Abc capital and lowercase letters
Lowercase and Uppercase Letters: Definition and Meaning
The 26 letters in the English alphabet can take two forms: uppercase and lowercase. Each form serves a different function. Most of the letters you see in writing are lowercase.
Definition of Lowercase Letters
Lowercase letters are smaller and sometimes take a slightly different form than their uppercase counterparts.
Notice the L that starts the word Lowercase in the previous sentence. It’s larger than the other letters and looks different than the l in the word letters.
Lowercase letters are used more often than uppercase letters. They follow the first letter of a sentence or the first letter of a proper noun.
English Alphabet Lowercase Letters
These are the lowercase forms of each of the 26 letters in the English alphabet.
| a | b | c | d | e | f | g | h | i | j | k | l | m |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | o | p | q | r | s | t | u | v | w | x | y | z |
Definition of Uppercase Letters
Uppercase letters, also called capital letters, are used to start sentences and as the initial letter of a proper noun.
Uppercase letters are larger than their lowercase counterparts. Though most uppercase letters look similar to their lowercase partners, others take slightly different forms.
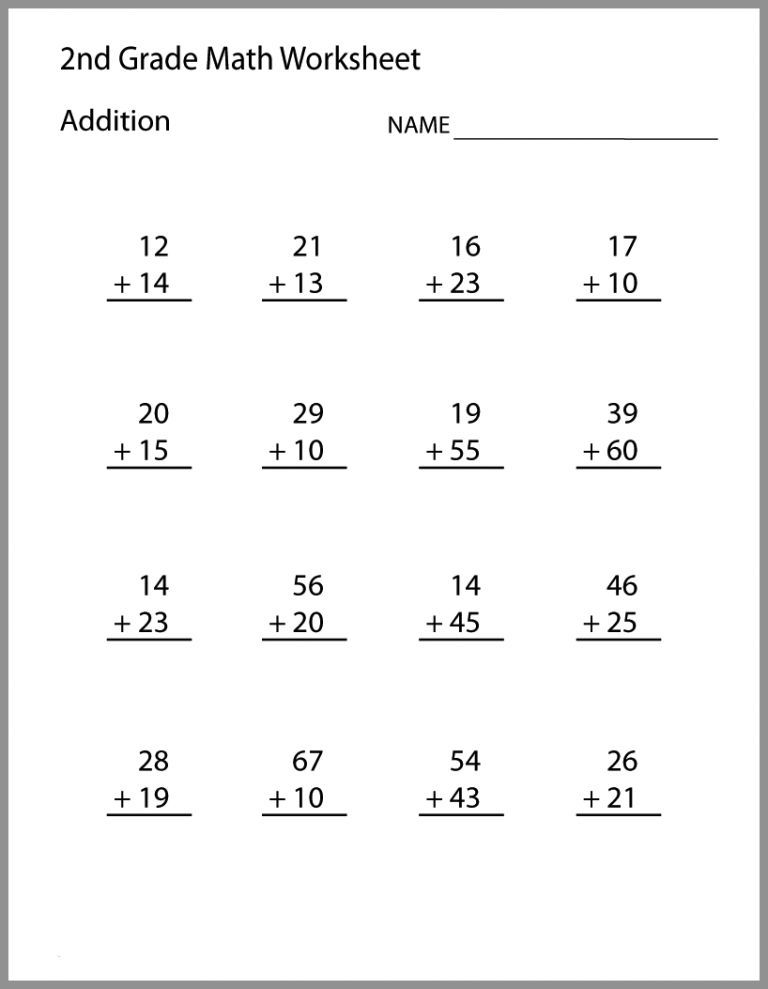
English Alphabet Uppercase (Capital) Letters
These are the uppercase or capital forms of the 26 letters in the English alphabet.
| A | B | C | D | E | F | G | H | I | J | K | L | M |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
When Should You Use Lowercase Letters?
It’s easier to explain the function of lowercase letters by saying what they don’t do. Lowercase letters do not start sentences and are not used as the initial letter of a proper noun.
They are used for all the remaining letters in sentences and following the first letter of proper nouns.
Most of the letters you write will be lowercase. A quick scan of this article shows that uppercase letters are used in specific circumstances and lowercase are used everywhere else!
In the first sentence of the paragraph above, Most of the letters you write will be lowercase., only the M in Most is an uppercase letter. All the others are lowercase.
Use Lowercase Letters with Common Nouns
Nouns are words that represent a person, place, thing, or idea. There are two types of nouns: common and proper.
Common nouns refer to a non-specific person, place, thing, or idea. They are generic terms. The chart below shows the common noun version of the proper nouns used above.
| Proper noun (capitalize first letter) | Common noun (lowercase letters) |
|---|---|
| Joanna | person |
| London | city |
| France | country |
| Tuesday | weekday |
| September | month |
Proper nouns refer to a specific person, place, thing, or idea. For example, the name of a particular person, city, country, day of the week, or month is a proper noun.
For example, the name of a particular person, city, country, day of the week, or month is a proper noun.
- Joanna
- London
- France
- Tuesday
- September
The initial letter of a proper noun is an uppercase letter. The rest are lowercase.
A grammar guru, style editor, and writing mentor in one package.
Try it for free!Sentence Examples with Proper and Common Nouns
These sentences contain both proper and common nouns (in bold). The proper nouns are capitalized, the common nouns contain only lowercase letters.
- After work, Sue met friends for dinner.
- The ancient poet Homer wrote The Odyssey and The Iliad.
- My favorite day of the week is Sunday, and my favorite month is July.
When Should You Use Uppercase Letters?
Most often, capital letters are used to start sentences and proper nouns, but those aren’t the only times.
This list explains other circumstances that require uppercase letters.
1. The first word of a quote that’s part of a complete sentence
When an embedded quote is also a complete sentence, the first word of that quote should be capitalized.
- Mary said, “We should go to the beach.”
2. Titles of literary or artistic works
Capitalize the first, last, and all other words in a title except conjunctions, articles, and prepositions of fewer than four letters. This is called “Title Case.” (Some style guides have even more specific guidelines, so always check!)
- To Kill a Mockingbird
- The Hunger Games
- The Fault in Our Stars
3. Professional titles preceding a person’s name
When a title such as “Dr.” or “President” precedes a specific person’s name, capitalize it.
- We will now hear from Dr. Jones, our keynote speaker.
- President Biden will give a speech later today.

Use lowercase letters if the title is used as a description or not followed by a specific name.
- The keynote speaker is Martin Jones, a doctor.
- I’m watching the president give a speech.
If you feel overwhelmed by the different rules of capitalization, remember that ProWritingAid is here to help!
It’s a thorough grammar checker (and more) that will detect errors in capitalization for you.
4. The pronoun “I”
You should always capitalize the pronoun “I.”
5. Acronyms and Initialisms
An acronym is a word formed by taking the first letter of each word of a compound term. Initialisms are similar abbreviations, except that the letters are pronounced individually rather than forming a new word.
- PIN is an acronym for personal identification number and is pronounced as the word “pin”
- FBI is an initialism for the Federal Bureau of Investigation and is pronounced as individual letters F-B-I
Some phrases are also abbreviated as initialisms:
- “Talk to you later” is TTYL
- “As soon as possible” is ASAP
Acronyms and initialisms should always appear in uppercase form.
6. When adding emphasis
Be careful with this use of uppercase letters!
When you put words or sentences in ALL CAPS, a practice often seen in texts or posts, you add emphasis to your words. Consider how that emphasis will be perceived.
ALL CAPS statements carry more aggression and intensity than lowercase words. That’s not always a bad thing.
For example, texting someone “HAPPY BIRTHDAY!” instead of “Happy birthday” is a way to convey excitement and show you really mean those good wishes.
Other times, ALL CAPS can sound accusatory, demeaning, or rude.
Remember that ALL CAPS in writing makes it seem as though the speaker is yelling. Keep that in mind before you press “send” on your uppercase text or post!
A Summary of Lowercase and Uppercase Letters
Lowercase letters are used for common nouns and for every letter after the initial letter of the first word of a sentence.
Uppercase letters are most often used at the start of sentences and as the first letter of proper nouns, though there are other times to use the capital letter form too.
Take your writing to the next level:
20 Editing Tips from Professional Writers
Whether you are writing a novel, essay, article, or email, good writing is an essential part of communicating your ideas.
This guide contains the 20 most important writing tips and techniques from a wide range of professional writers.
Should I Teacher Upper or Lower Case Letters First?
by Shirley Houston
I’ve been asked if you should teach upper or lower letters first, a few times recently, so in this month’s blog post I’ll address the debate and the impact of your choice on reading and spelling. I’ll also make recommendations for best teaching practice.
The Argument for Teaching Upper Case First
The ‘upper case first’ camp believe that ‘capitals’ are easier to identify, differentiate, and draw. They have a simpler visual structure than lower case letters. The only letters that are likely to cause orientation-based confusion are ‘M’ and ‘W’. The ‘capitals’ are predominantly formed with straight strokes (which are developmentally easier to draw than curves) and are all written on the lines on lined paper. Upper case letters are relatively common in environmental print e.g. street signs.
The ‘capitals’ are predominantly formed with straight strokes (which are developmentally easier to draw than curves) and are all written on the lines on lined paper. Upper case letters are relatively common in environmental print e.g. street signs.
Certainly, research (Worder & Boetcher, 1990) suggests that young children usually recognise more upper case letters than lower case, have a preference for upper case writing and write upper case letters better than lower case between the ages of 4 and 6. But is that because so many carers teach children to recognise and use upper case letters before they even start formal schooling?
The Argument for Teaching Lower Case First
I would argue that the practice of teaching upper case letters first, because they are considered ‘easier’, is more of a ‘societal tradition’ than sound educational practice. Upper case letters have minimal connection to early literacy skills; 95% of written text is in lower case letters. When children’s parents read books to them or when they attempt to read for themselves, children will not typically see text written in upper case. Visual recognition of lower case letters will be more helpful than that of upper case. This is why Phonics Hero teaches lower case letters in isolation and in isolated words (get access to free resources when you sign up for a Teacher Account).
Visual recognition of lower case letters will be more helpful than that of upper case. This is why Phonics Hero teaches lower case letters in isolation and in isolated words (get access to free resources when you sign up for a Teacher Account).
How to Link Sounds to the Lower Case Letters:
- It is important when talking about the lower case letters, to refer to the letter sounds: “When your eyes see this letter, your mouth says ___”.
- Rather than begin with the order of the alphabet, it makes sense to teach the letters that appear most frequently first. Phonics Hero’s games come in two orders of sounds, the first letters to be taught are either:
- When the first letter-sound correspondences are mastered (i.e. the alphabet sounds), other sounds represented by a letter can be introduced, e.g. the ‘e’ of bed vs the ‘e’ of ‘he’.
- If you choose the Playing with Sounds order, our no-prep Phonics Lessons can guide you through how to teach the sounds and their connection to lower case letters.
 See a guide tour of a ‘sounds lesson’ here:
See a guide tour of a ‘sounds lesson’ here:
When to Teach the Upper Case
Beginning of names and sentences
The upper case letters have a special, important job and should be taught in context. They show the start of a sentence or a name. ‘Capitals’ are best taught initially as the first letter in a child’s name. They are often the first and only capital letter in product names and shop signs so attention can also be drawn to them here. A name is usually only written completely in upper case when it has to be seen from a significant distance. Once the child is able to read or write a sentence, attention should be drawn to the need for an upper case letter at the beginning.
Remember, unlearning is harder than learning
If we initially teach a child to write words all in upper case, we have to later teach him that it was actually totally incorrect practice and try to get him to ‘unlearn’ it. Learning is much easier than ‘unlearning’. This is why many students continue to use capitals incorrectly in words. Many programs, including Phonics Hero, use lower case letters to teach letter-sound correspondences and upper case letters to teach alphabet letter names.
Learning is much easier than ‘unlearning’. This is why many students continue to use capitals incorrectly in words. Many programs, including Phonics Hero, use lower case letters to teach letter-sound correspondences and upper case letters to teach alphabet letter names.
This is because knowledge of the alphabet names does not help the child to ‘sound out’ words but will become useful when describing a spelling such as the ‘c’, ‘k’ or ‘ck’ spelling of the sound /k/.
Are upper case letters easier to write?
One argument people make for teaching upper case letters first is that they’re easier to form, but, actually, all of the types of hand movements are required by both upper and lower case. Upper case letters have more starting points and require more strokes/pencil pick ups, so are actually harder than lower case to draw. There are more diagonals in upper case letters, which is developmentally challenging. Consequently, it makes perfect sense to start writing with lower case letters. If cursive writing is being taught from the outset, it makes even more sense.
Consequently, it makes perfect sense to start writing with lower case letters. If cursive writing is being taught from the outset, it makes even more sense.
Linking Upper and Lower Case Letters
Logic suggests that we should build the essential foundations of sound and shape first, then add the ancillary concepts, such as capital letters and letter names. When you need to teach upper case letters for writing, explicitly teach them as ‘partners’, side by side. Provide a wall display and desk mat with both upper and lower case letters shown next to a relevant picture the child will recognise, like below. Many alphabet books, such as Dr Seuss’ ABC do this.
Multisensory ideas in making the link between lower and uppercase letters:
- Play board games such as Bingo for letter or letter-sound matching.
- Play partner matching games that involve movement, i.e. one half of class with upper case and one half with lower. Children must silently find their partner.

- Do plastic/magnetic letter sorts that involve the child feeling in 3D the shape of the letters.
- Get the child to make the letters with pipe cleaners, dough etc, saying the corresponding sound as each is completed.
- Have the child do letter/sound/lower case/upper case searches in mazes or text.
- As traditional keyboards show upper case but type lower case (unless Caps Lock is used), they can be used as tools to develop memory of the upper/lower case link.
- Have the child do air writing, letter tracing then copying on paper with the lower case and upper case alternated, drawing the upper case with gross movement in the air, in sand etc.
If you’re on board with teaching lower case letters first, the next question becomes: at what point do you teach the letter names and their capital letters? We’ve pinpointed the sweet point in our blog post: When to Teach Letter Names.
Author: Shirley Houston
With a Masters degree in Special Education, Shirley has been teaching children and training teachers in Australia for over 30 years. Working with children with learning difficulties, Shirley champions the importance of teaching phonics systematically and to mastery in mainstream classrooms. If you are interested in Shirley’s help as a literacy trainer for your school, drop the team an email on [email protected]0034 not are 1:1 display or reversible. Most of these operations are for display, not normalization.
Methods casefold (), upper(), lower(), capitalize(), title(), swapcase()
str.casefold() - creates a string that is suitable for the case of insensitive comparisons. It is more aggressive than str.lower and may change strings that are already lowercase or cause strings to grow in length and are not intended to be displayed.
"XßΣ".casefold() # 'xssσ' "XßΣ".lower() # 'xßς'
The transformations that occur within casefolding are defined by the Unicode Consortium in the CaseFolding.txt file on their website.
str.upper() - takes each character in a string and converts it to its uppercase equivalent, for example:
"This is a 'string'.".upper() # "THIS IS A 'STRING'."
str.lower() - does the opposite; it takes each character in a string and converts it to its lowercase equivalent:
"This IS a 'string'.".lower() # "this is a 'string'."
str.capitalize() - returns the capitalized version of the string, that is, it makes the first character uppercase and the rest lowercase:
"this Is A 'String'.".capitalize() # Capitalizes the first character and lowercases all others # "This is a 'string'."
str.title() - returns the title of the cased version of the string, i.e., each letter at the beginning of a word is made in upper case, and all the others are made in lower case:
"this Is a 'String'".title() # "This Is A 'String'"
str.swapcase() - str.swapcase returns a new string object with all lowercase characters swapped to uppercase and all uppercase characters swapped to lowercase:
" this iS A STRiNG".swapcase() #Swaps case of each character # "THIS Is a strIng"
Use as str class methods
Note that these methods can be called either on string objects (as shown above) or as a class method of str class (with an explicit call to str.upper etc.)
str.upper("This is a 'string'") # "THIS IS A 'STRING'" This is especially useful when applying one of these methods to many strings at once, say map functions.
map(str.upper,["These","are","some","'strings'"]) # ['THESE', 'ARE', 'SOME', "'STRINGS'"]
Split a string based on delimiter into a list of strings
str.split(sep=None, maxsplit=-1)
str. takes a string and returns a list of substrings of the original string. The behavior differs depending on whether the  split
split sep argument is provided or omitted.
If sep is not provided, or None is not present, then splitting occurs wherever there are spaces. However, leading and trailing spaces are ignored, and multiple consecutive whitespace characters are treated the same as a single whitespace character:
"This is a sentence.".split() # ['This', 'is', 'a', 'sentence.'] " This is a sentence. ".split() # ['This', 'is', 'a', 'sentence.'] " ".split() #[]
sep parameter can be used to define a delimiter string. The source string is split where the separator string occurs, and the separator itself is discarded. Multiple consecutive delimiters not are treated the same as a single delimiter, but rather cause empty strings to be generated.
"This is a sentence.".split('') # ['This', 'is', 'a', 'sentence. '] "Earth,Stars,Sun,Moon".split(',') # ['Earth', 'Stars', 'Sun', 'Moon'] " This is a sentence. ".split('') # ['', 'This', 'is', '', '', '', 'a', 'sentence.', '', ''] "This is a sentence.".split('e') # ['This is a s', 'nt', 'nc', '.'] "This is a sentence.".split('en') # ['This is a s', 't', 'ce.']
'] "Earth,Stars,Sun,Moon".split(',') # ['Earth', 'Stars', 'Sun', 'Moon'] " This is a sentence. ".split('') # ['', 'This', 'is', '', '', '', 'a', 'sentence.', '', ''] "This is a sentence.".split('e') # ['This is a s', 'nt', 'nc', '.'] "This is a sentence.".split('en') # ['This is a s', 't', 'ce.'] The default is to split by every occurrence of a delimiter, however the maxsplit parameter limits the number of splits that occur. The default value -1 means there is no limit:
"This is a sentence.".split('e', maxsplit=0) # ['This is a sentence.'] "This is a sentence.".split('e', maxsplit=1) # ['This is a s', 'ntence.'] "This is a sentence.".split('e', maxsplit=2) # ['This is a s', 'nt', 'nce.'] "This is a sentence.".split('e', maxsplit=-1) # ['This is a s', 'nt', 'nc', '.'] str.rsplit(sep=None, maxsplit=-1)
str.rsplit ("right split") is different from str.split ("left split") when maxsplit is specified. Splitting starts at the end of the string, not at the beginning:
Splitting starts at the end of the string, not at the beginning:
"This is a sentence.".rsplit('e', maxsplit=1) # ['This is a sentenc', '.'] "This is a sentence.".rsplit('e', maxsplit=2) # ['This is a sent', 'nc', '.'] Note: Python defines a maximum number of splits are performed, while most other programming languages specify a maximum number of substrings created. This can create confusion when porting or comparing code.
Replace all occurrences of one substring with another substring
Python's str type also has a method for replacing occurrences of one substring with another substring in a given string. For more complex cases, re.sub can be used. str.replace(old, new[ count]) :
str.replace takes two arguments, old and new , containing the old substring to be replaced with the new substring. The optional argument
The optional argument count specifies the number of replacements to be:
For example, in order to replace 'foo' with 'spam' in the next line, we can call str.replace with old = 'foo ' and new = 'spam' :
"Make sure to foo your sentence.".replace('foo', 'spam') # "Make sure to spam your sentence." If the given string contains multiple examples that match the old argument, all occurrences are replaced by the value supplied in new :
"It can foo multiple examples of foo if you want.".replace('foo', 'spam') # "It can spam multiple examples of spam if you want." unless of course we supply a value for count . In this case, count entries are going to be replaced:
"""It can foo multiple examples of foo if you want, \ or you can limit the foo with the third argument.""".replace('foo', 'spam', 1) # 'It can spam multiple examples of foo if you want, or you can limit the foo with the third argument.'
str.format and f-strings: format values to string
Python provides string interpolation and formatting functionality via str.format function introduced in version 2.6 and F-strings introduced in version 3.6.
The following variables are given:
i = 10 f = 1.5 s = "foo" l = ['a', 1, 2] d = {'a': 1, 2: 'foo'} Let's see different formatting of the string
"{} {} {} {} {}". format(i, f, s, l, d) str.format("{} {} {} {} {}", i, f, s, l, d) "{0} {1} {2} {3} {4}". format(i, f, s, l, d) "{0:d} {1:0.1f} {2} {3!r} {4!r}".format(i, f, s, l, d) "{i:d} {f:0.1f} {s} {l!r} {d!r}".format(i=i, f=f, s=s, l=l, d=d) All statements above are equivalent "10 1.5 foo ['a', 1, 2] {'a': 1, 2: 'foo'}"
f"{i} {f} {s} { l}{d}" f"{i:d} {f:0.1f} {s} {l!r} {d!r}" For reference, Python also supports C-style classifiers for string formatting. The examples below are equivalent to those above, but the
The examples below are equivalent to those above, but the str.format variants are preferred due to advantages in flexibility, notation consistency, and extensibility:
"%d %0.1f %s %r %r" % (i , f, s, l, d) "%(i)d %(f)0.1f %(s)s %(l)r %(d)r" % dict(i=i, f=f, s=s, l=l, d=d )
Parentheses are used for interpolation in str.format can also be numbered to reduce duplication when formatting strings. For example, the following is equivalent to:
"I am from {}. I love cupcakes from {}!".format("Australia", "Australia") #"I am from Australia. I love cupcakes from Australia!" "I am from {0}. I love cupcakes from {0}!".format("Australia") #"I am from Australia. I love cupcakes from Australia!" While the official python documentation is thorough as usual, pyformat.info has a large set of examples with detailed explanations.
In addition, { and } characters can be escaped with double brackets:
"{{'{}': {}, '{}': {}}}". format("a" , 5, "b", 6) # "{'a': 5, 'b': 6}"
format("a" , 5, "b", 6) # "{'a': 5, 'b': 6}" See Format string for more information. str.format() was proposed in PEP 3101 and F-strings in PEP 498 .
Counting the number of occurrences of a substring in a string
One method is available for counting the number of occurrences of a substring in another string, str.count . str.count(sub[ start[ end]])
str.count returns int indicating the number of non-overlapping occurrences of substrings sub in another string. The optional arguments start and end indicate the start and end at which the search will occur. The default start = 0 and end = len(str) means the whole string will be searched:
s = "She sells seashells by the seashore." s.count("sh") #2 s.count("se") #3 s.count("sea") #2 s.count("seashells") # 1 By giving different values for start , end , we can get a more localized lookup and count, for example if start equals 13 call to:
s.count("sea", start) # 1
is equivalent to:
t = s[start:] t.count("sea") # 1 Check the start and end characters of a string
In order to check the start and end of a given string in Python, you can use the str.startswith() methods and str.endswith() . str.startswith(prefix[ start[ end]])
As the name implies, str.startswith is used to check if the given string starts with the given characters in prefix .
s = "This is a test string" s.startswith("T") # True s.startswith("Thi") # True s.startswith("thi") # False The optional arguments start and end specify the start and end points from which testing will start and end. In the following example, by specifying an initial value of 2 our string will be viewed from position 2 and then:
s.startswith("is", 2) # True This gives True , since s[2] == 'i' and s[3] == 's' .
You can also use tuple to check if it starts with any of the stringset
s.startswith(('This', 'That')) # True s.startswith(('ab', 'bc')) # False str.endswith(prefix[ start[ end]]) - exactly like str.startswith with the only difference being that it looks for ending characters and not starting characters. For example, to check if a string ends in a full stop, you could write:
s = "this ends in a full stop." s.endswith('.') # True s.endswith('!') # False as with startswith more than one character can be used to end a sequence:
s.endswith('stop.') # True s.endswith('Stop.') # False You can also use tuple to check if it ends with any of the stringset
s.endswith(('.', 'something')) # True s.endswith(('ab', 'bc')) # False Testing what a string consists of
Python's str type also has a number of methods that can be used to evaluate the contents of a string. These are
These are str.isalpha , str.isdigit , str.isalnum , str.isspace . Capitalization can be checked from str.isupper , str.islower and str.istitle . str.isalpha
str.isalpha takes no arguments and returns True if all characters in the given string are alphabetic, for example:
"Hello World".isalpha() # contains a space # False "Hello2World".isalpha() # contains a number # False "HelloWorld!".isalpha() # contains punctuation # False "HelloWorld".isalpha() # True
In the edge case, an empty string evaluates to False when using "".isalpha() . str.isupper , str.islower , str.istitle
These methods check for the use of capital letters in a given string.
str.isupper is a method that returns True if all characters in the given string are uppercase and False otherwise.
"HeLLO WORLD".isupper() # False "HELLO WORLD".isupper() # True "".isupper() # False
On the other hand, str.islower is a method that returns True if all characters in the given string are lowercase and False otherwise.
"Hello world".islower() # False "hello world".islower() # True "".islower() # False
str.istitle returns True if the given title string is cased; that is, each word begins with an uppercase letter followed by lowercase letters.
"hello world".istitle() # False "Hello world".istitle() # False "Hello World".istitle() # True "".istitle() False
Methods str.isdecimal , str.isdigit , str.isnumeric
str.isdecimal returns a string whether a sequence of decimal digits is suitable for representing a decimal number.
str.isdigit includes a digit not in a form suitable for representing a decimal number, such as superscript digits.
str.isnumeric includes any numeric values, even if not numeric, such as values outside the range 0-9.
isdecimal isdigit isnumeric 12345 True True True ១2҃໔5 True True True ①²³🄅₅ False True True ⑩⒓ False False True Five False False False
Byte strings ( bytes in Python 3, str in Python 2), only supports isdigit , which only checks for basic ASCII digits.
Like str.isalpha empty string evaluates to False . str.isalnum
This is a combination of str.isalpha and str.isnumeric , in particular it has the value True if all the characters in the given string are alphabetic - numeric, then they are of alphabetic or numeric characters:
"Hello2World".isalnum() # True "HelloWorld".isalnum() # True "2022".isalnum() # True "Hello World".isalnum() # contains whitespace # False
str. - Returns  isspace
isspace True if the string contains only whitespace characters.
"\t\r\n".isspace() # True " ".isspace() # True
Sometimes the string looks "empty" but we don't know if it is because it contains only spaces or no characters at all
"".isspace() # False
To cover this case we need an additional test
my_str = '' my_str.isspace() # False my_str.isspace() or not my_str #True
But the shortest way to check if a string is empty or contains only whitespace characters is to use strip (with no arguments it strips all leading and trailing whitespace characters)
not my_str.strip() # True
str.translate: translate characters in string
Python supports a translate method on type str that allows you to specify a translation table (used for replacement) as well as any characters that need to be removed in the process.
str. - parameter  translate(table[ deletechars])
translate(table[ deletechars]) table is a lookup table that defines the mapping from one character to another. deletechars is a list of characters to be removed from the string. The
maketrans method ( str.maketrans in Python 3 and string.maketrans in Python 2) allows you to create a translation table.
translation_table = str.maketrans("aeiou", "12345") my_string = "This is a string!" translated = my_string.translate(translation_table) # 'Th4s 3s 1 str3ng!' 9The 0047 translate method returns a string that is a translated copy of the original string. You can set table argument to None if required just to remove characters.
'this syntax is very useful'.translate(None, 'aeiou') 'ths syntx s vry sfl'
Remove unwanted leading/ending characters from a string
Three methods provided that offer the ability to strip leading and trailing characters from a string: str. strip
strip , str.rstrip , and str.lstrip . All three methods have the same signature, and all three return a new string object with unwanted characters removed. str.strip([chars])
str.strip acts on the given string and removes (strips) or any leading trailing characters contained in the argument chars ; if chars is not included or there is no None , all whitespace characters are removed by default. For example:
"a line with leading and trailing space".strip() # 'a line with leading and trailing space'
If chars are supplied, all characters contained in it are removed from the string that is returned. For example:
">>> a Python prompt".strip('>') # strips the '>' character and the space after it #'a Python prompt' str.rstrip([chars]) and str.lstrip([chars]) - These methods have the same semantics and arguments since str. strip()
strip() , their difference lies in the direction they start from. str.rstrip() starts from the end of the string while str.lstrip() splits from the beginning of the string.
For example, using str.rstrip :
" spacious string ".rstrip() # ' spacious string'
While using str.lstrip :
" spacious string ".rstrip() # 'spacious string' " spacious string ".rstrip().lstrip() # 'spacious string'
Case-insensitive string comparison
Case-insensitive string comparison seems trivial, but it's not. This section only covers Unicode strings (the default in Python 3). Note that Python 2 may have minor drawbacks compared to Python 3 - the later handling of unicode is much more complete.
The first thing to note is that unicode case-removal conversions are not trivial. There is a text for which text.lower() != text.upper().lower() , For example, "ß" :
>>> "ß". lower() 'ß' >>> "ß".upper().lower() 'ss'
lower() 'ß' >>> "ß".upper().lower() 'ss'
But suppose you wanted to case insensitively compare "BUSSE" and "Buße" . Hell, you probably also want to compare "BUSSE" and "BUẞE" equal - it's a new form capital. The recommended way is to use casefold :
help(str.casefold) """ Help on method_descriptor: casefold(self, /) Return a version of the string suitable for caseless comparisons """
Don't just use lower . If casefold is not available, doing .upper().lower() helps (but only a little).
Then you should consider accents. If the renderer font is fine, you probably think "ê" == "ê" - but it's not:
"ê" == "ê" # False
This is because they are actually
unicodedata [unicodedata.name(char) for char in "ê"] # ['LATIN SMALL LETTER E WITH CIRCUMFLEX'] [unicodedata.name(char) for char in "ê"] # ['LATIN SMALL LETTER E', 'COMBINING CIRCUMFLEX ACCENT'
The easiest way to deal with this is unicodedata. normalize
normalize . You probably want to use NFKD normalization, but feel free to check the documentation. Then one
unicodedata.normalize("NFKD", "ê") == unicodedata.normalize("NFKD", "ê") #True To finish, this is expressed in functions here:
import unicodedata def normalize_caseless(text): return unicodedata.normalize("NFKD", text.casefold()) def caseless_equal(left, right): return normalize_caseless(left) == normalize_caseless(right) Join a list of strings into a single string
A string can be used as a delimiter to join a list of strings together into a single string using the join() method. For example, you can create a string where each element in the list is separated by a space.
" ".join(["once","upon","a","time"]) # "once upon a time"
In the following example, string elements are separated by three dashes.
"---".join(["once", "upon", "a", "time"]) # "once---upon---a---time"
Useful string module constants
Python string module provides constants for operations involving strings. To use them, import
To use them, import string module:
import string
Combination ascii_lowercase and ascii_uppercase :
string.ascii_letters # 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
string.ascii_lowercase :
Contains all ASCII lowercase characters:
string.ascii_lowercase # 'abcdefghijklmnopqrstuvwxyz'
string.ascii_uppercase :
Contains all uppercase ASCII characters:
string.ascii_uppercase # 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
string.digits - contains all decimal digits:
string.digits # '0123456789'
string.hexdigits - contains all hex characters:
string.hexdigits # '0123456789abcdefABCDEF'
string.octaldigits - contains all octal characters:
string.octaldigits # '01234567'
string.punctuation - contains all characters that are considered punctuation in C 9_`{|}~'
string. - contains all ASCII characters that are considered whitespace:  whitespace
whitespace
string.whitespace # ' \t\n\r\x0b\x0c'
In script mode, print(string.whitespace) will print the actual characters, use str to get the above string returned.
A string can be reversed using the built-in function While using Python provides functions for line alignment, allowing you to pad text to make it easier to align different lines. Here is an example of The content of files and network messages can be encoded characters. They often need to be converted to unicode to display correctly. In Python 3, you may need to convert byte arrays (called "byte literals") to Unicode character strings. The default is now a Unicode string, and byte string literals must now be entered as string.printable - contains all characters that are considered printable; combination of string.digits , string.ascii_letters 9_`{|}~ \t\n\r\x0b\x0c' Reversing a string (reverse)
reversed() , which takes a string and returns an iterator in reverse order. reversed('hello') # reversed() can be wrapped in a ''.join() call to make a string from an iterator. ''.join(reversed('hello')) # 'olleh' reversed() may be more readable for uninitiated Python users, using advanced slicing in increments of -1 is faster and more concise.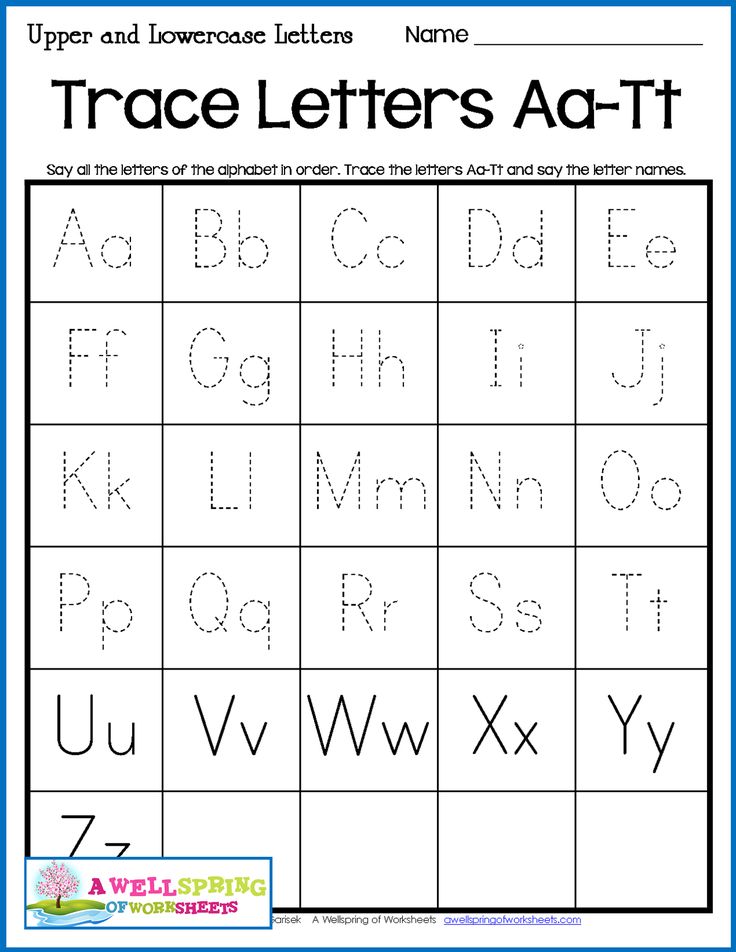 Here, try implementing this as a function:
Here, try implementing this as a function: def reversed_string(main_string): return main_string[::-1] reversed_string('hello') # 'olleh' Line alignment
str.ljust and str.rjust : interstates_lengths = { 5: (1381, 2222), 19:(63, 102), 40: (2555, 4112), 93: (189.305) } for road, length in interstates_lengths.items(): miles,kms = length print('{} -> {} mi.({} km.)'.format(str(road).rjust(4), str(miles).ljust(4), str(kms).ljust(4) )) # 5 -> 1381 mi. (2222 km.) # 19 -> 63 mi. (102 km.) # 40 -> 2555 mi. (4112 km.) # 93 -> 189 mi. (305 km.) ljust and rjust are very similar. Both have a width parameter and an optional fillchar parameter. Any string generated by these functions is at least as long as the width parameter that was passed into the function. If the string is longer than
If the string is longer than width alread, it is not truncated. fillchar argument that defaults to the space character ' ' must be a single character, not a multicharacter string. ljust end-of-line pad function it is called on from fillchar until width character length. rjust function to pad the beginning of a line in a similar manner. Thus, l and r in the names of these functions refer to the side that the source string, and not fillchar , is located in the output string. Convert between str or byte data and unicode characters
b'' , b"" , etc. Byte literal will return
Byte literal will return True in isinstance(some_val, byte) , assuming some_val to be a string that can be encoded in bytes. # You get from file or network "© abc" encoded in UTF-8 s = b'\xc2\xa9 abc' # s is a byte array, not characters # In Python 3, the default string literal is Unicode; byte array literals need a leading b s[0] # b'\xc2' - meaningless byte (without context such as an encoding) type(s) # bytes - now that byte arrays are explicit, Python can show that. u = s.decode('utf-8') # '© abc' on a Unicode terminal # bytes.decode converts a byte array to a string (which would be Unicode in Python 3) u[0] # '\u00a9' - Unicode Character 'COPYRIGHT SIGN' (U+00A9) '©' type(u) # str # The default string literal in Python 3 is UTF-8 Unicode. u.encode('utf-8') # b'\xc2\xa9 abc' # str.encode produces a byte array, showing the ASCII-range bytes as non-replaceable characters.
Learn more