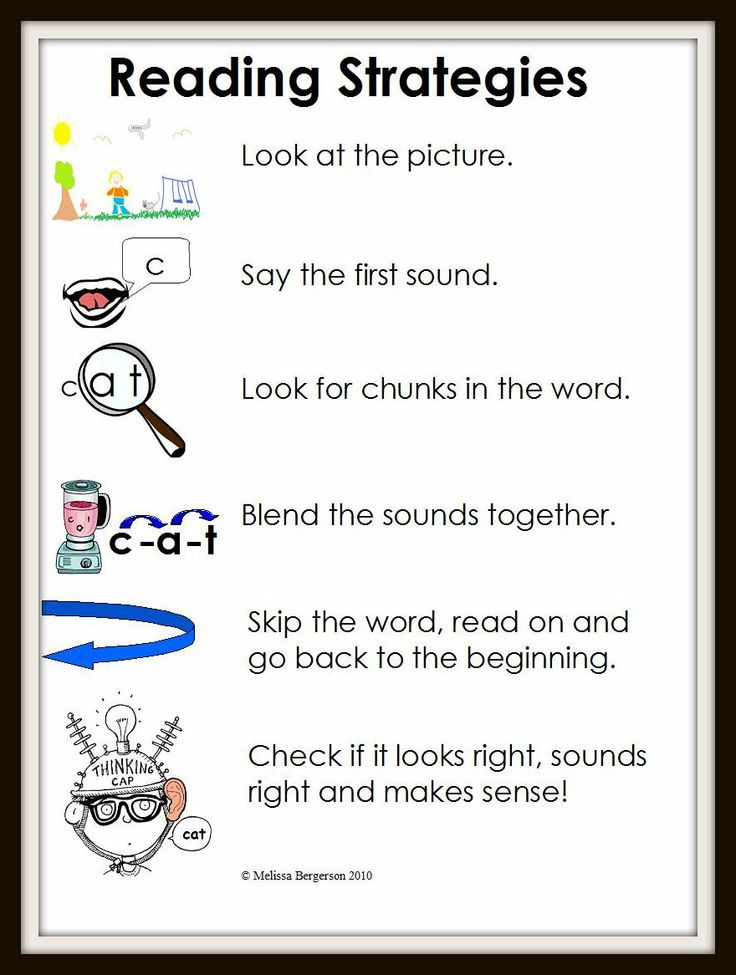
Segmenting a word
Developing the Skill of Segmenting
by Santina DiMauro
“I don’t know how to write!” said Isaac, unsure of how to spell the word ‘show’. As a young teacher, I assumed that once children were given the knowledge of letter sounds, the rest simply followed. The ‘rest’ involved the skills of blending for reading and segmenting for spelling. How wrong I was!
My understanding of these two skills gradually deepened and I explicitly taught students how to blend. While the majority were fluent and accurate when reading regular words, I – again – assumed that segmenting would naturally develop alongside. Wrong again! My experiences with teaching young students to read and write was a learning journey – not only for my students, but for me as well.
For most of our students, segmenting is not automatic. It is not ‘caught’ like one catches a cold; children need to be explicitly taught how to listen to sounds in words so that they can segment words into phonemes.
As a classroom teacher of 5- and 6-year-old students, I knew the benefit of the segmenting skill to spell unfamiliar words; especially as the phonological form of spelling requires segmenting as one of the strategies.
While blending and segmenting go hand-in-hand, this blog focuses on the skill of segmenting as one of the necessary skills for reading, writing and – in particular – spelling. You can also read my blog post on teaching children to blend.
What is Segmenting?
Segmenting is the ability to break up spoken words into their separate sounds. For example, as we spell the word ‘fish’, we segment it into its three sounds, also known as phonemes.
Oral segmenting is a phonemic awareness skill and a crucial building block of independent reading and writing. As children learn phonics, they begin to connect these phonemes with their visual representation (the alphabetic code).
Here is an excellent demonstration of oral segmenting.
When writing, children are encouraged to segment the words by listening to the sequential sounds in the words.
Research shows the importance of phonemic awareness in the early years, yet it is a step that is too often skipped. Many parents wonder why their child is struggling with spelling. My response is always to go back to the start: oral segmenting.
So, how can we help our children with segmenting? First, it’s important to remember that it isn’t an automatic skill and must be explicitly taught. When you’re teaching, try segmenting using these tips:
- Model the skill of segmenting by introducing a ‘robot voice’. I like to bring in a robot puppet or soft toy for my younger children. Say to the children: “When a robot talks, it talks very slowly.” The segmenting of a word mimics a robot voice.
- Segment words using your fingers or as I call it ‘Phoneme Fingers’. This allows children to attach a phoneme to the visual of a finger. They will then be able to ‘see’ how many phonemes are in the word.
 Next, ask the children to use their fingers as they segment words.
Next, ask the children to use their fingers as they segment words. - Practice! Practice! Practice! Chant often with lots of words and using phoneme fingers. Eventually, as children learn letter sounds, you can attach a magnetic letter for each phoneme to the board so that children can see the written word.
Segmenting Ideas for the Classroom
The following segmenting activities are my favourites. Give them a try and let me know what you think!
1. Blend and Go-Seek
Use a variety of objects or pictures (use our free Segmenting Picture Cards) together with the robot and robot voice.
Children listen to the teacher segmenting one of the objects. The teacher asks children to “Find the b-oo-k.”, for example. Children then blend to select the correct object.
While the children are blending with this activity, they are also listening to segmenting by the teacher. Encourage the children to echo the segmenting using the robot voice.
Encourage a child to take on the role of the robot and repeat the same activity. This activity is great for practising both blending and segmenting.
2. Phoneme Finger Count
This game can be played in pairs. One child takes a picture card (from our Segmenting Picture Cards) or word (use our Home Reader Cards) from the pile. The child says the spoken word for the picture or reads the word. The partner uses their phoneme fingers to segment the word.
3. Segment and Peg it
Children are provided with clothing pegs, pictures and dots under each picture. The number of dots represents the number of phonemes for that spoken word. Children segment the word as they point to each dot. They repeat the segmenting as they attach a peg to each dot.
Variation: Once children can orally blend and have been taught letter-sound knowledge, this activity can be done with magnetic letters or pegs with letters written on each peg.
4. I Spy
I Spy
This follows the same pattern as I Spy, however, instead of focusing on the first sound, the child segments the word for the others to blend.
E.g., “I spy with my little eyes something that I can see. It is a t-r-ee.”
5. Race Around the Phoneme Board
Download our Phoneme Board template for this activity. Separate children into small groups. A child starts by selecting a Segmenting Picture Card from the pile. The child segments the spoken word into phonemes and moves the counter based on the number of phonemes. The game continues in this manner until one child reaches the end of the racetrack.
For more segmenting activities, take a look at Shirley Houston’s blog post on oral blending and segmenting.
Making the leap from oral to segmenting with letters
Once children are confidently orally segmenting, you will then want to progress onto representing these sounds with letters in the written word. It’s tempting to announce “Grab your pencils – we are writing!” but think about how much cognitive load (the amount of information processing required to complete a learning task) you are burdening a child with.
On top of remembering the sound and which letter it’s associated with, by adding handwriting to the burden you are also expecting the emergent writer to juggle:
- Which hand does the pencil go in?
- Which way does the pencil go?
- How do I make a letter ‘c’?
- Where does the next letter go?
- How do I make a letter ‘a’?
- How do I make a letter ‘t’?
- How do I make the t longer than the other letters, where does it sit on the line and so on…
Compare that to simply selecting the correct magnetic letter from a group and moving it up the board.
Magnetic letters are the Early Years teacher’s best friend (get spelling without the handwriting burden) – and foe (they get lost/mixed up!). Once children’s handwriting is progressing and they are segmenting with relative ease, teachers can then introduce the added challenge of handwriting!
Spelling with Our Phonics Lessons
Phonics Hero’s no-prep Phonics Lessons give teachers over 3,700 words broken up into the five-step segmenting process.
Step 1 – Say the Word Using a bank of 3,700 picture supported words, children say the decodable word or listen to the audio. |
|
Step 2 – Stretch the Word This word is then stretched to emphasise each of the sounds. |
|
Step 3 – Count the Sounds Using our interactive sound buttons, children listen for and count the sounds. |
|
Step 4 – Represent the Sounds Next, write down the letter or letters which represent each of the sounds. |
|
Step 5 – Check It Looks Right Children compare their answer to the word. |
It gives you a bank of decodable words which use your lesson’s target phonemes and guides students through the 5-step process. Then – when children are ready – you can apply this learning to writing sentences with the Phonics Lessons sentence tool.
Then – when children are ready – you can apply this learning to writing sentences with the Phonics Lessons sentence tool.
You can grab a free 30-day trial by signing up for a Teacher Account.
Taught, Not Caught!
And so the journey into the wonderful world of writing begins!
The reading and writing journey of our children begins as they develop their phonemic awareness skills and are explicitly taught how to use their letter-sound knowledge to blend and segment. Reading a written piece from an emergent writer experimenting with print using segmenting as a spelling strategy always excites me as a teacher; a child can convey a lot when they have the basic phonics code under their belt!
The following piece was from one of my students who used a combination of the phonological form and visual form of spelling.
This piece still excites me because it highlights the child’s ability to segment words into phonemes.
Remember, segmenting must be taught NOT caught.
Author: Santina DiMauro
Santina is a teacher and phonics consultant. She has taught in schools for over 30 years and has trained teachers across Australia and Asia for 20 years in the area of literacy, in particular, synthetic phonics. If you are interested in Santina’s help as a literacy trainer for your school, drop the team an email at [email protected].Segmenting Makes Spelling MUCH Easier! Top Tips for Segmenting
by Marie Rippel
If your student is a beginning or struggling speller, one of the most important things you can do is teach him how to segment words. Knowing how to segment opens up a whole world of literacy. In fact, it’s surprising that this important spelling skill isn’t taught more widely, especially given how easy it is to teach.
This blog post explains what segmenting is, how to teach it, and how to apply it to your spelling lessons.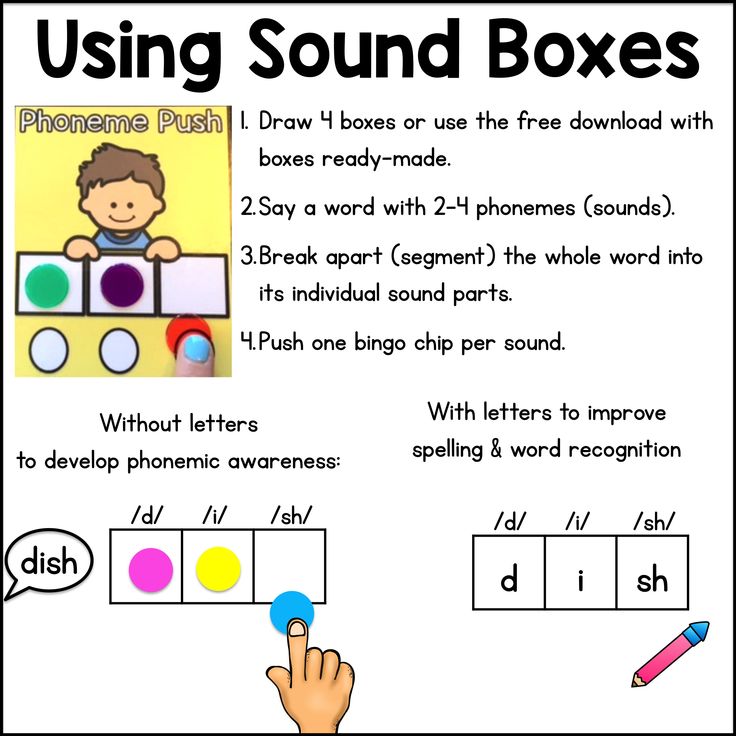
And be sure to grab the free printable so you can start teaching segmenting right away!
What Is Segmenting?
Segmenting is the ability to hear the individual sounds in words. It improves phonological awareness and long-term spelling ability.
Think of segmenting as the opposite of blending. When we speak, we blend sounds together to make a word. In segmenting, we take the individual sounds apart. For example, say the word ham aloud and listen for the three separate sounds:
In the word shrimp, there are five separate speech sounds. Even though there are six letters, the SH phonogram represents the single sound of /sh/.
How Do You Teach Segmenting?
A great way to start is with this “Breaking Words Apart” activity.
In this segmenting activity, your child will learn how to hear the sounds in short words. He’ll break apart two-sound words and three-sound words so that later he will be able to represent each sound with a written phonogram.
Segmenting can also be taught using tokens, coins, or squares of paper. You can see a demonstration in the video below.
You can see a demonstration in the video below.
Moving from Segmenting to Spelling
After your child is able to segment words into speech sounds using tokens, move on to segmenting words using letter tiles or the letter tiles app. It is a simple transition: the student still segments the word aloud, but instead of pulling down a token, he pulls down a letter tile for each sound.
There are three basic steps.
- Dictate the word, and then point to the tiles to indicate to the student that it is his turn to use the tiles.
- The student segments the word aloud, pulling down a tile for each sound.
- The student reads the word he just spelled. Reading the word enables the student to self-correct if he has made a mistake.
After segmenting words with the letter tiles, the student is ready to move on to spelling with paper and pencil. The student can eventually go straight from hearing a dictated word to writing on paper, segmenting the word in his head if necessary.
For More Help with Teaching Spelling
Find more great tips for teaching spelling in my free report, “20 Best Tips for Teaching Reading and Spelling.”
This report gives you a glimpse into the proven strategies we’ve used to help over 150,000 amazing children (and adults) learn to read and spell.
Text segmentation algorithms / Sudo Null IT News
Hello.
In the context of analyzing data from Twitter, the task of processing hashtags arose. It was necessary to take a hashtag and break it into separate words (#habratopic => habra topic). The task seemed primitive, but it turns out that I underestimated it. I had to go through several algorithms until I found what I needed.
This article can be considered a kind of chronology of solving the problem with an analysis of the advantages and disadvantages of each of the algorithms used. Therefore, if you are interested in this topic, I ask under cat.
It's worth noting that the task of splitting large text without spaces is very common in nlp. This is the definition of words in German "long words", which are, in fact, a concatenation of several ( geschwindigkeitsbegrenzung - speed limit ), the definition of words in Chinese writing, where space is rarely used ( 城市人的心爱宠物 - favorite pet of urban residents ) and so on. If in the second case with Chinese, the simplest algorithm considers one character per word and works quite well, then with German everything is much more complicated.
Algorithm 1. Minimum Matching
We go through the line and find the first word that matches. We save this word and repeat the procedure for the rest of the line. If no words match in the last line, we assume that no segmentation was found.
If no words match in the last line, we assume that no segmentation was found.
The algorithm is very fast (just what we need), but very stupid.
Example: niceday => nice day .
But, for niceweather segmentation will not be found, because after found word nice , the algorithm will determine we , then the article a , then the , and the word r is not in our dictionary.
Hm. What prevents instead of the first word that matches, taking the one with the maximum length?
Algorithm 2. Maximum Matching or Greedy
We do everything the same as in the first case, but always choose the word with the maximum length.
The algorithm is slower than the previous one, since we need to go from the end of the string to determine the word with the maximum length first. The speed will noticeably drop if you need to process very long lines, but since we have data from Twitter, we score on the problem. (In fact, if you select not the entire string, but the first n characters, where n is the maximum length of a word in the dictionary, then the speed will be on average the same as that of the first algorithm).
(In fact, if you select not the entire string, but the first n characters, where n is the maximum length of a word in the dictionary, then the speed will be on average the same as that of the first algorithm).
Example: niceweather => nice weather
But, for workingrass segmentation will not be found again. The first word our algorithm will match will be working , not work , and will also absorb the first letter in the word grass .
Maybe you need to combine both algorithms in some way? But what about the string niceweatherwhenworkingrass ? In general, we came to brute force. 9(N-1), where N is the size of the string. Next, we filter out those options that include substrings not from the dictionary. And the result will be correct. The main problem of the algorithm is speed.
Stop! And why generate everything, and then filter, if you can immediately generate what you need.
Algorithm 4. Clever Bruteforce
We modify our recursive function so that the recursive call occurs when we have already matched a word from the dictionary. In this case, the necessary segmentation is generated immediately. The algorithm is very fast, gives the desired result, and in general I thought that the problem was solved.
In this case, the necessary segmentation is generated immediately. The algorithm is very fast, gives the desired result, and in general I thought that the problem was solved.
Unfortunately, I missed the ambiguity. The fact is that the string segmentation is not unique and there are cases when there are dozens of equivalent partitions.
Example: expertsexchange => ( expert sex change , experts exchange )
There is a new subtask: how to choose the “right” segmentation?
I went through the options first, random, last, the one in which there are more words, the one in which there are fewer words and the results were, to put it mildly, not very good. Some smarter algorithm was needed. I can understand that0021 dwarfstealorcore is most likely “a dwarf steals orc ore”, and not “a dwarf steals or a core”, so the machine should understand. This is where machine learning algorithms come to the rescue.
Algorithm 5. Clever Bruteforce with ambiguity resolving (unigram model)
In order to teach our program to resolve ambiguities, we feed it a large text file (train-set), on which it builds a model. In our case, the unigram model is the frequency of each word in the text. Then for each of the candidates for segmentation, we calculate the probability as the product of the probabilities of each word in the candidate. Whoever has the most chance wins. Everything is simple.
In our case, the unigram model is the frequency of each word in the text. Then for each of the candidates for segmentation, we calculate the probability as the product of the probabilities of each word in the candidate. Whoever has the most chance wins. Everything is simple.
Example: input => in put
Suddenly? It's just that the word in and the word put are very common in the text, while the word input is only 1 time. The unigram model does not know anything about even the most primitive connection between words (for English speech, the combination of words in put is unlikely).
Algorithm 6. Clever Bruteforce with ambiguity resolving (bigram model)
Everything is the same, only now we are building a bigram model of the language. This means that we do not count the frequencies of words, but the frequencies of all pairs of words that go in a row. So, for example, the sentence " Kiev is the capital of Ukraine " will be divided into 5 bigrams: Kiev is, is the, the capital, capital of, of Ukraine . With this approach, the model "understands" at least a little which words can stand together, and which No. Now the bigram frequency in put in our model is zero. The algorithm shows good results. The weak point is the dictionary. Since the data on twitter is mostly informal, people's names, place names, etc., the dictionary screens out many suitable candidates. Therefore, one of the directions for the development of the algorithm is the rejection of the dictionary. Instead, you can use words from the train set. The second weak point is the train set. Since everything depends on it in ML algorithms, you need to have as much relevant data as possible. Here, as an option, you can use a train set from data obtained from the same twitter.
With this approach, the model "understands" at least a little which words can stand together, and which No. Now the bigram frequency in put in our model is zero. The algorithm shows good results. The weak point is the dictionary. Since the data on twitter is mostly informal, people's names, place names, etc., the dictionary screens out many suitable candidates. Therefore, one of the directions for the development of the algorithm is the rejection of the dictionary. Instead, you can use words from the train set. The second weak point is the train set. Since everything depends on it in ML algorithms, you need to have as much relevant data as possible. Here, as an option, you can use a train set from data obtained from the same twitter.
Links
Dictionary with more than 58 thousand words taken from here.
A file with more than a million words, found on the site of Peter Norvig, was chosen as a train set. There are many more interesting things there.
All this was implemented in Clojure. So for those who are interested, github.
Source text segmentation
- Segmentation rules
- Rule Priority
- Create a new rule
- A few simple examples
Translation memory programs work with text units called "segments". OmegaT segments text in two ways: by paragraph and by sentence (sentence segmentation is sometimes called "rule-based segmentation"). To set the type of segmentation, select the menu item "Project → Properties..." and check or uncheck the appropriate box. In some cases, paragraph segmentation can be useful, for example in creative translation, if the translator wants to change the order of sentences. In other cases, segmentation by offers will be preferable. If segmentation by offers is selected, its rules can be configured by selecting from the main menu "Options → Segmentation...".
In other cases, segmentation by offers will be preferable. If segmentation by offers is selected, its rules can be configured by selecting from the main menu "Options → Segmentation...".
For many languages, segmentation rules have already been developed, and most likely, they will be quite enough for you. On the other hand, in some cases, the ability to slightly change the segmentation rules to work with certain text can be very useful.
Caution: since text segmentation will be different after changing the rules, it is possible that the translation will have to start over. Previously translated segments will be marked as "no segments" in the project memory. If you change the segmentation settings while working with the project, the project will have to be reloaded for the changes to take effect.
In OmegaT, segmentation is carried out as follows:
- Structure level segmentation
-
OmegaT first scans the text to perform structure-level segmentation.
 At this stage, only information about the structure of the text is used for segmentation.
At this stage, only information about the structure of the text is used for segmentation. For example, for text files, segmentation can be performed on line breaks, empty lines, or not at all. Formatted files (ODF documents, HTML files, etc.) are segmented by paragraph tags. Translatable object attributes in XHTML or HTML can be extracted as separate segments.
- Sentence level segmentation
-
After segmenting the source file into structural fragments, OmegaT starts segmenting them by sentences.
Segmentation rules
The segmentation process can be described as follows: imagine a cursor moving through the text, passing one character at a time. For each cursor position in the given order, rules consisting of patterns are applied to and After , which check if the pattern matches To to text on the left and template After to the text to the right of the cursor. If any of the rules is triggered, then either the cursor moves to the next character without starting a new segment (the so-called exception rule), or a new segment is created at the current cursor position (the so-called break rule).
If any of the rules is triggered, then either the cursor moves to the next character without starting a new segment (the so-called exception rule), or a new segment is created at the current cursor position (the so-called break rule).
There are two types of rules:
- break rule
-
Divides the source text into segments. For example, the sentence " Was it worth it? Not sure ." should be divided into two segments. That is, you need to define a break rule for the character "?" followed by a space and a capitalized word. The Breaks/Exceptions checkbox determines whether the rule is a break (checked) or an exception (checked).
- exception rule
-
Specifies which part of the text should NOT be segmented.
 Despite the dot, the phrase Mrs. Dalloway do not need to split into two segments, so you need to define an exclusion rule for the string Mrs (and Mr, Dr, prof, etc.) with a dot on the right. To indicate that a rule is an exception, leave the Break/Exception checkbox unchecked.
Despite the dot, the phrase Mrs. Dalloway do not need to split into two segments, so you need to define an exclusion rule for the string Mrs (and Mr, Dr, prof, etc.) with a dot on the right. To indicate that a rule is an exception, leave the Break/Exception checkbox unchecked.
Standard break rules should be sufficient for most European languages and Japanese. However, it is possible for you to define new exception rules for some languages in order to get more meaningful and adequate segments.
Rule priority
All segmentation rule sets with a matching language pattern are applied in the given order, so that language-specific rules take precedence over standard rules. For example, rules for Canadian French (FR-CA) will take precedence over rules for French (FR.*) and default rules (. *). Accordingly, when translating from Canadian French, the rules for this language (if any) will be applied first, then the general rules for French and the standard rules.
*). Accordingly, when translating from Canadian French, the rules for this language (if any) will be applied first, then the general rules for French and the standard rules.
Create a new rule
Serious changes to the segmentation rules are usually not worth making, especially after the start of the project, but small changes (for example, adding recognition of a new abbreviation) can be very useful.
To extend or modify an existing set of rules, simply select it in the table. The rules of this set will appear at the bottom of the window.
To create a set of rules for a new language template, click the button Add at the top of the dialog box. An empty line will appear at the bottom of the table at the top of the window (you may have to move the scroll bar to find it). In the appropriate fields, enter the language name and template (see Appendix A, Languages - ISO 639 code list) language codes).