Lowercase vs uppercase
Lowercase and Uppercase Letters: Definition and Meaning
The 26 letters in the English alphabet can take two forms: uppercase and lowercase. Each form serves a different function. Most of the letters you see in writing are lowercase.
Definition of Lowercase Letters
Lowercase letters are smaller and sometimes take a slightly different form than their uppercase counterparts.
Notice the L that starts the word Lowercase in the previous sentence. It’s larger than the other letters and looks different than the l in the word letters.
Lowercase letters are used more often than uppercase letters. They follow the first letter of a sentence or the first letter of a proper noun.
English Alphabet Lowercase Letters
These are the lowercase forms of each of the 26 letters in the English alphabet.
| a | b | c | d | e | f | g | h | i | j | k | l | m |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | o | p | q | r | s | t | u | v | w | x | y | z |
Definition of Uppercase Letters
Uppercase letters, also called capital letters, are used to start sentences and as the initial letter of a proper noun.
Uppercase letters are larger than their lowercase counterparts. Though most uppercase letters look similar to their lowercase partners, others take slightly different forms.
English Alphabet Uppercase (Capital) Letters
These are the uppercase or capital forms of the 26 letters in the English alphabet.
| A | B | C | D | E | F | G | H | I | J | K | L | M |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
When Should You Use Lowercase Letters?
It’s easier to explain the function of lowercase letters by saying what they don’t do. Lowercase letters do not start sentences and are not used as the initial letter of a proper noun.
They are used for all the remaining letters in sentences and following the first letter of proper nouns.
Most of the letters you write will be lowercase. A quick scan of this article shows that uppercase letters are used in specific circumstances and lowercase are used everywhere else!
In the first sentence of the paragraph above, Most of the letters you write will be lowercase., only the M in Most is an uppercase letter. All the others are lowercase.
Use Lowercase Letters with Common Nouns
Nouns are words that represent a person, place, thing, or idea. There are two types of nouns: common and proper.
Common nouns refer to a non-specific person, place, thing, or idea. They are generic terms. The chart below shows the common noun version of the proper nouns used above.
| Proper noun (capitalize first letter) | Common noun (lowercase letters) |
|---|---|
| Joanna | person |
| London | city |
| France | country |
| Tuesday | weekday |
| September | month |
Proper nouns refer to a specific person, place, thing, or idea. For example, the name of a particular person, city, country, day of the week, or month is a proper noun.
For example, the name of a particular person, city, country, day of the week, or month is a proper noun.
- Joanna
- London
- France
- Tuesday
- September
The initial letter of a proper noun is an uppercase letter. The rest are lowercase.
A grammar guru, style editor, and writing mentor in one package.
Try it for free!Sentence Examples with Proper and Common Nouns
These sentences contain both proper and common nouns (in bold). The proper nouns are capitalized, the common nouns contain only lowercase letters.
- After work, Sue met friends for dinner.
- The ancient poet Homer wrote The Odyssey and The Iliad.
- My favorite day of the week is Sunday, and my favorite month is July.
When Should You Use Uppercase Letters?
Most often, capital letters are used to start sentences and proper nouns, but those aren’t the only times.
This list explains other circumstances that require uppercase letters.
1. The first word of a quote that’s part of a complete sentence
When an embedded quote is also a complete sentence, the first word of that quote should be capitalized.
- Mary said, “We should go to the beach.”
2. Titles of literary or artistic works
Capitalize the first, last, and all other words in a title except conjunctions, articles, and prepositions of fewer than four letters. This is called “Title Case.” (Some style guides have even more specific guidelines, so always check!)
- To Kill a Mockingbird
- The Hunger Games
- The Fault in Our Stars
3. Professional titles preceding a person’s name
When a title such as “Dr.” or “President” precedes a specific person’s name, capitalize it.
- We will now hear from Dr. Jones, our keynote speaker.
- President Biden will give a speech later today.

Use lowercase letters if the title is used as a description or not followed by a specific name.
- The keynote speaker is Martin Jones, a doctor.
- I’m watching the president give a speech.
If you feel overwhelmed by the different rules of capitalization, remember that ProWritingAid is here to help!
It’s a thorough grammar checker (and more) that will detect errors in capitalization for you.
4. The pronoun “I”
You should always capitalize the pronoun “I.”
5. Acronyms and Initialisms
An acronym is a word formed by taking the first letter of each word of a compound term. Initialisms are similar abbreviations, except that the letters are pronounced individually rather than forming a new word.
- PIN is an acronym for personal identification number and is pronounced as the word “pin”
- FBI is an initialism for the Federal Bureau of Investigation and is pronounced as individual letters F-B-I
Some phrases are also abbreviated as initialisms:
- “Talk to you later” is TTYL
- “As soon as possible” is ASAP
Acronyms and initialisms should always appear in uppercase form.
6. When adding emphasis
Be careful with this use of uppercase letters!
When you put words or sentences in ALL CAPS, a practice often seen in texts or posts, you add emphasis to your words. Consider how that emphasis will be perceived.
ALL CAPS statements carry more aggression and intensity than lowercase words. That’s not always a bad thing.
For example, texting someone “HAPPY BIRTHDAY!” instead of “Happy birthday” is a way to convey excitement and show you really mean those good wishes.
Other times, ALL CAPS can sound accusatory, demeaning, or rude.
Remember that ALL CAPS in writing makes it seem as though the speaker is yelling. Keep that in mind before you press “send” on your uppercase text or post!
A Summary of Lowercase and Uppercase Letters
Lowercase letters are used for common nouns and for every letter after the initial letter of the first word of a sentence.
Uppercase letters are most often used at the start of sentences and as the first letter of proper nouns, though there are other times to use the capital letter form too.
Take your writing to the next level:
20 Editing Tips from Professional Writers
Whether you are writing a novel, essay, article, or email, good writing is an essential part of communicating your ideas.
This guide contains the 20 most important writing tips and techniques from a wide range of professional writers.
What Are Lowercase, Uppercase Letters?
Lowercase letter definition: Lowercase letters are all other letters not in uppercase.
Uppercase letter definition: Uppercase letters are letters that represent the beginning of a sentence or a proper noun.
What are Lowercase Letters?
In writing, most letters are lowercase. Lowercase letters are all letters that do not begin a sentence or refer to a proper noun.
English alphabet lowercase letters: a b c d e f g h i j k l m n o p q r s t u v w x y z.
Examples of Lowercase Letters:
- word
- The word above uses only lowercase letters.

- The sentence above has lowercase letters after the first letter of the sentence.
- This sentence and the one directly above have all lowercase letters except for the “T.”
What are Uppercase Letters?
Uppercase letters are also known as capital letters. Uppercase letters signal to the reader that something is important or significant.
English alphabet uppercase letters: A B C D E F G H I J K L M N O P Q R S T U V W X Y Z.
Examples of Uppercase Letters:
- Jones
- This is a proper name, so the first letter of the title and the last name are capitalized
- Main Street
- This is a proper noun so the first letter of each word is capitalized
When to Use Uppercase Letters
In English, the first letter of every sentence is capitalized. The uppercase letter signals to the reader that a new sentence is beginning.
Other uses of uppercase letters are detailed below.
All titles are considered proper nouns and require capitalization.
Examples:
- Miss Mabry
- Incorrect: miss mabry
- Mathers
- Incorrect: mr. mathers
- Madam Lockfield
- Incorrect: madam lockfield
- Lady Grace
- Incorrect: lady grace
- Janks
- Incorect: mrs. janks
Acronyms are a type of abbreviation. Acronyms are words formed from other letters to make a new word. However, they require capital letters to signal to the reader that those letters stand for something and are not a word alone.
Examples:
- NATO
- North Atlantic Treaty Organization
- UNICEF
- United Nations International Children’s Emergency Fund
- SCUBA
- Self-contained underwater breathing apparatus
All proper nouns need to be capitalized.
Examples:
- We visited the Bowers Museum on Saturday.
- Incorrect: We visited the bowers museum on Saturday.
- I would like to tour the Eiffel Tower.
- Incorrect: I would like to tour the eiffel tower.
- Their names are Jake and Suzy.
- Incorrect: Their names are jake and suzy.
When to Use Lowercase Letters
Use lowercase letters for all letters other than the first in a sentence, provided that there is no required use for uppercase letters in the sentence.
Examples:
- Every word in this sentence other than the first word is written in lowercase.
- The only words in this sentence that require uppercase letters are the proper nouns, London and Paris.
All nouns that are not proper nouns are called common nouns. All common nouns use lowercase letters (unless a common noun begins a sentence).
Examples:
- tree
- dog
- bird
- water
- air
- star
- street
- girl
- baby
Summary
Define lowercase letters: lowercase letters are those letters used for common nouns and internal words.
Define uppercase letters: uppercase letters (also called capital letters) are those letters that signify the beginning of a sentence or a proper noun.
In summary,
- Uppercase and lowercase letters refer to all letters used to compose the English language.
- Uppercase letters are used to begin sentences and are also used for proper nouns.
- Lowercase letters are all letters that do not begin sentences.
Contents
- 1 What are Lowercase Letters?
- 2 What are Uppercase Letters?
- 3 When to Use Uppercase Letters
- 3.1 Titles
- 3.2 Acronyms
- 3.3 All Proper Nouns
- 4 When to Use Lowercase Letters
- 5 Summary
The truth about character case that programmers need to know / Habr
At the North Bay Python conference in 2018, I gave a talk on usernames. Most of the information in the report was compiled by me over 12 years of maintaining django-registration. This experience gave me a lot more knowledge than I had planned to have on how complex "simple" things can be.
This experience gave me a lot more knowledge than I had planned to have on how complex "simple" things can be.
At the beginning of the report, I did mention that this would not be another exposé from the series of "misconceptions about X that programmers believe." You can find any number of such revelations. However, I don't like these articles. They list various things that are allegedly false, but very rarely explain why this is so, and what should be done instead. I suspect that people will simply read articles like this, congratulate themselves on this achievement, and then go on to find new and interesting ways to make mistakes not mentioned in these articles. It's because they didn't really understand the problems that these bugs give rise to.
Therefore, in my report, I tried to explain some of the problems as best as possible and explain how to solve them - I like this approach much more. One topic that I've only touched on in passing (it was just one slide and a couple of mentions on other slides) is the complexities that can be associated with character case. There is an official Correct Answer™ for the problem I was discussing - comparing case-insensitive identifiers - and in the talk I gave the best solution I know, using only the Python standard library.
There is an official Correct Answer™ for the problem I was discussing - comparing case-insensitive identifiers - and in the talk I gave the best solution I know, using only the Python standard library.
However, I briefly mentioned the deeper complications with Unicode case, and I want to spend some time describing the details. This is interesting, and understanding this can help you make decisions when designing and writing code that processes text. Therefore, I offer you something opposite to the articles "misconceptions about X that programmers believe" - "the truth that programmers should know."
One more thing: Unicode is full of terminology. In this article, I will mainly use the definitions of "upper case" and "lower case" because the Unicode standard uses these terms. If you like other terms, like lowercase/uppercase letters, that's fine. Also, I will often use the term "symbol", which some may consider incorrect. Yes, in Unicode the concept of "character" isn't always what people expect, so it's often best to avoid it by using other terms. However, in this article, I will use the term as it is used in Unicode, to describe an abstract entity about which claims can be made. When it matters, I will use more specific terms like "code point" for clarification.
However, in this article, I will use the term as it is used in Unicode, to describe an abstract entity about which claims can be made. When it matters, I will use more specific terms like "code point" for clarification.
There are more than two registers
Speakers of European languages are accustomed to using case in their languages to denote specific things. For example, in English [and Russian] we usually start sentences with an uppercase letter and most often continue with lowercase letters. Also, proper nouns start with uppercase letters, and many acronyms and abbreviations are written in uppercase.
And we usually think that there are only two registers. There is an "A" and there is an "a". One is in upper case, the other is in lower case, isn't it?
However, there are three cases in Unicode. There is an upper one, there is a lower one, and there is a title case [titlecase]. In English, this is how names are written. For example, Avengers: Infinity War. Usually, to do this, the first letter of each word is simply written in uppercase (and depending on different rules and styles, some words, such as articles, are not capitalized).
For example, Avengers: Infinity War. Usually, to do this, the first letter of each word is simply written in uppercase (and depending on different rules and styles, some words, such as articles, are not capitalized).
The Unicode standard gives this example of a capital case character: U+01F2 LATIN CAPITAL LETTER D WITH SMALL Z. It looks like this: Dz.
Such characters are sometimes required to handle the negative consequences of one of the early design decisions of the Unicode standard: compatibility with existing text encodings in both directions. It would be more convenient for Unicode to compose sequences using the standard's character combination capabilities. However, in many systems already in existence, space has already been allocated for ready-made sequences. For example, in the ISO-8859-1 ("latin-1") standard, the character "é" has a prepared form numbered 0xe9. In Unicode, it would be preferable to write this letter with a separate "e" and an accent mark. But to ensure full compatibility in both directions with existing encodings such as latin-1, Unicode also assigns code points for predefined characters. For example, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
For example, U+00E9 LATIN SMALL LETTER E WITH ACUTE.
Although this character's code position is the same as its latin-1 byte value, don't rely on it. It is unlikely that the character encoding in Unicode will retain these positions. For example, in UTF-8 code position U+00E9written as the byte sequence 0xc3 0xa9.
And, of course, there are characters in already existing encodings that needed special treatment when using title case, which is why they were included in Unicode "as is". If you want to look at them, search your favorite Unicode database for characters in the Lt ("Letter, titlecase") category.
There are several ways to determine the register
The Unicode Standard (§4.2) lists three different definitions of case. Perhaps the choice of one of the three makes your programming language for you; otherwise, your choice will depend on the specific purpose. Here are the definitions:
- A character is uppercase if it belongs to the category Lu ("Letter, uppercase"), and lowercase if it belongs to the category Ll ("Letter, lowercase").
 The standard recognizes the limitations of this definition: each specific character has to be attributed to only one of the categories. Because of this, many characters that "should be" in upper or lower case will not meet this requirement because they belong to some other category.
The standard recognizes the limitations of this definition: each specific character has to be attributed to only one of the categories. Because of this, many characters that "should be" in upper or lower case will not meet this requirement because they belong to some other category. - The character is uppercase if it inherits the Uppercase property, and lowercase if it inherits the Lowercase property. It is a combination of defining one with other character properties, which may include case.
- A character is in uppercase if it does not change after a case mapping to uppercase has been applied to it. A character is in lowercase if, after applying a lowercase case mapping to it, it does not change. A rather general definition, however, it can also behave non-intuitively.
If you are working with a limited subset of characters (specifically, letters), then 1 definition may be enough for you. If your repertoire is broader - it includes characters that look like letters that are not letters, the 2nd definition may suit you. It is also recommended by the Unicode standard, §4.2:
It is also recommended by the Unicode standard, §4.2:
Programmers manipulating Unicode strings should work with string functions such as isLowerCase (and its functional cousin toLowerCase) if they do not operate on character properties directly.
The function mentioned here is defined in §3.13 of the Unicode Standard. Formally, the 3rd definition uses the functions isLowerCase and isUpperCase from §3.13, defined in terms of fixed positions in toLowerCase and toUpperCase, respectively.
If your programming language has functions for checking or converting the case of strings or individual characters, it's worth looking into which of the definitions mentioned are used in the implementation. If you're wondering, Python's isupper() and islower() methods use the 2nd definition.
Cannot understand the case of a character by its appearance or name
By the appearance of many characters, you can understand what case they are in. For example, "A" is in upper case. This is clear from the name of the symbol: "LATIN CAPITAL LETTER A". However, sometimes this method does not work. Let's take the code position U+1D34. It looks like this: ᴴ. In Unicode, it's assigned a name: MODIFIER LETTER CAPITAL H. So it's in uppercase, right?
For example, "A" is in upper case. This is clear from the name of the symbol: "LATIN CAPITAL LETTER A". However, sometimes this method does not work. Let's take the code position U+1D34. It looks like this: ᴴ. In Unicode, it's assigned a name: MODIFIER LETTER CAPITAL H. So it's in uppercase, right?
In fact, it inherits the Lowercase property, so by definition #2 it is in lower case, despite the fact that it visually resembles a capital H, and the name contains the word "CAPITAL".
Some characters have no case at all
Definition 135 in §3.13 of the Unicode Standard reads:
The character C is case-sensitive if and only if C has a Lowercase or Uppercase property, or the value of the General_Category parameter is Titlecase_Letter.
So a lot of Unicode characters - in fact, most of them - are caseless. Questions about their case do not make sense, and case changes do not affect them. However, we can get the answer to this question by definition #3.
Some characters behave as if they have multiple cases
It follows from this that if you use definition #3 and ask if an uncase character is in uppercase or lowercase, you will get the answer "yes".
The Unicode standard gives an example (Table 4-1, line 7) of the U+02BD MODIFIER LETTER REVERSED COMMA character (which looks like this: ʽ). It does not have the inherited Lowercase or Uppercase properties, and is not in the Lt category, so it is not case-sensitive. However, converting to upper case does not change it, and converting to lower case does not change it, so by definition 3 it answers yes to both questions: "Are you upper case?" and “are you lowercase?”
This seems like a lot of unnecessary confusion, but the point is that definition #3 works with any sequence of Unicode characters, and simplifies case conversion algorithms (caseless characters just turn into themselves).
Case dependent on context
You might think that if the Unicode case conversion tables cover all characters, then this conversion is simply a matter of finding the right place in the table. For example, the Unicode database says that U+0041 LATIN CAPITAL LETTER A will be U+0061 LATIN SMALL LETTER A in lowercase. Simple, right?
For example, the Unicode database says that U+0041 LATIN CAPITAL LETTER A will be U+0061 LATIN SMALL LETTER A in lowercase. Simple, right?
One example where this approach does not work is Greek. The character Σ—that is, U+03A3 GREEK CAPITAL LETTER SIGMA—is mapped to two different characters when converted to lowercase, depending on where it appears in the word. If it is at the end of a word, then it will be ς (U+03C2 GREEK SMALL LETTER FINAL SIGMA) in lower case. Anywhere else it will be σ (U+03C3 GREEK SMALL LETTER SIGMA).
This means that the register has no one-to-one or transitivity. Another example is ß (U+00DF LATIN SMALL LETTER SHARP S, or escet). In uppercase it would be "SS", although there is now another uppercase form of it (ẞ, U+1E9E LATIN CAPITAL LETTER SHARP S). And converting "SS" to lowercase results in "ss", so (using Unicode terminology for case conversion): toLowerCase(toUpperCase(ß)) != ß.
Locale-specific case
Different languages have different case conversion rules. The most popular example: i (U+0069 LATIN SMALL LETTER I) and I (U+0049 LATIN CAPITAL LETTER I) are converted to each other in most locales - most, but not all. In the az and tr locales (Turkic), the uppercase i is İ (U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE) and the lowercase I is ı (U+0131 LATIN SMALL LETTER DOTLESS I). Sometimes the right notation really means the difference between life and death.
The most popular example: i (U+0069 LATIN SMALL LETTER I) and I (U+0049 LATIN CAPITAL LETTER I) are converted to each other in most locales - most, but not all. In the az and tr locales (Turkic), the uppercase i is İ (U+0130 LATIN CAPITAL LETTER I WITH DOT ABOVE) and the lowercase I is ı (U+0131 LATIN SMALL LETTER DOTLESS I). Sometimes the right notation really means the difference between life and death.
Unicode itself does not handle all possible case conversion rules for all locales. In the Unicode database, there are only general rules for converting all characters that are not dependent on the locale. Also there are special rules for some languages and compound forms - Lithuanian, Turkic languages, some features of Greek. Everything else is not there. §3.13 of the standard mentions this and recommends introducing locale-specific conversion rules when necessary.
One example that will be familiar to English speakers is the title case of certain names. "o'brian" must be converted to "O'Brian" (not to "O'brian"). However, in this case, "it's" must be converted to "It's", and not to "It's". Another example that is not handled in Unicode is the Dutch character "ij", which, when converted to title case, must be converted to uppercase if it appears at the beginning of a word. Thus, a large bay in the Netherlands would be "IJsselmeer" in the title case, not "Ijsselmeer". Unicode has the characters IJ U+0132 LATIN CAPITAL LIGATURE IJ and ij U+0133 LATIN SMALL LIGATURE IJ if you need them. By default, case conversion converts them to each other (although Unicode normalization forms using compatibility equivalence will split them into two separate characters).
However, in this case, "it's" must be converted to "It's", and not to "It's". Another example that is not handled in Unicode is the Dutch character "ij", which, when converted to title case, must be converted to uppercase if it appears at the beginning of a word. Thus, a large bay in the Netherlands would be "IJsselmeer" in the title case, not "Ijsselmeer". Unicode has the characters IJ U+0132 LATIN CAPITAL LIGATURE IJ and ij U+0133 LATIN SMALL LIGATURE IJ if you need them. By default, case conversion converts them to each other (although Unicode normalization forms using compatibility equivalence will split them into two separate characters).
Case-insensitive comparison requires folded case conversion
Returning to the material presented in the report. The complexity of dealing with case in Unicode means that case-insensitive comparison cannot be done using the standard lowercase or uppercase conversion functions found in many programming languages. For such comparisons, Unicode has the concept of case folding, and §3.13 of the standard defines the toCaseFold and isCaseFolded functions.
For such comparisons, Unicode has the concept of case folding, and §3.13 of the standard defines the toCaseFold and isCaseFolded functions.
You might think that folding to folded case is like casting to lowercase, but it's not. The Unicode standard warns that a folded-case string will not necessarily be in lowercase. The Cherokee language is given as an example - there, in a line that is in folded case, characters in upper case will also come across.
One of the slides in my report implements the recommendations of Unicode Technical Report #36 in Python as fully as possible. NFKC is normalized and then the casefold() method (only available in Python 3+) is called on the resulting string. Even so, some edge cases fall out, and this is not exactly what is recommended for comparing identifiers. First, the bad news: Python doesn't expose enough Unicode properties to filter out characters that aren't in XID_Start or XID_Continue, or characters that have the Default_Ignorable_Code_Point property. To my knowledge it does not support NFKC_Casefold mapping. It also lacks an easy way to use the modified NFKC UAX #31§5.1.
To my knowledge it does not support NFKC_Casefold mapping. It also lacks an easy way to use the modified NFKC UAX #31§5.1.
The good news is that most of these edge cases do not involve any real security risks posed by the characters in question. And case folding is in principle not defined as a normalization-preserving operation (hence the NFKC_Casefold mapping, which renormalizes to NFC after case folding). Generally, when comparing, you don't care if both strings are normalized after preprocessing. What you care about is whether the preprocessing is inconsistent, and whether it guarantees that only strings that "should" be different afterwards will be different afterwards. If this bothers you, you can manually renormalize after case addition.
Enough for now
This article, like the previous report, is not exhaustive, and it is hardly possible to fit all this material into a single post. I hope this has been a useful overview of the complexities associated with this topic and that you will find enough starting points in it to look for further information. Therefore, in principle, you can stop here.
Therefore, in principle, you can stop here.
Wouldn't it be naïve for me to hope that other people would stop writing exposés from the series of "misconceptions about X that programmers believe" and start writing articles like "the truth programmers should know"?
What is upper and lower case on the keyboard?
Posted on by Avtomatika ConcernCategories:Equipment
When novice users first get acquainted with the keyboard, the question often arises: “What are the upper and lower case on the keyboard?”. It turns out that everything is very simple. Uppercase letters means that uppercase letters and, accordingly, lowercase and lowercase letters are currently being entered from the keyboard. That is, each sentence begins with a capital letter. We use capital letters for this. The rest of the sentence is written in "lowercase" letters, i.e., a lowercase letter is used. This is the answer to the question of what uppercase and lowercase letters are used on the keyboard.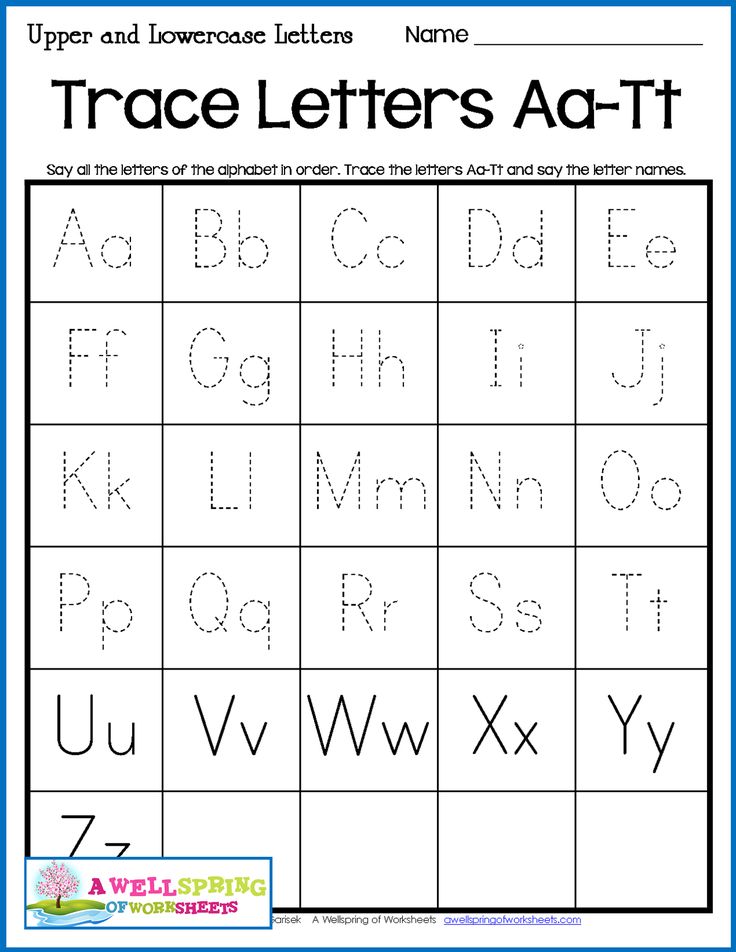 There are various ways to switch between input modes, which we will discuss later.
There are various ways to switch between input modes, which we will discuss later.
Momentary switching
Now we know what uppercase and lowercase letters are on the keyboard. Let's look at the main ways to switch between uppercase and lowercase letters. Passes temporary and permanent. Another method is implemented programmatically in office software. This will also be considered within the framework of this material. Let's start with a short term perspective. Every computer keyboard has a "Shift" key (some of them may have an up arrow instead of an inscription). If capital letters are entered at a certain time, pressing this key in combination with any text character will display it in lower case and vice versa. This method is convenient to use at the beginning of a sentence. That is, they entered an uppercase character, so everything is typed in lowercase.
Long dialing
Uppercase and lowercase letters of the keyboard can be changed in another way. For these purposes, there is a special key "Caps Lock". It is usually found on the far left row of the keyboard between the Tab and Shift keys. When pressed, the register changes constantly. To determine the current mode, look at the LED on the keyboard with exactly the same inscription: "Caps Lock". If it is lit, it means that uppercase letters are entered, otherwise lowercase. To switch between modes, press this button again. This method is best used when you need to constantly enter text in the same format (for example, only uppercase characters) and switching between input formats, if this happens, does not happen as often.
For these purposes, there is a special key "Caps Lock". It is usually found on the far left row of the keyboard between the Tab and Shift keys. When pressed, the register changes constantly. To determine the current mode, look at the LED on the keyboard with exactly the same inscription: "Caps Lock". If it is lit, it means that uppercase letters are entered, otherwise lowercase. To switch between modes, press this button again. This method is best used when you need to constantly enter text in the same format (for example, only uppercase characters) and switching between input formats, if this happens, does not happen as often.
For office applications
Another way to change uppercase and lowercase characters is implemented in the Microsoft office suite. Most often used in the text editor "Word". Have you forgotten to accidentally switch from uppercase to lowercase or vice versa while typing? Uppercase and lowercase characters in this case can be changed as follows.