently some OCR engines have switched to neural networks.
What to do with handwriting?
A person is able to guess the meaning of a sentence, even if it is written in the most illegible handwriting (unless it is a prescription for drugs, of course).
The task for the computer is sometimes simplified. For example, people are asked to write the zip code in a special place on the envelope in a special font. Forms created for further processing by a computer usually have separate fields that require you to fill in capital letters.
Tablets and smartphones that support handwriting often use the principle of feature detection. When writing the letter "A", the screen "feels" that the user first wrote one line at an angle, then another, and finally drew a horizontal line between them. The computer is helped by the fact that all signs appear sequentially, one after another, in contrast to the option when all the text is already written by hand on paper.
OCR by steps
Pretreatment
The better the quality of the original text on paper, the better the recognition quality will be. But the old font, coffee or ink stains, paper creases reduce the chances.
But the old font, coffee or ink stains, paper creases reduce the chances.
Most modern OCR programs scan a page, recognize the text, and then scan the next page. The first stage of recognition is to create a copy in black and white or in shades of gray. If the original scanned image is perfect, then all black is the characters and all white is the background.
Identification
Good OCR programs automatically mark difficult page structure elements such as columns, tables, and pictures. All OCR programs recognize text sequentially, character by character, word by word, and line by line.
First, the OCR program combines pixels into possible letters and letters into possible words. The system then matches word variants with the dictionary. If a word is found, it is marked as recognized. If the word is not found, the program provides the most likely option and, accordingly, the recognition quality will not be as high.
Post-processing
Some programs allow you to view and correct errors on each page. To do this, they use the built-in spell checker and highlight misspelled words, which may indicate incorrect recognition. Advanced OCR programs use a so-called neighbor search method to find words that often occur side by side. This method allows you to correct the misrecognized phrase "melting dog" to "barking dog".
To do this, they use the built-in spell checker and highlight misspelled words, which may indicate incorrect recognition. Advanced OCR programs use a so-called neighbor search method to find words that often occur side by side. This method allows you to correct the misrecognized phrase "melting dog" to "barking dog".
In addition, some projects that are engaged in digitization and recognition of texts resort to the help of volunteers: recognized texts are laid out in the public domain for proofreading and checking recognition errors.
Special cases
For high accuracy of recognition of historical text with unusual graphic characters that differ from modern fonts, it is necessary to extract the corresponding images from documents. For languages with a small character set, this can be done manually, but for languages with complex writing systems (such as hieroglyphics), manual collection of this data is not practical.
To recognize historical Chinese texts, you need to enter at least 3000 characters in the OCR program, which have different frequencies. If manual marking of several tens of pages is sufficient for recognition of historical English texts, then a similar process for Chinese will require the analysis of tens of thousands of pages.
If manual marking of several tens of pages is sufficient for recognition of historical English texts, then a similar process for Chinese will require the analysis of tens of thousands of pages.
At the same time, many historical Chinese scripts have a high degree of similarity with modern writing, so character recognition models trained on modern data can often give acceptable results on historical data, albeit with reduced accuracy. This fact, together with the use of corpora, makes it possible to create a system for recognizing historical Chinese texts. For this, researcher D. Stegen ( Donald Sturgeon ) from Harvard processed two corpus: a corpus of transcribed historical documents and a corpus of scanned documents of the desired style.
After image pre-processing and character segmentation steps, the training data extraction procedure consisted of:
1) applying a character recognition model trained exclusively on modern documents to historical documents to obtain an intermediate OCR result with low accuracy;
2) use this intermediate result to match the image with its probable transcription;
3) extract images of marked up characters based on this mapping;
4) selection of suitable training examples from marked symbols.
The obtained data can be used without validation to train a new character recognition model, which allows to achieve higher accuracy on similar material.
Sources:
- Optical character recognition (OCR)
- Unsupervised Extraction of Training Data for Pre-Modern Chinese OCR
Author: System Block
Tags:OCR, OCR
Artificial intelligence, neural networks and handwriting recognition
Technology
Artificial intelligence is completely changing the way we think about how people write information, and opens up new horizons for the development of digital handwriting technology.
The Importance of Artificial Intelligence
Instead of the full term "artificial intelligence", the abbreviation "AI" is often used. This is a branch of computer science that studies the principles of creating intelligent machines that can reproduce and complement certain functions of the human brain, in particular the skills of reading, understanding or analysis.
Artificial intelligence in MyScript
Our main software products are based on AI module own development. Artificial intelligence helps us recognize handwritten content in over 70 languages, analyze the structure of handwritten notes, understand mathematical equations, and even identify and translate handwritten notes.
We have been developing and improving this technology for over 20 years. In our quest to create the world's most accurate handwriting recognition engine, we've done (and continue to do) a lot of research on language nuances: word-level and word-level sentence building, rules for placing diacritics above or below certain vowels, etc. .
Several groups of MyScript researchers are continuously working on optimizing a best-in-class system capable of recognizing an impressive array of handwritten content.
Handwriting Research
Our Handwriting Research teams are solving problems with sequence transformation (seq2seq), such as converting handwriting into its constituent characters, using machine learning technologies.
They need to be adapted to the alphabets of the world and conventions. This is a prerequisite for recognizing, for example, languages written from right to left, such as Arabic and Hebrew, diacritical vowels in Indian texts, Chinese characters, the Korean Hangul alphabet, or vertical characters from Japanese hiragana, katakana, and kanji.
2D Handwriting Research
This department is responsible for building mathematical models based on two-dimensional array parsers and/or grammar rules. They deal with problems that cannot be solved by sequence transformation. This is the recognition of mathematical expressions, notes or charts and graphs. These specialists use graph-based methods for recognition. The main difficulty is real-time data processing.
This is the recognition of mathematical expressions, notes or charts and graphs. These specialists use graph-based methods for recognition. The main difficulty is real-time data processing.
Natural Language Processing Research
Our natural language processing experts create algorithms that can perceive languages as naturally as humans. This division works with a corpus of texts containing hundreds of millions of words from publicly available documents and articles. Dictionaries are compiled from them, models for substituting characters in sentences and systems for detecting and correcting typos are developed on their basis.
Data collection
A large part of our work is based on the processing of anonymous data samples that are voluntarily sent to us by users from around the world. These “training cases,” as AI researchers call them, are always subject to the highest privacy and security standards. This is very valuable information for the company, which allows us to improve and expand the capabilities of the technology.
This is very valuable information for the company, which allows us to improve and expand the capabilities of the technology.
Handwriting recognition: challenges
Handwriting recognition is inextricably linked with serious technical difficulties due to the huge variability of handwriting. The result can be affected by the age of the author, the dominant hand, the home country, even the surface on which he writes - and all this without considering the influence of language and alphabet.
To illustrate this clearly, let's take an example: effective handwriting recognition software must be able to distinguish the desired Chinese character among more than 30,000 possible variations. It is also expected to support bidirectional recognition and decoding to avoid crashes when a right-to-left language (such as Arabic or Hebrew) encounters left-to-right foreign words.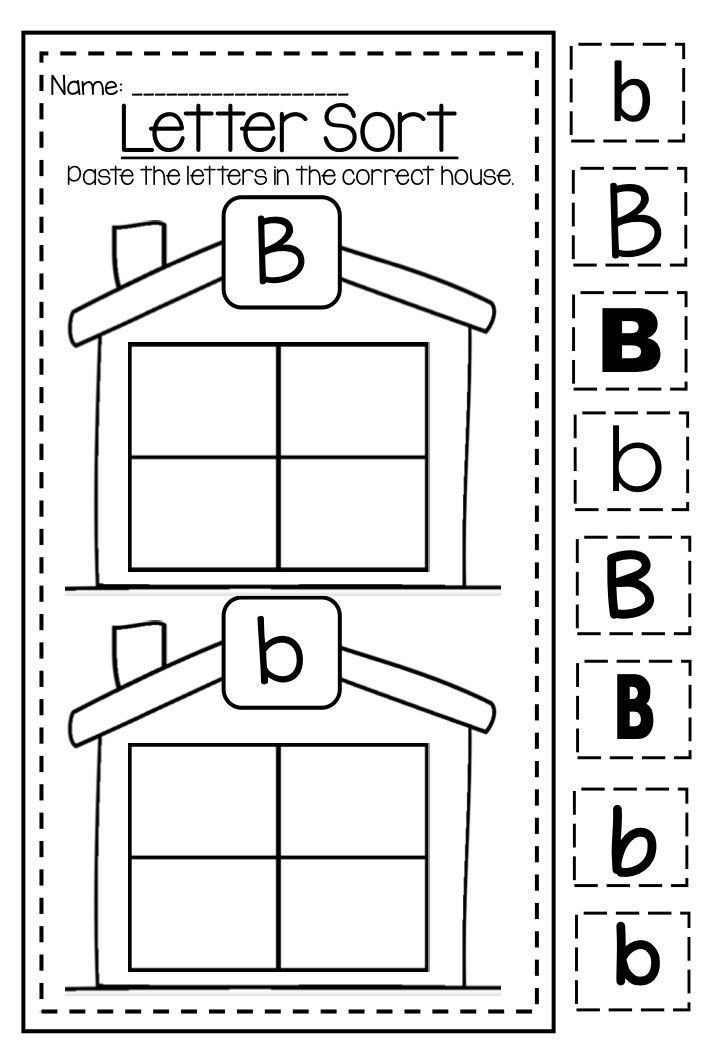
Continuous handwriting further complicates the task of segmenting and recognizing individual characters, and delays in adding strokes (in particular diacritics) introduce additional confusion. Their characteristic lack of a clear structure makes automatic content analysis even more laborious. The presence of objects from other categories does not simplify it either: mathematical expressions, graphs and tables.
The time factor is also important: handwriting recognition software must analyze user input in real time as it is being written. If the user makes edits, such as strikethrough a word to delete it, insert a space, or move a paragraph, then the recognition engine must respond in a timely manner.
Among other things, a handwriting recognition solution needs to be able to parse both printed characters and handwritten strokes so that users can import typed text from web pages or other applications and then annotate it by hand if required. A robust recognition engine must handle such complex interactions with high accuracy, accurately distinguishing editing gestures, adding diacritics, and writing new characters and words.
A robust recognition engine must handle such complex interactions with high accuracy, accurately distinguishing editing gestures, adding diacritics, and writing new characters and words.
Investments in the development of neural networks
More than 20 years ago, when the international handwriting recognition community was actively investigating Hidden Markov Models and Support Vector Machines, MyScript took a different path.
We decided to focus on neural networks.
A neural network is a machine learning method that replicates the cognitive processes that take place in the human brain. Powerful algorithms at the heart of the neural network allow you to identify patterns in large datasets, improving the accuracy of generalizations in the field of study - in our case, this is handwriting.
Neural networks are made up of mathematical models that "learn" to find patterns using predefined variables ("criteria"). Carefully programmed algorithms constantly separate and sort data based on specified criteria, classifying it over and over again until clear patterns are found.
Carefully programmed algorithms constantly separate and sort data based on specified criteria, classifying it over and over again until clear patterns are found.
This means that neural networks are capable of tasks that a person cannot handle. They sift through vast amounts of information at high speed, allowing patterns to be registered that would otherwise escape attention. We were confident that we could use neural networks to train our handwriting recognition engine to produce the most accurate and advanced technology in the world.
Handwriting recognition using neural networks
The original idea was to pre-process the ink content in preparation for analysis: extracting lines, smoothing the ink tone, and correcting italic characters. Then it was supposed to perform super-segmentation and pass the text through the recognition module to detect boundaries between characters and words.
This involved building a segmentation graph by simulating all existing options: in essence, grouping adjacent segments into expected combinations of characters, which would then be classified using feed-forward neural networks. We have chosen an innovative approach based on the global differentiated learning scheme. Today, this technique is often used as part of connection temporal classification (CTC) to train neural systems to transform sequences.
We also made a small revolution by creating and implementing a statistical language model that combined lexical, grammatical and semantic data. It made it possible to refine the results and eliminate some of the contradictions in the presence of several suitable symbols.
AI training for 2D languages
The use of neural networks has brought us success and allowed us to create the world's best recognition module that supports both printed and handwritten characters. But some languages have turned out to be much more complex in structure, leaving us with a new complexity.
But some languages have turned out to be much more complex in structure, leaving us with a new complexity.
Chinese Character Recognition
During its existence, MyScript has created a number of technical solutions for the analysis and recognition of two-dimensional languages, especially Chinese characters.
When most of our competitors took the path of analyzing and recognizing Chinese characters using decision tree models, we concentrated all our efforts on improving neural networks, training our module so that it could learn any of the more than 30,000 characters.
For the first time in the history of the industry, the research division was able to successfully put such a large network into operation. This was made possible thanks to a large-scale data collection campaign, which allowed us to accumulate the largest body of texts with handwritten characters in Chinese.
Based on these data, a new neural architecture was built, which took into account all the features of writing Chinese characters. In addition, we have added a special clustering mechanism to make processing faster. These innovative techniques have helped us take handwriting recognition to the next level in a segment where keyboard entry remains overly complex and inflexible. It also provides a similar level of support for other languages, including Japanese, Hindi, and Korean.
Recognition of mathematical expressions
When neural networks learned to successfully analyze and recognize texts in various languages of the world, we set ourselves a new goal: to introduce our module to mathematical expressions.
If in regular languages symbols and words are combined into structural sequences, then in two-dimensional languages (with visual syntax) the structure of a tree or a graph with spatial relationships between nodes predominates. As in the case of texts, our mathematical expression recognition system is based on the principle that in order to obtain the most accurate results, the processes of segmentation, recognition, and grammatical-syntactic analysis must proceed simultaneously and at the same level.
As in the case of texts, our mathematical expression recognition system is based on the principle that in order to obtain the most accurate results, the processes of segmentation, recognition, and grammatical-syntactic analysis must proceed simultaneously and at the same level.
Our module determines the spatial relationships between the parts of a mathematical equation according to the rules on which its special grammatical structure is based, and then uses this data to break the expression into segments. The grammatical structure itself is a set of rules that describe the principles of equation analysis. Each rule corresponds to a specific spatial relationship. For example, the fraction rule defines a vertical relationship between the numerator, fractional bar, and denominator.
Understanding Unordered Notes
The ability to quickly and accurately recognize mathematical expressions has opened up completely new possibilities for working with the structure and content of handwritten notes.
If a recognition engine is able to correctly determine the spatial relationships between parts of mathematical equations, can it classify non-text objects just as accurately? If yes, then it would solve the problems of handling unordered notes by using our technology to pinpoint elements and even improve the look of some of them, such as hand-drawn diagrams.
We felt that graph neural networks (GNNs) would be the best fit for these purposes. In this case, the main idea is to represent the entire document in the form of a graph, where strokes are represented by nodes and connected to neighboring strokes using edges.
When parsing the content of a note in this way, the graph neural network must classify each stroke as a text or non-text character. To do this, each stroke's own characteristics and (if necessary) the context data obtained from its neighboring edges and nodes are checked.
One of the levels in a graph neural network combines all the characteristics of a node with the characteristics of neighboring objects and forms a vector of numerical values representing the characteristics of a higher level. As in convolutional neural networks, stacking of several levels is supported to obtain a larger number of global characteristics and, accordingly, more accurately classify strokes as text or non-text. In the diagram below, for example, the 2 vertical lines on the left appear to be the same. And only after receiving contextual data from adjacent strokes, the graph neural network can classify them at the output level as part of the rectangle (leftmost stroke) and part of the T symbol.
Deep Learning and Encode/Decode Model
A couple of best-in-class systems for OCR and math may not be enough either, especially for users who are working or studying for a job in a particular field of science. They often need to write down math formulas as they type (not in a dedicated space on the page), and they rely on the recognition engine to process them correctly.
They often need to write down math formulas as they type (not in a dedicated space on the page), and they rely on the recognition engine to process them correctly.
The difficulty was to create a system that could recognize characters and words along with mathematical expressions, that is, analyze combinations of characters from natural one-dimensional language (text) and two-dimensional language (mathematical formulas).
With the advent of deep learning technology, new neural network architectures have come. One of them, the encode/decode model, has become a very popular tool for solving sequence transformation problems. It allows you to process input and output strings of variable length, so it quickly gained popularity in areas that are somehow related to handwriting recognition (for example, speech recognition). The main advantage of the encoding/decoding technology is complex training, unlike systems where each element must be trained separately. Multiple architectures are supported, including convolutional neural networks, recurrent neural networks, long short-term memory (LSTM) networks, and attention-based networks commonly used in the Transformer model (among many others). 92 instead of x² or (\frac{ }) instead of a fraction).
Multiple architectures are supported, including convolutional neural networks, recurrent neural networks, long short-term memory (LSTM) networks, and attention-based networks commonly used in the Transformer model (among many others). 92 instead of x² or (\frac{ }) instead of a fraction).
The future of handwriting powered by artificial intelligence
The evolution of handwriting recognition technology has not yet reached its final stage. We are already expanding AI capabilities for tasks such as automatic language detection and recognition of interactive handwritten tables.
We are convinced that deep learning models have a huge potential for development. Perhaps they will help us to unify the approach in areas of research that were not previously considered related (for example, natural language processing and structure analysis). With the exceptional availability of touch-enabled digital devices, we are confident that artificial intelligence algorithms will help us move from vision recognition to intent recognition.