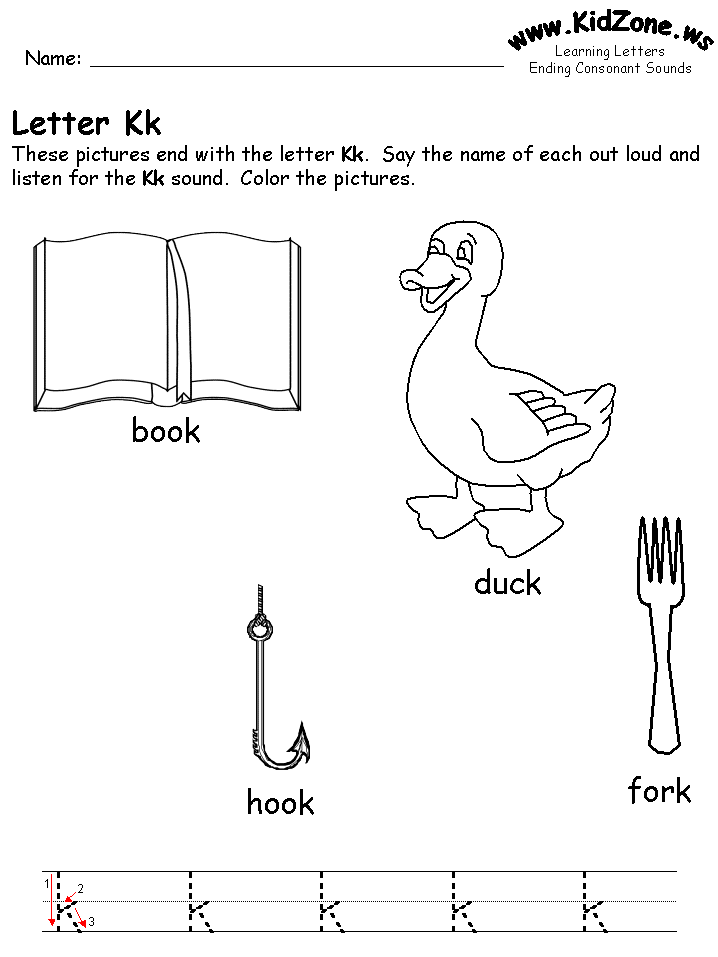
Segmenting words activities
Blending and Segmenting Games | Classroom Strategies
Children who can segment and blend sounds easily are able to use this knowledge when reading and spelling. Segmenting and blending individual sounds can be difficult at the beginning. Our recommendation is to begin with segmenting and blending syllables. Once familiar with that, students will be prepared for instruction and practice with individual sounds.
| How to use: | Individually | With small groups | Whole class setting |
What are blending and segmenting?
Blending (putting sounds together) and segmenting (pulling sounds apart) are skills that are necessary for learning to read and spell. When students understand that spoken words can be broken up into individual sounds (phonemes) and that letters can be used to represent those sounds, they have the insight necessary to read and write in an alphabetic language. Blending and segmenting games and activities can help students to develop phonemic awareness, a strong predictor of reading achievement.
Why teach blending and segmenting?
- Teaching students to identify and manipulate the sounds in words (phonemic awareness) helps build the foundation for phonics instruction.
- Blending and segmenting activities and games can help students to develop phonological and phonemic awareness.
- Developing phonemic awareness is especially important for students identified as being at risk for reading difficulty.
How to teach blending and segmenting
Segmenting and blending — especially segmenting and blending phonemes (the individual sounds within words) — can be difficult at first because spoken language comes out in a continuous stream, not in a series of discrete bits. Beginning with larger units of speech can help.
Early in phonological awareness instruction, teach children to segment sentences into individual words. Identify familiar short poems such as "I scream you scream we all scream for ice cream!" Have children clap their hands with each word.
As children advance in their ability to manipulate oral language, teach them to segment words into syllables. For example, have children segment their names into syllables: e.g., Ra-chel, Al-ex-an-der, and Rod-ney. Likewise, have them blend syllables to make words.
Once in kindergarten, the focus of blending and segmenting instruction should shift to the phoneme level. This work can be challenging for students, so it can be useful to know which scaffolds can help students make the leap.
- Start with words that have only two phonemes (for example, am, no, in)
- Begin with continuous sounds (phonemes that can be held for a beat or two without distorting the sound). Have students practice blending and segmenting words with continuous sounds by holding the sounds using a method called “continuous blending” or “continuous phonation.” (e.g., “aaaammmm ... am”)
- Then, introduce a few stop sounds (phonemes that cannot be held continuously).
 Ensure that students articulate the sounds cleanly, without adding an “uh” to the ends of sounds such as /t/ and /b/. Stop sound at the end of words (eg. at, up) are easier to blend than those that have stop sounds at the beginning (for example, be, go)
Ensure that students articulate the sounds cleanly, without adding an “uh” to the ends of sounds such as /t/ and /b/. Stop sound at the end of words (eg. at, up) are easier to blend than those that have stop sounds at the beginning (for example, be, go) - As students are ready, progress to words with three phonemes, keeping in mind that words beginning with continuous phonemes (for example, sun) are easier to blend and segment than those with stop sounds (for example, top).
- As students become more skilled at blending and segmenting, they may no longer need to hold sounds continuously, transitioning from “ssssuuunnn” to sun.
It can be helpful to anchor the sounds students are working with to visual scaffolds. Elkonin boxes, manipulatives (such as coins or tiles), and hand motions are popular supports. It’s important to remember, however, that the goal of blending and segmenting games is literacy and there is no better visual representation for a phoneme than a letter.
Collect resources
Blending: guess-the-word game
This activity, from our article Phonological Awareness: Instructional and Assessment Guidelines, is an example of how to teach students to blend and identify a word that is stretched out into its basic sound elements.
Objective: Students will be able to blend and identify a word that is stretched out into its component sounds.
Materials needed: Picture cards of objects that students are likely to recognize such as: sun, bell, fan, flag, snake, tree, book, cup, clock, plane
Activity: Place a small number of picture cards in front of children. Tell them you are going to say a word using "Snail Talk" a slow way of saying words (e.g., /fffffllllaaaag/). They have to look at the pictures and guess the word you are saying. It is important to have the children guess the answer in their head so that everyone gets an opportunity to try it. Alternate between having one child identify the word and having all children say the word aloud in chorus to keep children engaged.
Talking in "Robot Talk," students hear segmented sounds and put them together (blend them) into words. See robot talk activity ›
See all Blending/Segmenting Activities from the University of Virginia PALS program
Blending slide
The "Reading Genie" offers teachers a simple way to teach students about blends. Teachers can use a picture or small replica of a playground slide and have the sounds "slide" together to form a word. See blending slide activity ›
Oral blending activity
The information here describes the importance of teaching blending skills to young children. This link provides suggestions for oral sound blending activities to help students practice and develop smooth blending skills. See oral blending activities ›
Sound blending using songs
This activity (see Yopp, M., 1992) is to the tune of "If You're Happy and You Know It, Clap Your Hands."
If you think you know this word, shout it out!
If you think you know this word, shout it out!
If you think you know this word,
Then tell me what you've heard,
If you think you know this word, shout it out!
After singing, the teacher says a segmented word such as /k/ /a/ /t/ and students provide the blended word "cat. "
"
Segmenting cheer activity
This link provides teachers with information on how to conduct the following segmentation cheer activity. See segmenting cheer activity ›
Write the "Segmentation Cheer" on chart paper, and teach it to children. Each time you say the cheer, change the words in the third line. Have children segment the word sound by sound. Begin with words that have three phonemes, such as ten, rat, cat, dog, soap, read, and fish.
Segmentation Cheer
Listen to my cheer.
Then shout the sounds you hear.
Sun! Sun! Sun!
Let's take apart the word sun.
Give me the beginning sound. (Children respond with /s/.)
Give me the middle sound. (Children respond with /u/.)
Give me the ending sound. (Children respond with /n/.)
That's right!
/s/ /u/ /n/-Sun! Sun! Sun!
Segmenting with puppets
Teachers can use the activity found on this website to help teach students about segmenting sounds. The activity includes the use of a puppet and downloadable picture cards. See segmenting with puppets activity ›
The activity includes the use of a puppet and downloadable picture cards. See segmenting with puppets activity ›
Differentiate instruction
For English-learners, readers of different ability levels, or students needing extra support:
- Incorporate print into blending and segmenting the individual sounds in words with students who know the spelling-sound correspondences in the words.
- Use picture-centered activities to support English-learners and younger students.
Related strategies
Find more activities for building phonological and phonemic awareness in our Reading 101 Guide for Parents.
See the research that supports this strategy
Chard, D., & Dickson, S. (1999). Phonological Awareness: Instructional and Assessment Guidelines.
Clemens, N., Solari, E., Kearns, D. M., Fien, H., Nelson, N. J., Stelega, M., Burns, M., St. Martin, K. & Hoeft, F. (2021, December 14). They Say You Can Do Phonemic Awareness Instruction “In the Dark”, But Should You? A Critical Evaluation of the Trend Toward Advanced Phonemic Awareness Training.
Fox, B., & Routh, D.K. (1976). Phonemic analysis and synthesis as word-attack skills. Journal of Educational Psychology, 68, 70-74.
Gonzalez-Frey, S. & Ehri, L.C. (2021) Connected Phonation Is More Effective than Segmented Phonation for Teaching Beginning Readers to Decode Unfamiliar Words. Scientific Studies of Reading, 25:3, 272-285.
Sensenbaugh. (1996). ABCs of Phonemic Awareness.
Smith, S.B., Simmons, D.C., & Kameenui, E.J. (February, 1995). Synthesis of research on phonological awareness: Principles and implications for reading acquisition. (Technical Report no. 21, National Center to Improve the Tools of Education). Eugene: University of Oregon.
Yopp, H. K. (1992). Developing phonemic awareness in young children. The Reading Teacher, 45 , 696-703.
5 Activities for Developing Phoneme Segmentation Skills
Sharing is caring!
- Share
- Tweet
Phoneme segmentation is a foundational skill for reading and writing. It’s important to start teaching phoneme segmentation skills early so children can develop this skill before it becomes more difficult to learn.
It’s important to start teaching phoneme segmentation skills early so children can develop this skill before it becomes more difficult to learn.
Mastering phoneme segmentation helps readers break apart sounds in a word, blend them together, and read! Here are five activities you can do at home or school to teach this skill.
What is phoneme segmentation?
Phoneme segmentation is the ability to break a word up into its individual sounds. It is on the development continuum of Phonemic Awareness, along with rhyming and blending, but is one of the more difficult concepts for children to grasp.
Phonemic awareness refers to the ability to hear the sounds of language. It includes learning how to phonetically segment (break apart) a word into individual sounds and blend different combinations of sounds together to form words.
Reading is made possible by the ability to hear each sound within spoken words. When children can’t accurately detect or distinguish between these sounds, they struggle to decode and understand what is being read. Phonemic awareness is an early step in learning to read, and is a key component of decoding.
Phonemic awareness is an early step in learning to read, and is a key component of decoding.
Phonemic awareness helps students learn the relationships between letters, letter patterns, and sounds; it also helps with spelling and writing.
When you segment a word, you break it down into its individual sounds.
For example, let’s look at the word cat. We can segment this word into 3 sounds: /c/ /a/ /t/
Let’s try the word purple. We can segment this word into 4 sounds: /p/ /ur/ /p/ /l/
Why is phoneme segmentation important?
Segmenting words into individual sound units enables students to focus on the basic elements that make up spoken language. Students must be able to decode words into their basic phonemic chunks before they will be able to read fluently and with comprehension.
Children who are better at recognizing “sounding out” words have stronger abilities in literacy acquisition, vocabulary development, spelling, and knowledge of how letters represent sounds.
Phoneme segmentation is an important early step in learning how to read, so let’s get started!
segmenting the word bat with magnetsWhen to teach phoneme segmentation
Students should already be familiar with segmenting and blending compound words and syllables (all included in my Phonemic Awareness Task Cards). Once they can confidently segment and blend compound words and syllables you can move on to working with phonemes.
How to teach phoneme segmentation
You should start by using manipulatives and move away from manipulatives until students don’t need them to break apart words. Initially, you would use something like a bingo chip or cube, and move on to using letter tiles as students progress with this skill.
If students don’t quite understand what you mean by breaking up the word, tell them to stretch the word out into its individual sounds. This seems to help some who struggle with the concept.
Remember, students should already be familiar with segmenting compound words and syllables so the actual skill of splitting is not completely new for them! If you have not done that, then go back before segmenting phonemes. My daily Phonemic Awareness Task Cards includes all these skills and more in the correct progression.
My daily Phonemic Awareness Task Cards includes all these skills and more in the correct progression.
Phoneme Segmentation Activities
Elkonin Boxes
Elkonin Boxes are a great activity for introducing and practicing phoneme segmentation. It starts out with just two boxes, but then you can add more as students work with longer words.
Here’s how it works: First, the teacher says a word that contains one syllable, such as ‘me‘. The student repeats the word aloud then places a manipulative into the first box as they say the first sound in the word. In this example, the student would say /m/ and place a tile in the first box to represent that first sound. Then the student would say /ee/ while placing a manipulative in the next box.
From here you would move on to words with 3 sounds, like cat or play, and then words with 4 sounds, such as jump or clock. For each sound, a manipulative is placed in one box while the student makes that sound.
You can move from bingo chips to letter tiles, and eventually have students write the corresponding letters in the boxes. You want students to notice that sometimes 2 or 3 letters combine to make 1 sound.
Tapping Out Sounds
Tapping out sounds is a great skill that I teach my students to use all the time when working with new words. You don’t even need anything other than fingers to do this.
Have students tap on their arm or desk as they say each sound in a word. For example, with the word ‘dog‘, students would tap their thumb on the desk while saying /d/, tap their pointer finger on the desk while saying /o/, and tap their middle finger on the desk while saying /g/.
They could also tap their pointer, middle, ring, and pinky finger to their thumb instead of tapping a desk or their arms.
It doesn’t really matter what they tap, but that they use one finger for one sound.
You can also use worksheets and flashcards that have dots under or above each phoneme, as pictured above, and have students tap on each dot as they say the sound aloud.
Instead of tapping, you can also have students clap each sound to segment a word.
Below you can see how I use those popular Pop It toys on a worksheet to segment and write words. I have this worksheet available to download for free in my freebies library.
Phoneme Grapheme Mapping
This is very similar to Elkonin boxes but combines it with writing.
You say a word and/or show a picture of it. Students segment the word using manipulatives or by tapping out the sounds. Then students write the letters in sound boxes.
I have a free simple word mapping worksheet template that you can download in my freebies library.
You can also purchase my blank orthographic mapping templates from my shop to use with words that have 2 to 5 sounds. It’s a multisensory version with more steps than my freebie template (pictured above).
CVC Sliders
Using something like a pipe cleaner with stringing beads, students can slide a bead over for each sound while segmenting a word. Call out words or hand students some picture cards that they can segment on their own. This could make a fun center if you created a deck of picture cards or worksheets.
Call out words or hand students some picture cards that they can segment on their own. This could make a fun center if you created a deck of picture cards or worksheets.
Count the Sounds
Say a word aloud, or show students a picture, and ask them to count how many sounds are in the word. I like to give students a few picture cards and have them sort them into piles by how many sounds they have. Or I create cut and paste worksheets focusing on counting the sounds. The picture above is a worksheet from my Halloween Phonemic Awareness Activities set.
You can also use a Pop It fidget toy to count the sounds in words they hear.
Phoneme Jumping
This is a more kinesthetic activity, great for those wiggly students!
Instead of tapping or clapping, students would jump for each sound.
Students will hop while saying the sound out loud to segment the word. They can hop in place, or you can place a few targets on the floor much like sound boxes, for them to jump across one at a time as they sound out a word. This last one can also help with directionality issues.
This last one can also help with directionality issues.
Phonemic Awareness Task Cards
If you’re looking for easy and quick ways to get phonemic awareness in your lessons then check out my no prep Phonemic Awareness Task Cards. These task cards include 124 cards that cover all areas of phonemic awareness, including phoneme segmentation, and can be done in just 5 minutes a day.
Bottom Line
Phonemic Awareness is a set of skills that are necessary to learn how to read. It’s important for children to develop the ability to segment words into their phonemes (unit sounds) in order to be successful readers, but this can often take time and practice. Try out these 5 phoneme segmentation activities to practice phoneme segmentation, and check out these other phonemic awareness activities to build phonemic awareness skills in developing readers.
Want to remember this? Save How to Teach Phoneme Segmentation to your favorite Pinterest board!
If you’re looking for more tips on teaching reading to struggling learners, check out these other posts:
- How To Structure Your Literacy Block
- Reading Assessments You Should Be Using
- What is the Science of Reading?
- Teaching High Frequency Words Using the Heart Word Method
- Phonemic Awareness Strategies & Activities For Struggling Learners
- The 6 Syllable Types
- Why You Should Switch To A Sound Wall
- Reading Strategies for Struggling Readers – Elkonin Boxes
- Activities That Improve Reading Fluency
Sharing is caring!
- Share
- Tweet
Source text segmentation
- Segmentation rules
- Rule Priority
- Create a new rule
- A few simple examples
Translation memory programs work with text units called "segments". OmegaT segments text in two ways: by paragraph and by sentence (sentence segmentation is sometimes called "rule-based segmentation"). To set the type of segmentation, select the menu item "Project → Properties..." and check or uncheck the appropriate box. In some cases, paragraph segmentation can be useful, for example in creative translation, if the translator wants to change the order of sentences. In other cases, segmentation by offers will be preferable. If segmentation by offers is selected, its rules can be configured by selecting from the main menu "Options → Segmentation...".
OmegaT segments text in two ways: by paragraph and by sentence (sentence segmentation is sometimes called "rule-based segmentation"). To set the type of segmentation, select the menu item "Project → Properties..." and check or uncheck the appropriate box. In some cases, paragraph segmentation can be useful, for example in creative translation, if the translator wants to change the order of sentences. In other cases, segmentation by offers will be preferable. If segmentation by offers is selected, its rules can be configured by selecting from the main menu "Options → Segmentation...".
For many languages, segmentation rules have already been developed, and most likely, they will be enough for you. On the other hand, in some cases, the ability to slightly change the segmentation rules to work with certain text can be very useful.
Caution: since text segmentation will be different after changing the rules, it is possible that the translation will have to start over. Previously translated segments will be marked as "no segments" in the project memory. If you change the segmentation settings while working with the project, the project will have to be reloaded for the changes to take effect.
Previously translated segments will be marked as "no segments" in the project memory. If you change the segmentation settings while working with the project, the project will have to be reloaded for the changes to take effect.
In OmegaT, segmentation is carried out as follows:
- Structure level segmentation
-
OmegaT first scans the text to perform structure-level segmentation. At this stage, only information about the structure of the text is used for segmentation.
For example, for text files, segmentation can be performed on line breaks, empty lines, or not at all. Formatted files (ODF documents, HTML files, etc.) are segmented by paragraph tags. Translatable object attributes in XHTML or HTML can be extracted as separate segments.
- Sentence level segmentation
-
After segmenting the source file into structural fragments, OmegaT starts segmenting them by sentences.

Segmentation rules
The segmentation process can be described as follows: imagine a cursor moving through the text, passing one character at a time. For each cursor position in the given order, rules consisting of patterns are applied to and After , which check if the pattern matches To to text on the left and template After to the text to the right of the cursor. If any of the rules is triggered, then either the cursor moves to the next character without starting a new segment (the so-called exception rule), or a new segment is created at the current cursor position (the so-called break rule).
There are two types of rules:
- break rule
-
Divides the source text into segments.
 For example, the sentence " Was it worth it? Not sure ." should be divided into two segments. That is, you need to define a break rule for the character "?" followed by a space and a capitalized word. The Breaks/Exceptions checkbox determines whether the rule is a break (checked) or an exception (checked).
For example, the sentence " Was it worth it? Not sure ." should be divided into two segments. That is, you need to define a break rule for the character "?" followed by a space and a capitalized word. The Breaks/Exceptions checkbox determines whether the rule is a break (checked) or an exception (checked).
- exception rule
-
Specifies which part of the text should NOT be segmented. Despite the dot, the phrase Mrs. Dalloway" do not need to split into two segments, so you need to define an exclusion rule for the string Mrs (and Mr, Dr, prof, etc.) with a dot on the right. To indicate that a rule is an exception, leave the Break/Exception checkbox unchecked.
Standard break rules should be sufficient for most European languages and Japanese. However, it is possible for you to define new exception rules for some languages in order to get more meaningful and adequate segments.
However, it is possible for you to define new exception rules for some languages in order to get more meaningful and adequate segments.
Rule priority
All segmentation rule sets with a matching language pattern are applied in the specified order, such that language-specific rules take precedence over standard rules. For example, rules for Canadian French (FR-CA) will take precedence over rules for French (FR.*) and default rules (.*). Accordingly, when translating from Canadian French, the rules for this language (if any) will be applied first, then the general rules for French and the standard rules.
Create a new rule
Serious changes to the segmentation rules are usually not worth making, especially after the start of the project, but small changes (for example, adding recognition of a new abbreviation) can be very useful.
To extend or modify an existing set of rules, simply select it in the table. The rules of this set will appear at the bottom of the window.
The rules of this set will appear at the bottom of the window.
To create a set of rules for a new language template, click the button Add at the top of the dialog box. An empty line will appear at the bottom of the table at the top of the window (you may have to move the scroll bar to find it). In the appropriate fields, enter the language name and template (see Appendix A, Languages - ISO 639 code list) language codes). The syntax of the Language Pattern field follows the rules of regular expressions. If the rule set you are creating matches the language-country pattern (and not language-*), it is recommended that you move it up using the button Up .
Fill in the templates To and After . To check the syntax and correct operation of regular expressions, it is recommended to use special programs. See Regular Expressions for more information. Of course, the best place to start is by becoming familiar with the existing set of rules.
See Regular Expressions for more information. Of course, the best place to start is by becoming familiar with the existing set of rules.
Some simple examples
Page segmentation - overview / Sudo Null IT News
Some time ago (oh my God, a year has already passed!) When I asked if anyone would be interested in an overview of modern document page image segmentation methods, I received a positive answer (from massimus). And today I finally decided to do this review.
But first, a small digression. The text recognition system in our products can be described very simply. We have a page with text, we parse it into text blocks, then parse the blocks into separate lines, lines into words, words into letters, we recognize letters, then we collect everything back into the text of the page along the chain. The task of segmentation is posed something like this: there is a page, it is necessary to decompose it into text and non-text elements.
Further, the problem can be refined and refined (here I'm already fed up with explaining that the correct formulation of the problem is already half a step towards its solution; you can be sure that I annoyed my colleagues and the authorities even more). Scientists from different countries, the authors of the given methods, want to do science, not casuistry, so they formulate their task in a simpler way:
There is text and pictures on the page. It is required to break the text into blocks and highlight the pictures.
I was inspired by an article by F. Shafait, D. Keysers, and Th. Breuel. Performance Comparison of Six Algorithms for Page Segmentation (hereinafter I will call it SKB, by the initial letters of the names of the authors), which gives a comparative assessment of almost all the above segmentation methods. So if you want to immediately delve into the primary sources, then it’s better to take it and follow the links. A description of the algorithms themselves, details and discussion - here.
So, we need to break the text into blocks and highlight the pictures. As you can see, tables, diagrams and other frills are out of the question here; moreover, it is often assumed that images are high-contrast and well-binarized at the same time - that is, their boundaries can, in principle, be found by working only with a monochrome image.
Also, the concepts of "Manhattan" and "non-Manhattan" layout are often used in research. "Manhattan" is one in which the boundaries of all blocks are straight (each block is either rectangular, or represents several rectangles that have some vertices and parts of the sides in common), "non-Manhattan" does not satisfy such restrictions.
To begin with, we will analyze some algorithms designed to work with a "Manhattan" document.
Smearing
This is the most ancient algorithm - perhaps the first thing that comes to mind when faced with the task of segmentation. First described back in 1982, in an article by K. Y. Wong, R. G. Casey, F. M. Wahl. Document Analysis System.
Y. Wong, R. G. Casey, F. M. Wahl. Document Analysis System.
In a nutshell, it works like this: let's spread the words a little vertically and horizontally, the resulting connected areas will be finished blocks.
If we describe a little more, it will turn out like this:
- Take the image of the page in the RLE representation
- Delete white RLE strokes (=sequence of white pixels) less than lT_horz. Getting image Image_1
- Rotate the original image by 90 degrees and delete the white RLE-strokes on the rotated image with a length less than lT_vert. Rotate the image back and get the image Image_2
- ANDing images Image_1 and Image_2
- On the resulting image, one more time, delete white strokes with a length less than T_Final
The connected areas in the resulting image are finished blocks. They should be divided into text and non-text. In 1982, there was no such arsenal of machine learning tools, it was difficult without them - the decision tree was drawn by hand.
This is how intermediate images and final blocks look like:
In the original article, the authors worked with a picture with a resolution of 240 dpi and picked up the values T_horz = 300 T_vert = 500 and T_final = 30. Somewhat unexpectedly, the values turned out to be so large ( T_vert is already two inches with a hook), apparently this is due to the fact that AND is being done.
The advantages of the algorithm are clear - it is simple, it works with the RLE image and only with it, and therefore it is fast. The algorithm itself nowhere explicitly relies on the fact that the input document is "Manhattan". However, if you think about it, then the algorithm will not work on “non-Manhattan” - in the example below, the text will stick to the picture.
The really bad news is that on the Manhattan document, gluing text and non-text is also very common, in SKB this is noticed.
Recursive XY cut
A couple of years later, in 1984, a more advanced page segmentation method called recursive XY cut was described. It is described in G. Nagy and S. Seth. "Hierarchical representation of optically scanned documents" was actively developed in the 90s.
It is described in G. Nagy and S. Seth. "Hierarchical representation of optically scanned documents" was actively developed in the 90s.
This method has already been explicitly stated to be valid only for a Manhattan document. The essence of the method is that we divide the page into blocks alternately, dividing the blocks vertically or horizontally. That is, the algorithm is something like this:0013
- Preparing the page, cleaning it from small debris
- Select connected areas. You can even combine them a little and get something like words, if suddenly someone knows how to safely build such unions. But within the framework of this post, we will call them “connected areas”.
- We calculate the global parameters of the algorithm, for example, the median height and width of the symbol.
Next, we run the algorithm recursively, starting from the entire page:
- We are looking for how to divide the block with a vertical or horizontal cut.

- If we could, we divide and recursively run the division of each of the parts.
- If we couldn't, we stop.
Regarding the point about how to divide the block. Two methods are proposed - either along a white gap (it can be found on the projection of the block onto the horizontal or vertical axis, respectively) or along a long and fairly well-isolated black straight line.
The result of all these divisions is a tree structure, as in the bottom right of the figure:
The authors of the original article seem to consider this tree representation to be their main merit. They also noticed that even for a “Manhattan” document it is possible that this algorithm will not achieve the goal: for example, if the blocks are located like this
Frankly speaking, this is not the most common configuration even for newspapers, not to mention magazines and documents. But it happens, in the newspapers for sure.
A more serious problem of the algorithm is its compliance with thresholds. Let's say on such a fragment it will be difficult to separate the title from the text without tearing the title:
Let's say on such a fragment it will be difficult to separate the title from the text without tearing the title:
And here it will be quite difficult to separate the image from the text, relying only on the distance thresholds:
of the problem algorithms presented in this post - how not to tear off the numbering from the numbered list and how to get rid of the restrictions that I indicated at the beginning (that there is only text and high-contrast pictures).
Segmentation using maximum white boxes
Now let's talk about the idea of segmenting the page using the maximum white rectangles. What is "maximum white rectangle"? White - this means that there are no black dots in it (it is clear that the image must first be rid of small debris). Maximum - means that it cannot be increased either to the left or to the right, neither up nor down so that it remains white. In what follows, instead of black dots, we will consider connected regions. As in recursive sections, we can somehow group them, but again we will not dwell on this. It is clear that for almost every scanned page there are tens of thousands of such white rectangles. But for segmentation purposes, only the largest ones may be required. The algorithm for their search is proposed in the article by Thomas M. Breuel. Two Geometric Algorithms for Layout Analysis
As in recursive sections, we can somehow group them, but again we will not dwell on this. It is clear that for almost every scanned page there are tens of thousands of such white rectangles. But for segmentation purposes, only the largest ones may be required. The algorithm for their search is proposed in the article by Thomas M. Breuel. Two Geometric Algorithms for Layout Analysis
By the way,
the second algorithm of these “two” selects the lines between these white separators, but I don’t think it is particularly outstanding, if anyone is interested, see the article.
Let's return to the problem of finding the maximum white rectangles. You can introduce the concept of "quality" for a rectangle.
Let's call the quality function Q( r ) for the rectangle r monotonic , if Q(r1) <= Q(r2) is satisfied for r1 ⊆ r2 — that is, if one rectangle lies inside another, then the quality of the inner cannot be greater than the quality external. You can think of a lot of monotonous qualities. The area is good. perimeter is fine. The square of the height plus the square of the width is fine. In general, what fantasy is enough.
You can think of a lot of monotonous qualities. The area is good. perimeter is fine. The square of the height plus the square of the width is fine. In general, what fantasy is enough.
If the quality is monotonous, then we apply the following algorithm, finding the maximum white rectangles, in descending order of quality.
- Set up a priority queue for rectangles. Priority equals quality.
- Enqueue the entire page rectangle. He's definitely the first.
Next in the loop:
- Get the rectangle out of the queue. If it is empty, then this is another maximum white rectangle found.
- If not, select one “reference” area from the connected areas in the rectangle under study (similar to the median in QSort). Here it is better not to rely on chance, but to consciously choose something more central.
- Note that the maximum white rectangle can be either completely above this area, or completely below it, or to the right of it or to the left (green rectangles in the figure below).
- Add green rectangles to the queue.
The condition for exiting the loop can be either a sufficient number of found rectangles, or the quality of the current rectangle taken from the queue ... That's enough imagination.
Well, we have found the maximum white rectangles. Let's see what we can do with them.
In the same article, Thomas M. Breuel does not bother much about this topic and writes that the whole analysis is done in four steps:
- Find all the highest maximum white rectangles and evaluate them as candidates for inter-column separators
- Find rows according to found column structure
- Looking at found lines, find paragraphs, heading structure, footers
- Restore reading order using both geometric and linguistic information
Further in the paper, some reasonable considerations are mentioned on how exactly white rectangles should be classified. I admit that there are not so many shortcomings in the evaluation function - here we are more likely to run into the limitations of the method than the incorrectness of the estimate.
A slightly different approach is described by Henry Baird in his Background structure in document images. This paper describes a very interesting algorithm, but the implementation of some functions leaves the feeling that they are specially “fine tuned” on a specific experimental basis. So, it is proposed to place all found maximum white rectangles in a priority queue. I will not give a specific priority function, you can look at it in the work. It is intuitively clear that the larger the area of the rectangle and the higher the rectangle, the higher the priority should be.
Next, we remove rectangles from this queue in order to place some of them in a special list L. We apply a trimming rule to each removed rectangle: if this rectangle intersects with some elements of the list L, then we subtract from it already processed and that left, put it back in the queue. Otherwise, we add it to the list L. The condition for exiting the loop is somehow too tricky (I would just indicate the priority threshold, but the authors have it more complicated).
Cut out all the rectangles of the list L from the page. We declare the remaining connected areas on the image as ready-made text or picture blocks.
As a short summary of the maximum white rectangles, the maximum white rectangle is a very important concept, extremely useful for solving the page segmentation problem. According to an experiment from SKB, both algorithms presented here perform better than both recursive sections and Smearing. Another thing is that in the given algorithms the question is “hushed up” even with pictures, not to mention more complex concepts
We have analyzed several algorithms for "Manhattan" documents. But what if we come across a document like this:
Well, with this one, the answer is quite simple - it's not a document at all, but just wallpaper in my toilet, so what exactly the document processing program does with this picture is not so important.
Seriously speaking, the "non-Manhattan" layout is not so exotic, it can be found in newspapers and magazines, and sometimes even in books. Here's a typical newspaper example:
Here's a typical newspaper example:
Below we'll look at two algorithms that can handle "non-Manhattan" documents as well.
Docstrum
The word Docstrum is formed according to the Carroll productive model portmanteau word - by gluing the words Document and Spectrum (I love this model, by the way) and denotes the segmentation algorithm for "non-Manhattan" documents. O'Gorman described it in his article The document spectrum for page layout analysis in 1993. The method itself was invented for pages that were not perfectly flat on the scanner, but at a slight angle. Let's describe how this algorithm works.
To begin with, we will prepare the page by removing small garbage and large obviously non-text objects (well, or let's pretend that there are no pictures on the pages - is it the first time?). We believe that all that is left on the page is the letters. We cluster these letters by size (the author suggested exactly two clusters, but those who used this method tried three, and four, and even more). Let's look at the distances from each letter to k (usually take k equal to 4 or 5) nearest neighbors from the same cluster. Let's write down the distances in the histogram. Let's look at the first three peaks of the histogram. It is argued that the smallest peak is the distance between letters in a word, the second is the line spacing, and the third is a space. If you use this assumption, then you can correct the skew, by the way.
Let's look at the distances from each letter to k (usually take k equal to 4 or 5) nearest neighbors from the same cluster. Let's write down the distances in the histogram. Let's look at the first three peaks of the histogram. It is argued that the smallest peak is the distance between letters in a word, the second is the line spacing, and the third is a space. If you use this assumption, then you can correct the skew, by the way.
To segment the page, we make a transitive closure on close components - we combine words inside lines and close lines with each other, we get ready-made blocks.
In addition to being positioned as working with "non-Manhattan" documents, this method explicitly uses an important idea. I mean the property that the distance thresholds on which our decision depends (put two words in one block or not) are chosen depending on the height of the words. This means that this method has at least some chance to regularly cope with the “over-segmenting of large fonts” problem repeatedly mentioned by researchers.
On the other hand, and here the authors deftly hushed up the question of what to do with pictures and more complex objects. Yes, and other shortcomings of the idea to rely only on thresholds by distance, we have already discussed above.
Voronoi diagram
The Voronoi diagram is an interesting object that is built from an arbitrary set of points in the plane (in our case, from the centers of the letters). The points on which the Voronoi diagram is built will be called here reference points . It is a partition of the plane into regions; each region corresponds to one reference point and is the set of plane points for which this reference point is closer than any other reference point. For more information about the Voronoi diagram and its connection with another interesting object - the Delaunay triangulation, the easiest way is to read the links to Wikipedia.
It is worth reading about how they can be built in the excellent book by A. V. Skvortsov "Delaunay triangulation and its application". I will talk about the 1998 article by K. Kise, A. Sato, and M. Iwata. Segmentation of page images using the area voronoi diagram. That is, about how the Voronoi diagram was applied to solving the segmentation problem. By the way, today this method is considered the “scientific standard”, until science has proposed an algorithm that would be recognized as better than this one. And in SKB, the authors write that the Voronoi diagram is noticeably ahead in quality of both white rectangles, and Docstrum, and recursive sections.
V. Skvortsov "Delaunay triangulation and its application". I will talk about the 1998 article by K. Kise, A. Sato, and M. Iwata. Segmentation of page images using the area voronoi diagram. That is, about how the Voronoi diagram was applied to solving the segmentation problem. By the way, today this method is considered the “scientific standard”, until science has proposed an algorithm that would be recognized as better than this one. And in SKB, the authors write that the Voronoi diagram is noticeably ahead in quality of both white rectangles, and Docstrum, and recursive sections.
So, with a familiar gesture, we clear the image of garbage (that's it, for the last time in this post, we'll pretend that it's really so easy to do), declare the centers of the remaining connected areas as reference points and build a Voronoi diagram based on them. Then we mark which of the chart cells should be merged. We merge cells in two cases:
- Or the distance d between reference points (centers of connected components) is less than the threshold T1.
 Threshold T1 is selected in such a way that this rule deals with the union of adjacent letters in words
Threshold T1 is selected in such a way that this rule deals with the union of adjacent letters in words - Or, for d, the following relation holds: d/T2+ar/Ta<1 where ar is the ratio of the area of the larger connected area to the area of the smaller one (i.e. ar >= 1), and T2 and Ta are two more thresholds. The meaning of this condition is that you should merge two words in a line, but if these two words have different heights, then you need to merge cells with more care.
After we have found all the cells that need to be combined, we combine them - and the Voronoi diagram turns into a finished segmentation.
In the future, various researchers tried to improve the performance of the Voronoi diagram. For example, in the 2009 article Voronoi++: A Dynamic Page Segmentation approach based on Voronoi and Docstrum features, the authors M. Agrawal and D. Doermann tell how to use Docstrum and other strange magic to pick up the T2 threshold more accurately and more accurately.