Matching upper and lower case
Matching Uppercase and LowerCase Letters
This interactive and hands on game to teach matching uppercase and lowercase letters is a fun gross motor game for preschool and kindergarten. Use this interactive letter activity along as an alphabet matching with objects and a sensory-motor learning activity!
Matching uppercase letters to lowercase letters is a literacy task that supports reading skills, but also challenges visual discrimination skills, form constancy, and visual scanning, all of which are visual processing skills needed for handwriting and reading comprehension. What’s fun about this activity is that it builds these skills in a fun way!
Be sure to grab our color by letter worksheet to work on letter matching, visual discrimination skills.
Matching Uppercase and Lowercase Letters
Learning letters and matching upper and lower case letters is a Kindergarten skill that can be tricky for some kids. We made this easy prep letter identification activity using items you probably already have in the house. If you’ve seen our blog posts over the last few days, you’ve noticed we’re on a learning theme using free (or mostly free) items you probably already have.
We’re sharing 31 days of learning at home with free materials this month along with 25 other bloggers in the 31 days of homeschooling tips series.
Today’s easy letter learning activity can use any letters you have around the house or magnetic letters and coffee filters.
While this activity is almost free if you’ve got the items at home already, we’re sharing the affiliate links for the items in this post.
How to play this interactive letter matching activity
You’ll need just a few items for this letter matching activity:
- Magnetic letters
- marker
- coffee filters (but paper towels or recycled paper would work as well.
To set up the activity, there are just a few steps:
- Grab the magnetic letters from the fridge and 26 coffee filters.

- Use a permanent marker to write one lower case letter of the alphabet on each coffee filter.
- With your child, match the magnetic letters to the lowercase letters on the coffee filters.
- Ask the child to help you crumble each letter inside the coffee filter that has its matching lowercase letter.
- Continue the play!
More ways to match uppercase and lowercase letters
By matching the magnetic uppercase letter to the lowercase letter on the coffee filter, kids get a chance to incorporate whole body movements and gross motor activity while looking for matching letters.
With your child, first match up each lower case coffee filter letter to the upper case magnetic letter.
You can spread the filters out to encourage visual scanning and involve movement in the activity, OR you can stack the coffee filters in a pile and one by one match up the letters. This technique requires the child to visually scan for the upper case magnet letters.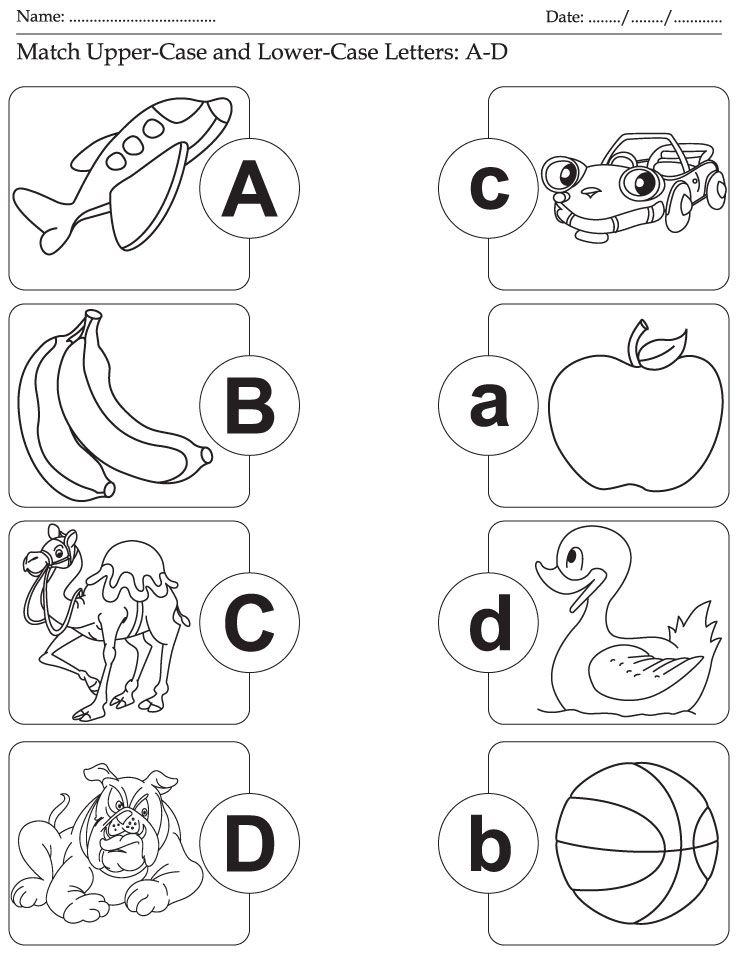
Try both ways for more upper/lower case letter practice!
We then wrapped the coffee filters around the magnets in a little bundle. There are so many games you can play with these upper and lower case letters:
- Match the same letter– match uppercase letters to uppercase letters and lowercase letters to lowercase letters.
- Alphabet matching with objects– Match an object that starts with the letter of the alphabet. Use small objects inside the coffee filter and match it to lowercase letters written in the coffee filter with uppercase magnet letters.
- Match the picture with the letter– Print off pictures of words that start with each letter of the alphabet. Then match the picture with letters of the alphabet using lowercase letters written on the filter and uppercase letters in magnetic letter form.
- Play a letter memory game– Hide letters around the room and challenge kids to find the letters in order to match the uppercase letter to the lowercase letters.

- Letter sound matching– Make a letter sound and challenge kids to find the letter that makes that sound.
- Letter Hide and Seek- Hide the bundled up letters around the room while your child hides his eyes. Send him off to find the letters and ask him to open the bundle and identify the letter.
- Letter Toss Activity- Toss the coffee filter bundles into a bucket or bin. Any letters that make it into the bin are winners!
- Name the letters- Unwrap the bundles and name the letters. Spread the coffee filters out around the room. Toss magnetic letters onto the matching lower case letter.
- Letter toss game- Toss a bean bag onto the coffee filters. The child can identify the lower case letter, then go to the pile of magnetic letters and find the matching upper case letter.
Can you think of any more ways to work on upper and lower case letter matching with coffee filters and magnetic letters?
Matching Big and Small Letters
The nice thing about this activity is that you can teach the concepts of big and small letters. When we say “big letters” and “small letters”, we are showing the concept of letters that touch the top and bottom lines, or the upper case letters.
When we say “big letters” and “small letters”, we are showing the concept of letters that touch the top and bottom lines, or the upper case letters.
And teaching children the difference between those big letters and the small letters which touch just the middle point are part of the visual discrimination process that is needed for handwriting on the lines, or line awareness skills.
You will enjoy more alphabet posts from our archives:
- Hand-eye coordination letter match
- Building letters with baked cotton swabs
Looking for more interactive letter activities to match uppercase and lowercase letters? The Letters! Fine Motor Kit is for you!
Letter Kit for fine motor, visual motor, and sensory motor play.This 100 page printable packet includes everything you need for hands-on letter learning and multisensory handwriting!
This digital and printable packet includes these multisensory handwriting and letter formation materials:
- A-Z Multisensory Writing Pages
- Alphabet Fine Motor Clip Cards
- Cut and place Fine Motor Mazes
- A-Z Cotton Swab Cards
- A-Z Pattern Block Cards
- Fine Motor Letter Geo-Cards
- A-Z Color and Cut Letter Memory Cards
- Color By Size Sheets
- A-Z Building Block Cards
- A-Z Play Dough Letter Formation Cards
- Graded Lines Box Writing Sheets
- Alphabet Roll and Write Sheets
- Pencil Control Letter Scan
- Color and Cut Puzzles
6 Upper and Lower Case Letter Matching Activities for Preschool
Letter matching activities are an excellent way for preschoolers to explore the alphabet. This is a very basic and easy upper and lowercase letter matching activity to reinforce matching letters of the alphabet in a fun way that preschoolers enjoy.
This is a very basic and easy upper and lowercase letter matching activity to reinforce matching letters of the alphabet in a fun way that preschoolers enjoy.
Use this FREE printable upper and lowercase letter matching activity to help solidify letter recognition in your preschool kids to help prepare them for reading.
Don’t forget to grab your FREE upper and lower case letter matching printable at the end of this post!
Free Printable Letter Matching Activity!
Young children are naturally fascinated by the letters of the alphabet. Have you ever been driving when your preschooler points to a stop sign and says, “Look, Mom! S! My name has s in it!”
Even children as young as two years may begin naming and recognizing letters, especially those in their names or those that are frequently found in their environment. (Although let me be clear that is it completely OK if they aren’t). Those are always their favorite letters.
Upper and Lowercase Letter Matching Activities for Preschool
Typically upper case letters are easier for children to learn because the straight lines and familiar “o” shapes are easier for children to recall than lower case letters which are often a mix of various shapes. Take the letter “g” for example. It has an “o” shape, a straight line, and then a hook for the tail. All those together is more difficult for a preschooler to learn than an upper case G which is mostly an “o” shape.
But soon, preschoolers are ready to begin matching upper and lower case letters, and letter matching activities like this one are a great place to start.
This free alphabet printable follows the same letter order as my preschool phonics curriculum. In my phonics lesson plans, preschoolers are introduced to letters in the order of frequency of use in the English language. That way, if you happen to have a preschooler who is developmentally ready to start decoding words, she will already have a handful of sounds that when combined make up a lot of words!
You might also like:
These are posts that teach children how to spell their names, or teach the letters of their name.
Letter Tile Names – A Name Recognition Activity
Mosaic Letters
Tape Resist Name and Phonics Booklets
Materials for Letter Matching Activities
My favorite letter matching activities are simple and quick to prepare. You only need a few items.
- FREE letter matching printable (found at the end of this post)
- Laminator and laminating pockets (optional)
- Glue sticks
- Tray (This helps preschoolers define their workspace).
Set-Up the Letter Matching Activity
Print out your uppercase and lowercase letter matching printable. (Remember, it’s free and at the end of this post). Cut them into letter tiles. (This is my all-time favorite paper cutter!)
I like to laminate my cards so that kids can use them over and over again, but you can also use glue sticks to glue the letters in place if you don’t want to go to the trouble of laminating the cards. And parents like it when their kiddos bring home a letter identification activity like this one.
Give each child a single grid, 15 corresponding letter tiles, and a glue stick all placed on a tray (skip the glue sticks if you’re doing this activity as a laminated activity).
My little disclaimers for the preparation
Don’t forget to grab your FREE upper and lower case letter matching printable at the end of this post!
To save time (and prevent potential accidents) I cut out the letter tiles in advance for my 3’s class. However, if doing this activity with a 4-5’s class, I would have had the students do their own cutting. (I keep all those kid scissors organized with this colorful caddy.)
Kindergarten teachers really appreciate it when preschoolers have good scissor control. (Need some tips? Check out this post!)
The Letter Matching Activity (with FREE Printable)
The object of the activity comes in two strides.
First, have your students identify each upper case letter on the grid. With the repetition of the four letters throughout the grid, identification of the letters ia solidified.
Next, show your students how to identify the lower case letters on the letter tiles and match with the upper case letters by gluing it on the grid.
To prevent random gluing, (as I knew some students would immediately gravitate to), I made an extra copy of the activity and modeled it for the students.
Once I modeled the concept with each letter, I asked the students to help me with the remaining letters. This is a traditional “I Do, Let’s Do it Together, You Do” teaching strategy). This ensured that all students knew exactly what to do when they received their own materials.
I offered this activity to my three-year-old preschool class. While I was expecting it to be difficult for some of my students, it was received rather well.
Surprisingly, our biggest challenge was not the matching of upper and lower case letters. Instead, it was learning to paste the letter tiles on the grid correctly.
You know, put the glue on the back of the tile, not the front, and put the tile right-side-up? Just the little things you wouldn’t think would be a challenge, haha!
More Letter Matching Activities
Don’t forget to grab your FREE upper and lower case letter matching printable at the end of this post!
And more ways to use this printable! After all, a printable is only a good one if it meets your needs, so here are some ways to scaffold the matching activity to different learners.
- Invite individual students to name specific letters as you point to them.
- Challenge your students to also think of something that begins with that letter. (Check out this letter/sound activity, too!)
- For younger learners, have the children sort their letters into piles before they begin gluing. Then they only have to worry about finding one kind of letter at a time. It’s less overwhelming that way.
- Use the letter tiles to spell out sight words or easy CVC words.
- When the grid is completed, invite your preschoolers to find small toys that begin with each letter and place them on the corresponding tiles.
Don’t forget to grab your free printable at the end of this post, and then keep reading for more letter matching activities!
You might also like
These are some of my most popular letter matching activities for preschoolers.
Rainbow Letters Race to the Top (FREE Printable)
I Spy Letters – A Letter Identification Activity for Preschoolers
Alphabet Circle Seek
The Benefits of Letter Matching
Thinking of objects that begin with the letter sound I was pointing to was difficult for the students.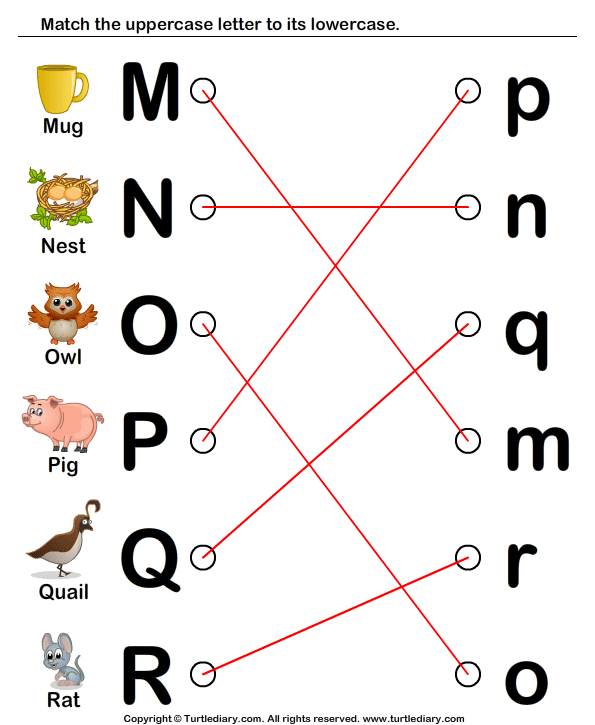 This is because it’s a skill that typically isn’t mastered until late preschool or not even until kindergarten for a lot of children. But this was a quick way for me to informally assess their letter/sound knowledge.
This is because it’s a skill that typically isn’t mastered until late preschool or not even until kindergarten for a lot of children. But this was a quick way for me to informally assess their letter/sound knowledge.
And, when I named a word, my three-year-old students were easily able to identify if that word began with the same letter to which I was pointing. This is just like our sound matching activity I threw together with just a set of animals toys and a lot like our flashcard practice.
This letter matching activity was an effective way to reinforce the letters we had been studying. It was an excellent review and the students were proud of their completed work and put it on display.
You might also like
ABC Letter Stack Game
Letter Sound Matching Activity
Initial Sound Object Matching
Grab Your FREE Letter Matching Printable
Remember, this FREE letter matching printable practices the alphabet in the same order I introduce them in my preschool literacy curriculum, which makes these perfect for each review week!
Don’t forget to keep reading for more letter matching activities!
Looking for More Letter Matching Activities?
You might enjoy these other letter matching printables. I like to use these as literacy centers.
I like to use these as literacy centers.
Want the Complete Preschool Curriculum?
You’ve got it!
The Complete Preschool Curriculum has everything you need to teach your preschoolers literacy and math in a fun and engaging way, without all the boring worksheets!
This resource includes 36 weeks of:
- oral language lessons
- phonological awareness lessons
- phonics lessons
- math lessons from all five disciplines of math (number sense, algebra, geometry, measurement, and data analysis)
- 10 weekly alphabet, letter formation, and beginning sounds centers
- 72 math centers to support all five disciplines of math
- editable preschool portfolio
- editable preschool portfolio monthly planning checklist
With detailed lesson plans offering an array of daily teaching options, you can cut your lesson planning down to a fraction of the time while still offering your preschoolers the best possible learning experience.
Click the image below to learn more!
Join thousands of others!
Subscribe to get our latest content by email.
We won't send you spam. Unsubscribe at any time. Powered by ConvertKitSarah Punkoney, MAT
I’m Sarah, an educator turned stay-at-home-mama of five! I’m the owner and creator of Stay At Home Educator, a website about intentional teaching and purposeful learning in the early childhood years. I’ve taught a range of levels, from preschool to college and a little bit of everything in between. Right now my focus is teaching my children and running a preschool from my home. Credentials include: Bachelors in Art, Masters in Curriculum and Instruction.
stayathomeeducator.com/
The truth about character case that programmers need to know / Habr
At the North Bay Python conference in 2018, I gave a talk on usernames. Most of the information in the report was compiled by me over 12 years of maintaining django-registration. This experience gave me a lot more knowledge than I had planned to have on how complex "simple" things can be.
Most of the information in the report was compiled by me over 12 years of maintaining django-registration. This experience gave me a lot more knowledge than I had planned to have on how complex "simple" things can be.
At the beginning of the report, I did mention that this would not be another exposé from the series of "misconceptions about X that programmers believe." You can find any number of such revelations. However, I don't like these articles. They list various things that are allegedly false, but very rarely explain why this is so, and what should be done instead. I suspect that people will simply read articles like this, congratulate themselves on this achievement, and then go on to find new and interesting ways to make mistakes not mentioned in these articles. It's because they didn't really understand the problems that these bugs give rise to. nine0005
Therefore, in my report, I tried to explain some of the problems as best as possible and explain how to solve them - I like this approach much more. One topic that I've only touched on in passing (it was just one slide and a couple of mentions on other slides) is the complexities that can be associated with character case. There is an official Correct Answer™ for the problem I was discussing - comparing case-insensitive identifiers - and in the talk I gave the best solution I know, using only the Python standard library. nine0003
One topic that I've only touched on in passing (it was just one slide and a couple of mentions on other slides) is the complexities that can be associated with character case. There is an official Correct Answer™ for the problem I was discussing - comparing case-insensitive identifiers - and in the talk I gave the best solution I know, using only the Python standard library. nine0003
However, I briefly mentioned the deeper complications with Unicode case, and I want to spend some time describing the details. This is interesting, and understanding this can help you make decisions when designing and writing code that processes text. Therefore, I offer you something opposite to the articles "misconceptions about X that programmers believe" - "the truth that programmers should know."
One more thing: Unicode is full of terminology. In this article, I will mainly use the definitions of "upper case" and "lower case" because the Unicode standard uses these terms. If you like other terms, like lowercase/uppercase letters, that's fine. Also, I will often use the term "symbol", which some may consider incorrect. Yes, in Unicode the concept of "character" isn't always what people expect, so it's often best to avoid it by using other terms. However, in this article, I will use the term as it is used in Unicode, to describe an abstract entity about which claims can be made. When it matters, I will use more specific terms like "code point" for clarification. nine0003
Also, I will often use the term "symbol", which some may consider incorrect. Yes, in Unicode the concept of "character" isn't always what people expect, so it's often best to avoid it by using other terms. However, in this article, I will use the term as it is used in Unicode, to describe an abstract entity about which claims can be made. When it matters, I will use more specific terms like "code point" for clarification. nine0003
There are more than two registers
Speakers of European languages are accustomed to using case in their languages to denote specific things. For example, in English [and Russian] we usually start sentences with an uppercase letter and most often continue with lowercase letters. Also, proper nouns start with uppercase letters, and many acronyms and abbreviations are written in uppercase.
And we usually think that there are only two registers. There is an "A" and there is an "a". One is in upper case, the other is in lower case, isn't it? nine0003
However, there are three cases in Unicode. There is an upper one, there is a lower one, and there is a title case [titlecase]. In English, this is how names are written. For example, Avengers: Infinity War. Usually, to do this, the first letter of each word is simply written in uppercase (and depending on different rules and styles, some words, such as articles, are not capitalized).
There is an upper one, there is a lower one, and there is a title case [titlecase]. In English, this is how names are written. For example, Avengers: Infinity War. Usually, to do this, the first letter of each word is simply written in uppercase (and depending on different rules and styles, some words, such as articles, are not capitalized).
The Unicode standard gives this example of a capital case character: U+01F2 LATIN CAPITAL LETTER D WITH SMALL Z. It looks like this: Dz. nine0003
Such characters are sometimes required to handle the negative consequences of one of the early design decisions of the Unicode standard: compatibility with existing text encodings in both directions. It would be more convenient for Unicode to compose sequences using the standard's character combination capabilities. However, in many systems already in existence, space has already been allocated for ready-made sequences. For example, in the ISO-8859-1 ("latin-1") standard, the character "é" has a prepared form numbered 0xe9. In Unicode, it would be preferable to write this letter with a separate "e" and an accent mark. But to ensure full compatibility in both directions with existing encodings such as latin-1, Unicode also assigns code points for predefined characters. For example, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
In Unicode, it would be preferable to write this letter with a separate "e" and an accent mark. But to ensure full compatibility in both directions with existing encodings such as latin-1, Unicode also assigns code points for predefined characters. For example, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
Although this character's code position is the same as its latin-1 byte value, don't rely on it. It is unlikely that the character encoding in Unicode will retain these positions. For example, in UTF-8 code position U+00E9written as the byte sequence 0xc3 0xa9.
And, of course, there are characters in already existing encodings that needed special treatment when using title case, which is why they were included in Unicode "as is". If you want to look at them, search your favorite Unicode database for characters in the Lt ("Letter, titlecase") category.
There are several ways to determine the register
The Unicode Standard (§4. 2) lists three different definitions of case. Perhaps the choice of one of the three makes your programming language for you; otherwise, your choice will depend on the specific purpose. Here are the definitions:
2) lists three different definitions of case. Perhaps the choice of one of the three makes your programming language for you; otherwise, your choice will depend on the specific purpose. Here are the definitions:
- A character is uppercase if it belongs to the category Lu ("Letter, uppercase"), and lowercase if it belongs to the category Ll ("Letter, lowercase"). The standard recognizes the limitations of this definition: each specific character has to be attributed to only one of the categories. Because of this, many characters that "should be" in upper or lower case will not meet this requirement because they belong to some other category. nine0033 The character is uppercase if it inherits the Uppercase property, and lowercase if it inherits the Lowercase property. It is a combination of defining one with other character properties, which may include case.
- A character is in uppercase if it does not change after a case mapping to uppercase has been applied to it.
 A character is in lowercase if, after applying a lowercase case mapping to it, it does not change. A rather general definition, however, it can also behave non-intuitively. nine0034
A character is in lowercase if, after applying a lowercase case mapping to it, it does not change. A rather general definition, however, it can also behave non-intuitively. nine0034
If you are working with a limited subset of characters (specifically, letters), then 1 definition may be enough for you. If your repertoire is broader - it includes characters that look like letters that are not letters, the 2nd definition may suit you. It is also recommended by the Unicode standard, §4.2:
Programmers manipulating Unicode strings should work with string functions such as isLowerCase (and its functional cousin toLowerCase) if they do not operate on character properties directly. nine0044The function mentioned here is defined in §3.13 of the Unicode Standard. Formally, the 3rd definition uses the functions isLowerCase and isUpperCase from §3.13, defined in terms of fixed positions in toLowerCase and toUpperCase, respectively.
If your programming language has functions for checking or converting the case of strings or individual characters, it's worth looking into which of the definitions mentioned are used in the implementation.
If you're wondering, Python's isupper() and islower() methods use the 2nd definition. nine0003
Cannot understand the case of a character by its appearance or name
By the appearance of many characters, you can understand what case they are in. For example, "A" is in upper case. This is clear from the name of the symbol: "LATIN CAPITAL LETTER A". However, sometimes this method does not work. Let's take the code position U+1D34. It looks like this: ᴴ. In Unicode, it's assigned a name: MODIFIER LETTER CAPITAL H. So it's in uppercase, right?
In fact, it inherits the Lowercase property, so by definition #2 it is in lower case, despite the fact that it visually resembles a capital H, and the name contains the word "CAPITAL". nine0003
Some characters have no case at all
Definition 135 in §3.13 of the Unicode Standard reads:
The character C is case-sensitive if and only if C has a Lowercase or Uppercase property, or the value of the General_Category parameter is Titlecase_Letter.
So a lot of Unicode characters - in fact, most of them - are caseless. Questions about their case do not make sense, and case changes do not affect them. However, we can get the answer to this question by definition #3. nine0003
Some characters behave as if they have multiple cases
It follows from this that if you use definition #3 and ask if an uncase character is in uppercase or lowercase, you will get the answer "yes".
The Unicode standard gives an example (Table 4-1, line 7) of the U+02BD MODIFIER LETTER REVERSED COMMA character (which looks like this: ʽ). It does not have the inherited Lowercase or Uppercase properties, and is not in the Lt category, so it is not case-sensitive. However, converting to upper case does not change it, and converting to lower case does not change it, so by definition 3 it answers yes to both questions: "Are you upper case?" and “are you lowercase?” nine0003
This seems like a lot of unnecessary confusion, but the point is that definition #3 works with any sequence of Unicode characters, and simplifies case conversion algorithms (caseless characters just turn into themselves).

Case dependent on context
You might think that if the Unicode case conversion tables cover all characters, then this conversion is simply a matter of finding the right place in the table. For example, the Unicode database says that U+0041 LATIN CAPITAL LETTER A will be U+0061 LATIN SMALL LETTER A in lowercase. Simple, right? nine0003
One example where this approach does not work is Greek. The character Σ—that is, U+03A3 GREEK CAPITAL LETTER SIGMA—is mapped to two different characters when converted to lowercase, depending on where it appears in the word. If it is at the end of a word, then it will be ς (U+03C2 GREEK SMALL LETTER FINAL SIGMA) in lower case. Anywhere else it will be σ (U+03C3 GREEK SMALL LETTER SIGMA).
This means that the register has no one-to-one or transitivity. Another example is ß (U+00DF LATIN SMALL LETTER SHARP S, or escet). In uppercase it would be "SS", although there is now another uppercase form of it (ẞ, U+1E9E LATIN CAPITAL LETTER SHARP S).
And converting "SS" to lowercase results in "ss", so (using Unicode terminology for case conversion): toLowerCase(toUpperCase(ß)) != ß.
Locale-specific case
Different languages have different case conversion rules. The most popular example: i (U+0069 LATIN SMALL LETTER I) and I (U+0049 LATIN CAPITAL LETTER I) are converted to each other in most locales - most, but not all. In the az and tr locales (Turkic), the uppercase i is İ (U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE) and the lowercase I is ı (U+0131 LATIN SMALL LETTER DOTLESS I). Sometimes the right notation really means the difference between life and death. nine0003
Unicode itself does not handle all possible case conversion rules for all locales. In the Unicode database, there are only general rules for converting all characters that are not dependent on the locale. Also there are special rules for some languages and compound forms - Lithuanian, Turkic languages, some features of Greek.
Everything else is not there. §3.13 of the standard mentions this and recommends introducing locale-specific conversion rules when necessary.
One example that will be familiar to English speakers is the title case of certain names. "o'brian" must be converted to "O'Brian" (not to "O'brian"). However, in this case, "it's" must be converted to "It's", and not to "It's". Another example that is not handled in Unicode is the Dutch character "ij", which, when converted to title case, must be converted to uppercase if it appears at the beginning of a word. Thus, a large bay in the Netherlands would be "IJsselmeer" in the title case, not "Ijsselmeer". Unicode has the characters IJ U+0132 LATIN CAPITAL LIGATURE IJ and ij U+0133 LATIN SMALL LIGATURE IJ if you need them. By default, case conversion converts them to each other (although Unicode normalization forms using compatibility equivalence will split them into two separate characters). nine0003
Case-insensitive comparison requires folded case conversion
Returning to the material presented in the report.
The complexity of dealing with case in Unicode means that case-insensitive comparison cannot be done using the standard lowercase or uppercase conversion functions found in many programming languages. For such comparisons, Unicode has the concept of case folding, and §3.13 of the standard defines the toCaseFold and isCaseFolded functions. nine0003
You might think that folding to folded case is like casting to lowercase, but it's not. The Unicode standard warns that a folded-case string will not necessarily be in lowercase. The Cherokee language is given as an example - there, in a line that is in folded case, characters in upper case will also come across.
One of the slides in my report implements the recommendations of Unicode Technical Report #36 in Python as fully as possible. NFKC is normalized and then the casefold() method (only available in Python 3+) is called on the resulting string. Even so, some edge cases fall out, and this is not exactly what is recommended for comparing identifiers.
First, the bad news: Python doesn't expose enough Unicode properties to filter out characters that aren't in XID_Start or XID_Continue, or characters that have the Default_Ignorable_Code_Point property. To my knowledge it does not support NFKC_Casefold mapping. It also lacks an easy way to use the modified NFKC UAX #31§5.1. nine0003
The good news is that most of these edge cases do not involve any real security risks posed by the characters in question. And case folding is in principle not defined as a normalization-preserving operation (hence the NFKC_Casefold mapping, which renormalizes to NFC after case folding). Generally, when comparing, you don't care if both strings are normalized after preprocessing. What you care about is whether the preprocessing is inconsistent, and whether it guarantees that only strings that "should" be different afterwards will be different afterwards. If this bothers you, you can manually renormalize after case addition. nine0003
Enough for now
This article, like the previous report, is not exhaustive, and it is hardly possible to fit all this material into a single post.
I hope this has been a useful overview of the complexities associated with this topic and that you will find enough starting points in it to look for further information. Therefore, in principle, you can stop here.
Wouldn't it be naïve for me to hope that other people would stop writing exposés from the series of "misconceptions about X that programmers believe" and start writing articles like "the truth programmers should know"? nine0003
python - At least one upper and lower case character and a digit
Question asked
Changed 4 years 4 months ago
Viewed 659 times
Let's say there is a random string. If it does not contain at least one upper or lower case character or digit, then correct it so that after correction there is at least one upper case character, at least one lower case character and any digit.
How can this be done without a lot of if's, but without changing the length of the string? nine0003
- python
- python-3.x
6
Well, I got four
if-and(in general, I could merge everything into one huge one, but this is somehow too much). Yes, this option is quite long, but still relevant. And here's why: numbers and letters of upper and lower case are added when needs , and not always (that is: if there is no number, then it is added). If it is needed for passwords, then this option will do. Only here atElse-sneeds to be finalized by adding random. Well, it's not that hard anymore.Code Highlights:
1.Adding a string
string
2.Checking for its length
3.Checking for the content of numbers
4.Checking for the content of small and capital letters , then there is a comparison with the long list of numbers contained in the string)
5.
Learn more