Letter recognition definition
Why Recognition of Letters is Important
Recognition of letters is a fundamental part of learning how to read. Without it, children struggle learning letter sounds and recognizing words. Children who cannot recognize letter and name them with their sounds have difficult learning how to read.
Learn more about what letter recognition is and how to develop letter recognition skills in preschoolers.
Letter Recognition Activities and Why Recognition of Letters is Important
Beginning reading instruction has an extensive history of beginning with recognition of letters. The very first schoolbooks brought to America from England, called The Protestant Tutor, started with the teaching the letters of the alphabet, as did the first reading books produced here (
New England Primer).
They were not off-base.
Research has long supported the approach to teach reading with letter recognition. The fact is that beginning readers’ knowledge of the alphabet is a strong predictor of later reading success.
The National Early Literacy Panel (NELP) meta-analyzed 52 such studies that had connected alphabetic knowledge, (including letter recognition and sounds generation), with the later decoding ability of 7,570 kids and found a strong relationship between the two.The more letter names the kids knew, the greater their later success in decoding.
What is Letter Recognition?
Letter recognition is the ability to name letters, identify characteristics specific to said letter, and letter formation of all 26 uppercase and lowercase letter symbols used in the English language. That’s 52 letters total.
Letter recognition includes being able to differentiate between different letters and their shapes, and should be taught before, or at the very least, in conjunction with letter sounds.
This means that letter recognition skills are important and should not be passed over for letter sound practice! Children need to know letter names as well as letter sounds to experience ease in learning how to read.
More About Why Letter Recognition is Important
There are many reading skills that are regularity evaluated as predictors of reading success. Letter recognition ranks among the top predictors.
Upon entering school, children come with a range of skill levels and an even wider range of letter knowledge. Most have some experience with the alphabet through singing the alphabet song. Other kindergarteners can spell their names or recognize environmental print.
In order to have true fluency in letter recognition, children must be able to identify letters and say their names in and outside of context and in and out of sequence. It’s not just accuracy, but also automaticity, which is being able to be accurate and fast at the same time, which contributes to later reading success.
In addition, research has shown that learning letters and playing with letters frequently leads to an interest in their sounds and in reading. Many letter names share an auditory link with their sounds, thus effectively doing double duty as it helps bridge the gap between phonemic awareness and letter recognition to other phonics skills.
How to Teach Letter Recognition in Preschool
There are a couple of important strategies to utilize when teaching letter recognition in preschool.
- Explicit instruction in letter naming
- Sorting activities to differentiate letter shapes
- Letter formation
- Exposure to letters in a variety of text formats
- Fluency practice in letter identification
- Fluency and accuracy assessments
When planning letter recognition activities in the preschool classroom, keep in mind the following.
- Preschool children have a wide range of skills and abilities.
- Preschoolers may not all be ready to learn letter names at the same time, and never stay the same rate as their peers.
- Use visuals, such as alphabet cards and beginning sound cards.
- Practice “think aloud” strategies, which means to talk out-loud about the things you want your preschoolers to know and notice about each letter
There are several guidelines to follow when determining an instructional sequence for teaching letter recognition.
Keep in mind that the suggestions below refer only to letter naming and letter identification, not to teaching sound spellings.
Prerequisite Skills for Letter Recognition
- Even before letter recognition, there are a few other skills that should be taught.
- Teach visual discrimination. This helps preschoolers learn to identify differences among lines and shapes. Visual discrimination can be taught in isolation and in “what’s different” or “what’s the same” activities.
- Find visual discrimination activities here, here, and here.
- Practice visual discrimination in the alphabet by sorting letters based on shape. Straight lines, versus curved. Tall letters versus short, etc. Letters versus numbers and symbols.
What Order to Teach Recognition of Letters
- Teach high-frequency letters first. This means that it’s not necessary to teach letters in alphabetical order.
- Letters with higher frequency will have more meaning and allow more opportunities for preschoolers to practice letter recognition skills in various text contexts.

- Separate letters that are visually confusing. For example, if your preschooler is struggling with letters G and O, don’t teach them at the same time.
- Once letters have been mastered in isolation, provide sorting activities for additional comparison and practice.
- If your preschooler has a mature pencil grasp, teach letter formation in conjunction with letter recognition.
- When possible, teach letters that are simpler to print, often those with straight lines, before more complex letters.
Want to Know More about Teaching Letter Recognition to Preschoolers?
Take all the guesswork out of it and grab the free download of my literacy scope and sequence for preschool.
This scope and sequence will show you exactly what literacy skills I teach my preschoolers and in what order for the entire school year.
Grab your FREE copy by clicking the image below.
Get Done-For-You Preschool Lesson Plans
Ever wondered what it feels like to cut your preschool lesson planning down to a fraction of the time while still being an effective teacher? Grab my preschool literacy lesson plans! They systematically lay out daily activities so you never have to go searching for the right activity to teach your preschoolers.
It’s all done for you here. Just print and teach!
Choose from both literacy and math.
And you can grab just the literacy centers, too. These feature more than ten letter recognition, beginning sounds, and letter formation printable centers!
Or save by grabbing The Complete Preschool Curriculum below!
Sarah Punkoney, MAT
I’m Sarah, an educator turned stay-at-home-mama of five! I’m the owner and creator of Stay At Home Educator, a website about intentional teaching and purposeful learning in the early childhood years. I’ve taught a range of levels, from preschool to college and a little bit of everything in between. Right now my focus is teaching my children and running a preschool from my home. Credentials include: Bachelors in Art, Masters in Curriculum and Instruction.
stayathomeeducator.com/
Understanding Letter Recognition and It’s Role in Preliteracy
Spread the love
Understanding Letter Recognition and Its Role in Preliteracy
Letter recognition is the capacity to call out a letter shown or pick out a letter in a group of letters. Recognition of letters is a foundational part of learning how to read. Without it, kids struggle to learn letter sounds and recognizing words. Children who cannot identify letters and name them with their sounds have difficulty learning how to read.
Recognition of letters is a foundational part of learning how to read. Without it, kids struggle to learn letter sounds and recognizing words. Children who cannot identify letters and name them with their sounds have difficulty learning how to read.
What is Letter Recognition?
Letter identification is the ability to name letters, find characteristics specific to the said letter, and letter formation of all 26 uppercase and lowercase letter symbols used in the English language. That’s 52 letters in total. Letter identification includes being able to differentiate between distinct letters and their shapes and should be taught before, or at the very least, in conjunction with letter sounds.
This means that letter identification skills are essential and should not be passed over for letter-sound practice! Children need to know letter names and letter sounds to ease learning how to read.
Why Letter Recognition is Essential
Many reading skills are regularly assessed as predictors of reading success. Letter identification ranks among the top predictors. Upon entering school, kids come with a range of skills and an even wider range of alphabetic knowledge. For instance, they may have experience with the alphabet by singing the alphabet song. Other kindergarteners can spell their names or identify environmental print.
Letter identification ranks among the top predictors. Upon entering school, kids come with a range of skills and an even wider range of alphabetic knowledge. For instance, they may have experience with the alphabet by singing the alphabet song. Other kindergarteners can spell their names or identify environmental print.
To have true fluency in letter identification, kids must find letters and say their names in and outside of context. It’s not the only accuracy but also automaticity, that is, being accurate and fast simultaneously, which leads to later reading success.
Research has also shown that learning letters and playing with letters often leads to an interest in their sounds and reading. Most letter names share an auditory link with their sounds, thus efficiently doing double duty. It helps bridge the gap between phonemic awareness and letter identification to other phonics skills.
Teach Lettering Recognition to Preschoolers
There are a couple of essential strategies to utilize when teaching letter identification in preschool.
- Instruction in letter naming
- Sorting activities to recognize letter shapes
- Letter creation and formation
- Exposure to letters in several text formats
- Fluency practice in letter identification
- Fluency and accuracy assessments
When planning letter identification activities in the preschool class, keep in mind the following.
- Preschool kids have a wide range of skills and capabilities.
- Preschool kids may not all be ready to learn letter names simultaneously and never remain at the same rate as their peers.
- Leverage visuals, like alphabet cards and beginning sound cards.
- Practice “think aloud” strategies, which means to talk out loud about the things you want your kids to know and notice about each letter.
Letter Sequence Does Not Have to Be Taught in Alphabetical Order
There are guidelines to follow when determining a teaching sequence for teaching letter identification. Keep in mind that the suggestions below refer only to the letter naming and letter identification, not teaching sound-spellings.
Keep in mind that the suggestions below refer only to the letter naming and letter identification, not teaching sound-spellings.
Necessary Skills for Learning Letter Recognition
Even before letter identification, there are a few other skills that should be taught. Teach visual discrimination. This helps kids learn to find differences among lines and shapes. Visual discrimination can be taught in isolation and in “what’s different” or “what’s the same” activities.
Practice visual discrimination in the alphabet by sorting letters based on shape. Straight lines, versus curved. Tall letters versus short, etc. Letters versus numbers and symbols.
More on Teaching the Recognition of Letters
Teach high-frequency letters first. This means that it’s not necessary to teach letters in alphabetical order. Letters with higher frequency will have more meaning and allow kids to practice letter identification skills in various text contexts.
Separate letters that are visually confusing. For instance, if your preschooler struggles with the letters G and O, don’t teach them at the same time. Once letters have been learned in isolation, provide sorting activities for additional comparison and practice.
If a preschooler has a mature pencil grasp, teach letter formation in conjunction with letter identification. When possible, teach letters that are simpler to print, often those with straight lines, before more complex letters.
What is optical character recognition? — AWS
What is OCR?
Optical Character Recognition (OCR) is the process of converting an image of text into a machine-readable text format. For example, when scanning a letterhead or receipt, the computer saves the scan as an image file. A text editor cannot be used to edit, search, or count words in an image file. OCR helps convert an image into a text document, the content of which is stored as text data. nine0005
Why is OCR important?
Most work processes are related to obtaining information from printed publications. Any business process involves forms, invoices, scanned legal documents and contracts printed on paper. Such large volumes of paperwork require a lot of time and space to store and process. While paperless workflow is the way forward, scanning a document to an image presents some challenges. This process requires manual intervention and can be tedious and slow. nine0005
Any business process involves forms, invoices, scanned legal documents and contracts printed on paper. Such large volumes of paperwork require a lot of time and space to store and process. While paperless workflow is the way forward, scanning a document to an image presents some challenges. This process requires manual intervention and can be tedious and slow. nine0005
Digitizing document content creates image files with text hidden in them. Word processing programs cannot process text in images. OCR solves this problem by converting the image into text data that can be parsed by office software. This data can then be used for analytics, operations optimization, process automation, and performance improvement.
How does OCR work?
OCR technology includes the following steps:
Image acquisition
The scanner reads documents and converts them to binary data. The OCR software analyzes the scanned image and classifies light areas as background and dark areas as text.
Preprocessing
To prepare text for recognition, OCR software cleans up the image and removes error areas. The following cleaning methods are used:
- Straighten and deskew the scanned document for easier recognition. nine0026
- Smoothes out contrast or blemishes in a digital image and smooths out the edge effects of text images.
- Erases frames and lines on a scanned image.
- Font recognition for multilingual OCR technology
OCR
There are two main types of OCR algorithms or software processes that OCR software uses for OCR: pattern matching and feature extraction. nine0005
Pattern matching
Pattern matching works by extracting an image of a character, called a glyph, and comparing it to a similar glyph stored in memory. Image recognition will only occur if the font and scale of the stored glyph matches the font and scale of the scanned glyph. This method is effective when working with scans of documents typed in a known font.
This method is effective when working with scans of documents typed in a known font.
Feature Extraction
Feature Extraction breaks or decomposes glyphs into features such as lines, closed paths, line direction, and line intersections. The features are then used to find the best or closest match among the various stored glyphs. nine0005
Finishing
After analysis, the system converts the extracted text data into a computer file. Some OCR systems can create annotated PDFs that include both the previous and next versions of the scanned document.
What types of OCR are there?
Data scientists classify different kinds of OCR technologies based on their use and application. The following are just a few examples:
Simple OCR programs
The simple OCR engine uses many different stored font patterns and text images as templates. OCR software uses pattern matching algorithms to compare text images character by character against an internal database. The approach in which the system matches text word by word is called optical word recognition. It has its limitations as there is an almost unlimited number of fonts and handwriting styles and every single type cannot be accounted for and stored in the database. nine0005
The approach in which the system matches text word by word is called optical word recognition. It has its limitations as there is an almost unlimited number of fonts and handwriting styles and every single type cannot be accounted for and stored in the database. nine0005
Intelligent Character Recognition
Modern OCR systems use Intelligent Character Recognition (ICR) technology to read text just like a human. They use advanced machine learning techniques for human reading skills. A machine learning system called a neural network analyzes text at many levels by repeatedly processing the image. It looks for various image attributes (curves, lines, intersections, and loops) and combines the results of various levels of analysis to arrive at the final result. Even though ICR processes images character by character, the process does not take much time, and the results are obtained in a matter of seconds. nine0005
Intelligent Word Recognition
Intelligent Word Recognition systems work on the same principle as ICR, but process images of whole words without first extracting the characters in the image.
OCR
OCR allows you to identify logos, watermarks, and other designations in your document.
What are the main benefits of OCR?
Data scientists classify different kinds of OCR technologies based on their use and application. Below are just a few examples:
Simple OCR programs
The simple OCR engine uses many different stored font patterns and text images as templates. OCR software uses pattern matching algorithms to compare text images character by character against an internal database. The approach in which the system matches text word by word is called optical word recognition. It has its limitations as there is an almost unlimited number of fonts and handwriting styles and every single type cannot be accounted for and stored in the database. nine0005
Intelligent Character Recognition
Modern OCR systems use Intelligent Character Recognition (ICR) technology to read text just like a human. They use advanced machine learning techniques for human reading skills. A machine learning system called a neural network analyzes text at many levels by repeatedly processing the image. It looks for various image attributes (curves, lines, intersections, and loops) and combines the results of various levels of analysis to arrive at the final result. Even though ICR processes images character by character, the process does not take much time, and the results are obtained in a matter of seconds. nine0005
A machine learning system called a neural network analyzes text at many levels by repeatedly processing the image. It looks for various image attributes (curves, lines, intersections, and loops) and combines the results of various levels of analysis to arrive at the final result. Even though ICR processes images character by character, the process does not take much time, and the results are obtained in a matter of seconds. nine0005
Intelligent Word Recognition
Intelligent Word Recognition systems work on the same principle as ICR, but process images of whole words without first extracting the characters in the image.
OCR
OCR allows you to identify logos, watermarks, and other designations in your document.
What are the main benefits of OCR?
The main advantages of OCR technology are listed below:
Searchable text
Businesses can transform existing and new documents into a fully searchable knowledge base. Software for automatic processing of text base allows you to improve the knowledge base of the enterprise.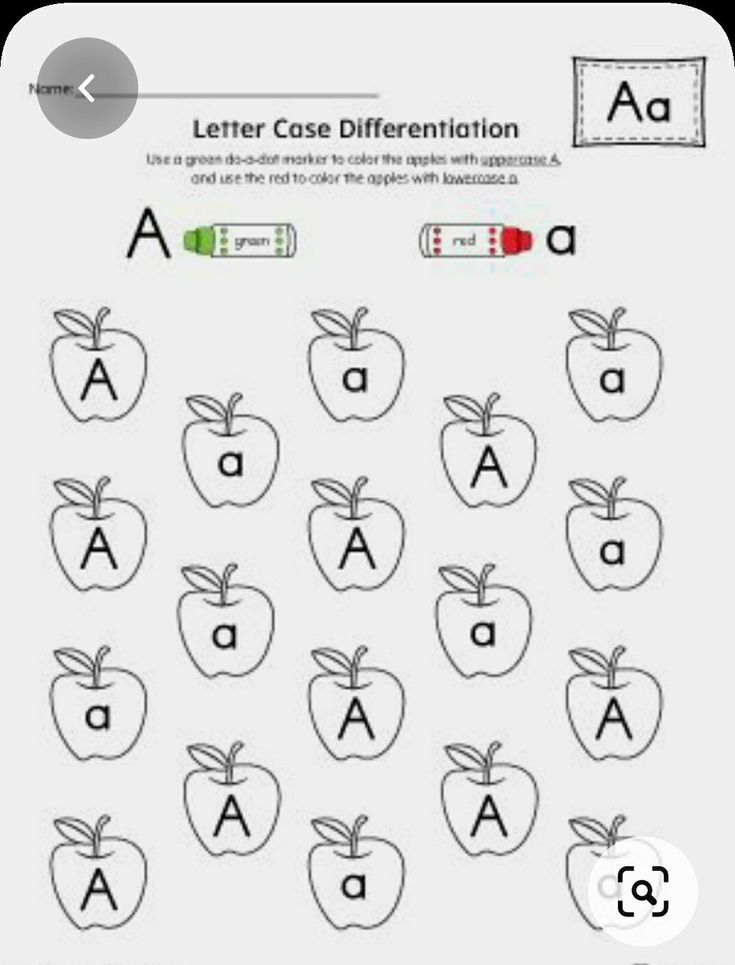
Work efficiency
OCR software improves work efficiency by automatically integrating workflow and digital workflows. Here are some examples of what OCR software can do:
- Scanning of manually completed forms for automated review, review, editing and analysis. This approach reduces the time of manual processing of documents and data entry.
- Finding the required documents using a quick search for a term in the database, instead of manually sorting through the files in the box.
- Convert handwritten notes to editable text and documents.
Artificial intelligence solutions
OCR is often a component of other AI solutions that enterprises may implement. For example, OCR can be used to scan and recognize license plates and road signs in self-driving cars, identify brand logos in social media posts, or identify product packaging in promotional images. These AI technologies help businesses make better marketing and operational decisions that reduce costs and improve the customer experience. nine0005
nine0005
What is OCR used for?
Some common use cases for OCR across industries are listed below:
Banking
The banking industry uses OCR to process and validate loan documents, deposit checks, and other financial transactions. Such verification allowed to increase the effectiveness of the fight against fraud and strengthen the security of transactions. For example, BlueVine, a financial technology company that provides financing to small and medium-sized businesses, used Amazon Textract, an OCR cloud service, to develop a product that allows small businesses in the United States to quickly access Payroll Protection Program (PPP) loans under COVID-19 stimulus package. Amazon Textract automatically processed and analyzed tens of thousands of PPP forms per day, enabling BlueVine to help several thousand businesses raise funds and save more than 400,000 jobs.
Healthcare
In the healthcare system, OCR is used to process patient records, including treatments, tests, hospital records, and insurance payments. OCR helps streamline workflow, reduce manual work in hospitals, and keep records up-to-date. For example, the nib Group provides health insurance to more than 1 million Australians and receives thousands of health claims every day. The company's customers can take a photo of their medical bill and submit it via the nib mobile app. Amazon Textract automatically processes these images, allowing the company to review applications much faster. nine0005
OCR helps streamline workflow, reduce manual work in hospitals, and keep records up-to-date. For example, the nib Group provides health insurance to more than 1 million Australians and receives thousands of health claims every day. The company's customers can take a photo of their medical bill and submit it via the nib mobile app. Amazon Textract automatically processes these images, allowing the company to review applications much faster. nine0005
Logistics
Logistics companies use OCR to more efficiently track package labels, invoices, receipts and other documents. For example, Foresight Group uses Amazon Textract to automate invoice processing in SAP. Entering such documents manually was time consuming and error prone as Foresight employees had to enter data into multiple accounting systems. Amazon Textract has enabled Foresight's software to more accurately read characters across a variety of media and improve the efficiency of the company's business. nine0005
How can AWS help with OCR?
AWS offers two services that can help you implement OCR in your business:
Amazon Textract is a machine learning (ML) service that uses OCR to automatically extract printed and handwritten text and data from scanned documents (such as PDFs) . The service allows you to quickly read thousands of different documents of various media and formats. After extracting information from documents, Amazon Textract assigns a level of confidence, which enables you to make informed decisions about how to use the results. nine0005
The service allows you to quickly read thousands of different documents of various media and formats. After extracting information from documents, Amazon Textract assigns a level of confidence, which enables you to make informed decisions about how to use the results. nine0005
Amazon Rekognition can analyze millions of images and videos in minutes and augment human visual inspection tasks with artificial intelligence. You can use the Amazon Rekognition API to extract text from images and videos. It has the ability to recognize garbled and warped text from road sign images and videos, social media posts, and product packaging.
Create an AWS account and get started with OCR technology today. nine0005
From pixels to letters: how OCR works
What is OCR?
OCR (eng. optical character recognition , optical character recognition) is a technology for automatically analyzing text and turning it into data that a computer can process.
When a person reads a text, he recognizes the characters with the help of his eyes and brain. For a computer, the scanner camera acts as an eye, which creates a graphic image of a text page (for example, in JPG format). For a computer, there is no difference between a photo of text and a photo of a house: both are a collection of pixels. nine0005
It is OCR that turns an image of text into text. And you can do anything with the text.
How does it work?
Imagine there is only one "A" in the alphabet. Will this make the task of converting an image to text easier? No. The fact is that each letter (and any other grapheme) has allographs - different styles.
Variants of the letter "a". A person will easily understand that all this is the letter "A". For a computer, there are two ways to solve the problem: to recognize characters as a whole (pattern recognition) or to highlight the individual features that make up a character (feature detection). nine0005
nine0005
Pattern recognition
In the 1960s, a special OCR-A font was created for use in documents such as bank checks. Each letter in it was the same width (the so-called fixed-width font or monospace font).
Sample font OCR-AReceipt printers worked with this font and software was developed to recognize it. Since the font has been standardized, recognizing it has become a relatively easy task. The next step was to train OCR programs to recognize characters in several more common fonts ( Times, Helvetica, Courier , etc.).
Sign detection
This method is also called intelligent character recognition (eng. intelligent character recognition, ICR ). Imagine that you are an OCR program that has been given many different letters written in different fonts. How do you select all the letters "A" from this set, if each of them is slightly different from the other?
You can use the following rule: if you see two lines converging at the top in the center at an angle, and in the middle between them a horizontal line, then this is the letter "A". This rule will help recognize all the letters "A" regardless of the font. Instead of pattern recognition, the characteristic individual features that make up the symbol are highlighted. Most modern omnifont (able to recognize any font) OCR programs work on this principle. Most often, they use classifiers based on machine learning (since, in fact, we are faced with the task of classifying images by letter classes), recently some OCR engines have switched to neural networks. nine0005
This rule will help recognize all the letters "A" regardless of the font. Instead of pattern recognition, the characteristic individual features that make up the symbol are highlighted. Most modern omnifont (able to recognize any font) OCR programs work on this principle. Most often, they use classifiers based on machine learning (since, in fact, we are faced with the task of classifying images by letter classes), recently some OCR engines have switched to neural networks. nine0005
What to do with handwriting?
A person is able to guess the meaning of a sentence, even if it is written in the most illegible handwriting (unless it is a prescription for drugs, of course).
The task for the computer is sometimes simplified. For example, people are asked to write the zip code in a special place on the envelope in a special font. Forms created for further processing by a computer usually have separate fields that require you to fill in capital letters.
Tablets and smartphones that support handwriting often use the principle of feature detection. When writing the letter "A", the screen "feels" that the user first wrote one line at an angle, then another, and finally drew a horizontal line between them. The computer is helped by the fact that all signs appear sequentially, one after another, in contrast to the option when all the text is already written by hand on paper.
When writing the letter "A", the screen "feels" that the user first wrote one line at an angle, then another, and finally drew a horizontal line between them. The computer is helped by the fact that all signs appear sequentially, one after another, in contrast to the option when all the text is already written by hand on paper.
OCR by steps
Pretreatment
The better the quality of the original text on paper, the better the recognition quality will be. But the old font, coffee or ink stains, paper creases reduce the chances.
Most modern OCR programs scan a page, recognize the text, and then scan the next page. The first stage of recognition is to create a copy in black and white or in shades of gray. If the original scanned image is perfect, then all black is the characters and all white is the background. nine0005
Recognition
Good OCR programs automatically mark difficult page structure elements such as columns, tables, and pictures. All OCR programs recognize text sequentially, character by character, word by word, and line by line.
All OCR programs recognize text sequentially, character by character, word by word, and line by line.
First, the OCR program combines pixels into possible letters and letters into possible words. The system then matches word variants with the dictionary. If a word is found, it is marked as recognized. If the word is not found, the program provides the most likely option and, accordingly, the recognition quality will not be as high. nine0005
Postprocessing
Some programs allow you to view and correct errors on each page. To do this, they use the built-in spell checker and highlight misspelled words, which may indicate incorrect recognition. Advanced OCR programs use a so-called neighbor search method to find words that often occur side by side. This method allows you to correct the misrecognized phrase "melting dog" to "barking dog". nine0005
In addition, some projects that are engaged in digitization and recognition of texts resort to the help of volunteers: recognized texts are laid out in the public domain for proofreading and checking recognition errors.
Special cases
For high accuracy of recognition of historical text with unusual graphic characters that differ from modern fonts, it is necessary to extract the corresponding images from documents. For languages with a small character set, this can be done manually, but for languages with complex writing systems (such as hieroglyphics), manual collection of this data is not practical. nine0005
To recognize historical Chinese texts, you need to enter at least 3000 characters in the OCR program, which have different frequencies. If manual marking of several tens of pages is sufficient for recognition of historical English texts, then a similar process for Chinese will require the analysis of tens of thousands of pages.
At the same time, many historical Chinese scripts have a high degree of similarity with modern writing, so character recognition models trained on modern data can often give acceptable results on historical data, albeit with reduced accuracy. This fact, together with the use of corpora, makes it possible to create a system for recognizing historical Chinese texts. For this, researcher D. Stegen ( Donald Sturgeon ) from Harvard processed two corpus: a corpus of transcribed historical documents and a corpus of scanned documents of the desired style.
This fact, together with the use of corpora, makes it possible to create a system for recognizing historical Chinese texts. For this, researcher D. Stegen ( Donald Sturgeon ) from Harvard processed two corpus: a corpus of transcribed historical documents and a corpus of scanned documents of the desired style.
After image pre-processing and character segmentation steps, the training data extraction procedure consisted of:
1) applying a character recognition model trained exclusively on modern documents to historical documents to obtain an intermediate OCR result with low accuracy; nine0108 2) using this intermediate result to match the image with its probable transcription;
3) extracting markup character images based on this mapping;
4) selection of appropriate training examples from marked symbols.
The obtained data can be used without validation to train a new character recognition model, which allows to achieve higher accuracy on similar material.