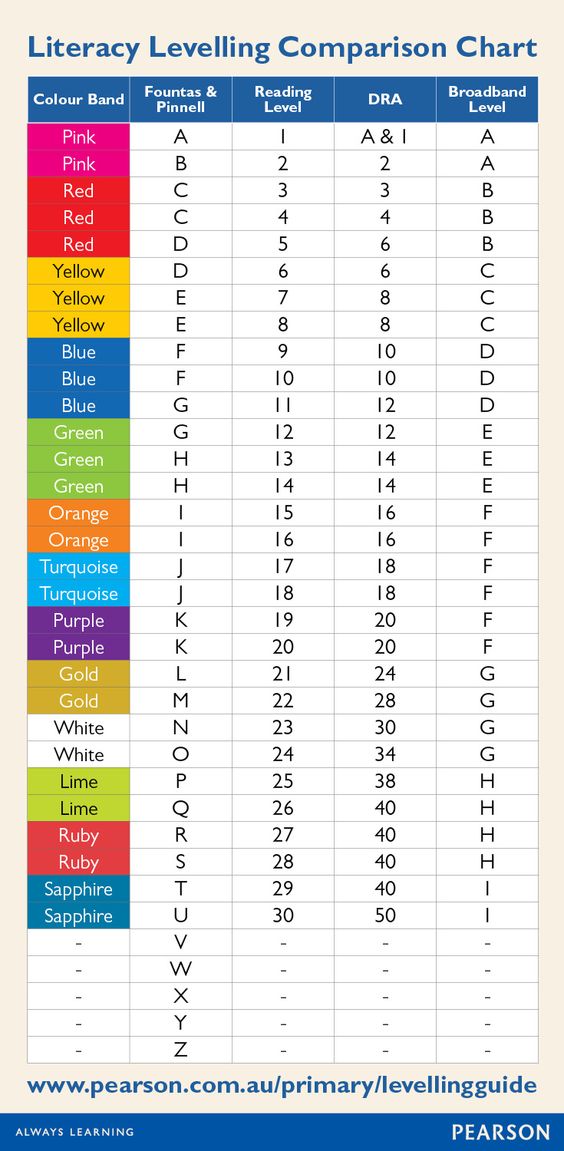
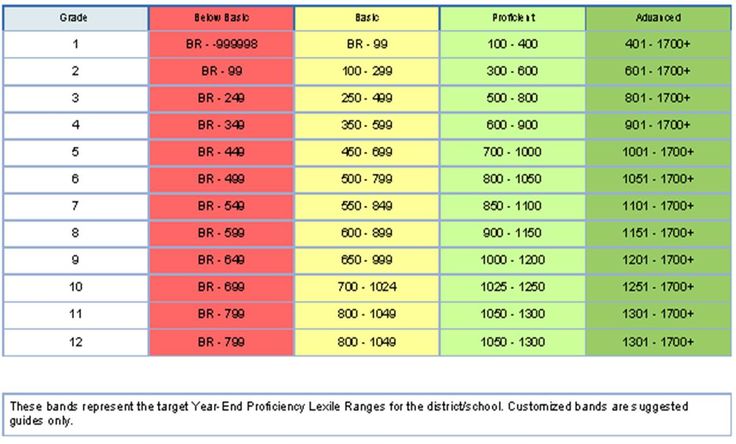
Lexile level checker
Free Lexile Analyzer®
This guide provides an overview for how to use all subscriptions to the Lexile Analyzer® including the Professional Lexile Analyzer® and the Lexile Analyzer® Editor Assistant™. The Lexile Analyzer® is used to evaluate the text complexity of books, articles, passages, and other texts to report its reading demand as a Lexile® text measure. The Lexile Analyzer® is a web-based tool that determines the Lexile® measure of professionally edited, complete, conventional prose text. The accuracy of the Lexile® measures produced from the Lexile Analyzer® depends on your following the text-preparation procedures and formatting conventions detailed in this guide.
A couple of things to note...
- Lexile text measure vs Lexile student measure: A Lexile reader measure is a measure of a student's reading ability.
A Lexile text measure is a measure of the text complexity for a book or piece of text. A Lexile text measure only offers information about text complexity, not the reading ability of a student. To determine student reading ability, a Lexile-linked assessment must be administered. Lexile text measures may not be used to determine the reading abilities of students.
- Use of Lexile Measures Produced from the Lexile Analyzer: We offer the Lexile Analyzer as a tool to help educators, publishers, content developers, and researchers gauge the reading demands of materials. The Lexile measures produced by your use of the Lexile Analyzer are not certified by MetaMetrics® (developer of Lexile Framework) and should not be publicly shared. Lexile measures produced by your use of the Lexile Analyzer are not for commercial use. Please remember:
- You may not publish or distribute the Lexile measure.
- You may not enter the Lexile into a library or media center database or catalog.
- Your Lexile measure is not a certified Lexile measure of that book or text.
- You may not publish or distribute the Lexile measure.
- Getting Started
- What Texts Can Receive a Lexile Measure?
- Text Preparation Guidelines
- Text Preparation Considerations
- For Children's Books
- Web Resources
- Tests and Assessments
- Using the Lexile Analyzer
- Step 1: Make Sure Words and Sentences Are Recognizable
- Step 2: Prepare Your Text for Lexile Analysis
- Step 3: Convert Your Text for Lexile Analysis
- Step 4: Analyze Your File
- Step 5: View Your Results
- Lexile Usage Conventions
- FAQ
- How do I find the Lexile measure of a book that has been measured?
- How does a book receive a Lexile measure?
- How do books receive Lexile certified measures?
- How does the Lexile Analyzer work?
- What type of editorial errors affect the Lexile measure of a text?
- What type of subscriptions are available for the Lexile Analyzer?
- How do I know which subscription of the Lexile Analyzer I have access to?
- Can I measure a portion of the text and get an estimate for the reading demand of the entire text?
Certain categories of text should not be measured as a Lexile measure. Because The Lexile® Framework for Reading was built upon the measurement of professionally edited, complete, conventional prose text, the Lexile Analyzer will return an inaccurate Lexile measure for other kinds of text. Follow these guidelines as you choose texts to measure:
Because The Lexile® Framework for Reading was built upon the measurement of professionally edited, complete, conventional prose text, the Lexile Analyzer will return an inaccurate Lexile measure for other kinds of text. Follow these guidelines as you choose texts to measure:
- *Note
- There are a few exceptions to this list. For example, narrative poetry that is conventionally punctuated may be measured with the Lexile Analyzer. Text written in rhyme does not necessarily qualify as poetry and may still be measured.
- Texts that are appropriate for use with the Lexile Analyzer will still require text editing, as detailed in “Step 2: Prepare Your Text for the Lexile Analyzer" section.
Please observe the following text-preparation guidelines before you submit your sample file to the Lexile Analyzer.
Here are some guidelines for removing non-prose text:
Additional considerations should be made when editing a text for measurement. Historical notes, introductions, “About the author" pieces, and previews of the next book in a series should typically be removed. Such text is often written separately from the main text and thus contains unique textual characteristics that can influence the Lexile measure. However, such decisions should be carefully considered while preparing your text for analysis. Some frontmatter and backmatter may be a legitimate part of the larger text and should be included. As a general guideline, if text appears to be written by the same author for the same audience, then it should be included in the Lexile analysis.
In the layout of children’s picture books, single sentences are sometimes distributed across multiple pages of a book. In the activity of reading, these page breaks function as sentence endings, so a pipe character (|) should be inserted at each page break in your file. The Lexile Analyzer interprets pipes as sentence-ending punctuation. In the example below from Ludwig Bemelmans’ Madeline (Puffin Books), a pipe would be placed in the plain text file after the words “crank" to emulate the effect that page breaks have on reading, and the comma would be removed.
The Lexile Analyzer interprets pipes as sentence-ending punctuation. In the example below from Ludwig Bemelmans’ Madeline (Puffin Books), a pipe would be placed in the plain text file after the words “crank" to emulate the effect that page breaks have on reading, and the comma would be removed.
When using resources downloaded from websites, be sure to remove the non-prose and web page-specific elements, as indicated in the example below from a CNN.com article:
Only the main body of the article (G) and the complete-sentence figure caption (D) should be measured. The article title (A), date line (B), and image (C), as well as website-specific elements such as social sharing links (E) and margin advertisement text (F), should not be measured.
Also be careful to eliminate all HTML code and URLs from your sample file when measuring web resources.
Educators may find it helpful to evaluate the reading demand of the assessments they develop for/administer to their students. Getting an estimated Lexile text measure for the overall assessment can provide insight into whether reading challenges are likely to affect student performance on the assessment. If the reading demands of the assessment are substantially higher than the Lexile measure of the student, a poor performance on the assessment may be due to reading comprehension issues rather than a sign of weak content knowledge.
Getting an estimated Lexile text measure for the overall assessment can provide insight into whether reading challenges are likely to affect student performance on the assessment. If the reading demands of the assessment are substantially higher than the Lexile measure of the student, a poor performance on the assessment may be due to reading comprehension issues rather than a sign of weak content knowledge.
When measuring reading comprehension tests, all complete sentences in all reading passages should be measured all together as one document. You should not measure sample items, directions, or the test items themselves. Depending on the format of the test item, you may also measure the complete sentences in the items in order to compare their difficulties to that of the reading passage, but do not measure the item text together with the passage text.
All complete sentences in the passages and the items should be measured (except directions within the items, e. g., "Make no change"). Passages that have embedded blanks should be measured with the correct answer in place of the blank. The writing prompt and any associated directions should be measured. You should not measure sample items and all other directions.
g., "Make no change"). Passages that have embedded blanks should be measured with the correct answer in place of the blank. The writing prompt and any associated directions should be measured. You should not measure sample items and all other directions.
All complete sentences in the items should be measured. You should not measure images, diagrams, tables, sample items, and directions. Some examples of content you should not measure include maps or captions in social studies tests and equations or formulae in mathematics tests.
To learn about how to have an assessment report out student reading ability as a Lexile reader measure, visit Lexile Measures for your Reading Assessment or Program .
If you typed your text in the text editing box or if the words and sentences in your file are recognizable, proceed to step 2.
If the text you are trying to measure is in an image file or part of printed material, you can scan the pages, save them as a PDF file, and load them into an optical character recognition (OCR) program. There are several different OCR programs you can use to convert an image to text, including ones offered by Acrobat and ABBYY FineReader.
There are several different OCR programs you can use to convert an image to text, including ones offered by Acrobat and ABBYY FineReader.
Occasionally OCR results can be inconsistent, particularly involving punctuation marks such as periods not being recognized at all (see below). These inconsistencies will impact the accuracy of the Lexile measure. Unfortunately, the repair of a poorly OCRed file can take as long as typing the text.
If a text is converted from hard copy to electronic format using an OCR application, some problems may occur in the conversion process. These tend to relate to the specific software used, and special care should be taken to ensure the accuracy of the electronic facsimile.
- Some examples of common OCR errors are as follows:
- A letter “m" might convert as “rn."
- A comma followed by a quotation mark (,") might be interpreted as a slash w/ an apostrophe (/’).
- Verify that all the intended punctuation is in place—no periods missing, semicolons omitted, etc.
- If a polysyllabic word is split between two lines with a hyphen, the hyphen should be removed and the word made whole. Given the near limitless possibilities of language usage and layout, these examples should not be considered exhaustive. Rather, they should be seen as representative of the kinds of things that should be considered when preparing a text for measurement.
The Lexile Analyzer is designed to measure professionally-edited, complete, conventional prose text. It should not be used on non-prose, unpunctuated, or unconventional text. The Lexile Analyzer determines sentence length through recognition of sentence endings, so sentences must be conventionally punctuated to be recognized (refer to the FAQ How does the Lexile Analyzer work? for sentence ender information). Likewise, the Lexile Analyzer determines word frequency by recognizing correctly spelled, well-formed words. Otherwise, the Lexile Analyzer will not return a useful estimated Lexile measure.
Likewise, the Lexile Analyzer determines word frequency by recognizing correctly spelled, well-formed words. Otherwise, the Lexile Analyzer will not return a useful estimated Lexile measure.
- In preparing a file for measurement, your two basic objectives are to:
- Preserve the prose sentences and the words within them in your text.
- Remove non-prose content from your text before you analyze it.
You should keep in mind that the usefulness of an estimated Lexile measure depends on the proper preparation of a text for analysis. Seemingly minor errors can result in significant variation in Lexile measures.
The Lexile Analyzer requires a UTF-8 plain text document (*.txt file) for proper processing and Lexile measurement. A plain text file is one which uses only the basic UTF-8 character set and contains no special formatting. If you submit files of an incorrect format to the Lexile Analyzer, an incorrect Lexile measure will be returned.
Note: The Lexile Analyzer cannot measure Microsoft Word, PDF, HTML or scanned image files such as JPGs.
If the source text to be measured is in an electronic document format, such as a word processing document or a rich text document, the file usually can be converted into the plain text format using the settings in the application’s Save As… menu.
- Converting from Microsoft Word on Windows
- With your document open, select Save As… from the File menu.
- In the Save as type drop-down box, select Plain Text (*.txt).
- Click the Save button and a File Conversion window opens:
- Click the Other encoding radio button and select Unicode (UTF-8) from the list of formats to the right.
- Also check Allow character substitution.
- Click the OK button. You have saved your document in the plain text format for the Lexile Analyzer.
- Converting from Microsoft Word on Macintosh
- With your document open, select Save As… from the File menu.
- In the Save as type drop-down box, select Plain Text (*.txt).
- If this warning box appears, click Yes to save the file and disregard the remainder of this procedure:
- Otherwise, a File Conversion window opens:
- Click the Other encoding radio button and select Unicode (UTF-8) from the list of formats to the right.
- Also check Allow character substitution.

- Click the OK button. You have saved your document in the plain text format for the Lexile Analyzer.
It is advisable to open your plain text document to check it for conversion errors. Pay attention to special characters such as quotation marks, apostrophes, ellipses, or accented characters. Also, ensure that em-dashes and en-dashes have appropriate spacing on either side. They will be converted to hyphens, which can make the Lexile Analyzer interpret the two words on either side of an em-dash as a single hyphenated word unless there are spaces on either side of the hyphen.
- You have three options to submit text for analysis:
- Use the Inline Text Editing Box and type in the text you’d like measured
- Upload the .txt file you’d like measured
- Copy and paste text from either a Word or text file
Select the “Analyze" button and your Lexile Analyzer results appear on the screen. The type of subscription to the Lexile Analyzer that you have will determine the data and features you have access to. All subscriptions provide access to the Lexile measure, Mean Sentence Length, Mean Log Word Frequency, and Word Count. For the descriptions of additional data and features displayed for the Professional Lexile Analyzer and Lexile Analyzer Editor Assistant, see the informational pop-up boxes on the results page.
The type of subscription to the Lexile Analyzer that you have will determine the data and features you have access to. All subscriptions provide access to the Lexile measure, Mean Sentence Length, Mean Log Word Frequency, and Word Count. For the descriptions of additional data and features displayed for the Professional Lexile Analyzer and Lexile Analyzer Editor Assistant, see the informational pop-up boxes on the results page.
If using the free, limited word version of the Lexile Analyzer, you should print the results screen and note your filename or the name of your text because these results are not saved in any retrievable way. If you do not print or record the results, you will have to re-analyze your text.
The Professional Analyzer maintains a log history and the Lexile Analyzer Editor Assistant provides a document management system with features like category tagging and editing history. To learn more about the type of subscriptions and what features they offer, see the FAQ What type of subscriptions are available for the Lexile Analyzer?
To learn more about the type of subscriptions and what features they offer, see the FAQ What type of subscriptions are available for the Lexile Analyzer?
- Lexile Analyzer Results Lexile Analyzer results are provided in four categories:
- Lexile measure – This value indicates the reading demand of the text in terms of the semantic difficulty and syntactic complexity. The Lexile scale generally ranges from 0L for beginning reader texts to 1600L for advanced texts. For the free version of the Lexile Analyzer, the reading demand is reported in a Lexile zone. All other subscriptions report a Lexile measure.
- Word Count – This value reflects the total number of words in the text that was analyzed.
- Mean Sentence Length – This value is the average length of a sentence in the text, based on the sentences that were analyzed.

- Mean Log Word Frequency – This value is the logarithm of the number of times a word appears in in the MetaMetrics corpus of over 1.4 billion words. The value should be understood to mean how often a word occurs per 5 million words. The mean log word frequency is the average of all such values for words which appear in the text being analyzed.
- When you using the Lexile Analyzer, please note that:
- “Lexile measure" should always have a capital “L."
- “Lexile measure" should always have a lower case “m."
- Refer to “The Lexile® Framework for Reading" (with the registered trademark symbol) the first time that it is mentioned, and then “the Lexile Framework" henceforth.
- Lexile measures are reported as a number followed by a capital “L" (for Lexile measure). There is no space between the number and the “L" and Lexile measures of 1000 or greater are reported without a comma (e.
 g., 1050L). All Lexile measures are rounded to the nearest 10L to avoid over-interpretation of the measures.
g., 1050L). All Lexile measures are rounded to the nearest 10L to avoid over-interpretation of the measures. - We refer to a Lexile “zone" or “level" as representing the bands on the Lexile® map (e.g., the “700L Zone" goes from 700L to 790L).
- We refer to a Lexile range as the suggested range of Lexile measures that a reader should read. The Lexile range for a reader is 50L above to 100L below his or her reported Lexile measure. This takes into account measurement error found in the tests administered to students and in the automated measurement of the books. If a student attempts material above his or her Lexile range, the level of challenge may be too great for the student to be able to independently construct very much meaning from the text. Likewise, material below the reader’s Lexile range will provide that student with little comprehension challenge.
 Material above or below a reader’s Lexile range can be used for specific instructional purposes.
Material above or below a reader’s Lexile range can be used for specific instructional purposes. - Beginning Reader Code: Beginning Reader (BR) is a code given to both texts and students that are below 0L. A Lexile measure of BR100L indicate that the Lexile measure is 100 units below 0L. Just like -10° is higher (warmer) than -30° on a thermometer, a BR100L text is more complex than a BR300L text.
- If you are an educator or researcher and want to learn more about Lexile measures and beginning readers, visit: Beginning Readers.
- If you are a company or organization that has partnered with us and would like help communicating the advantages of using Lexile measure in the early grades, check out our Beginning Reader Communications Toolkit.
- If you are a company or organization and have an agreement with us to use Lexile measures in your product or service, access our branding guidelines at www.
 metametricsinc.com/branding-guidelines
metametricsinc.com/branding-guidelines
- There are two ways to find Lexile measure of a book:
- You can search for a specific title using the Quick Book Search on Lexile.com. You can also build book lists based on Lexile measure and interests using the “Find a Book" tool on Lexile.com.
- If you are looking for Lexile measures for a larger collection of titles for your library the Lexile Titles Database™ is a good resource. The Lexile Titles Database contains certified Lexile measures for over 260,000 English fiction and nonfiction trade book titles from hundreds of publishers. To learn how to license the Lexile Titles Database to provide Lexile measures for titles in your product or service, visit Licensing the Lexile Titles Databse.
MetaMetrics (developers of the Lexile Framework) measures a book at a publisher’s request.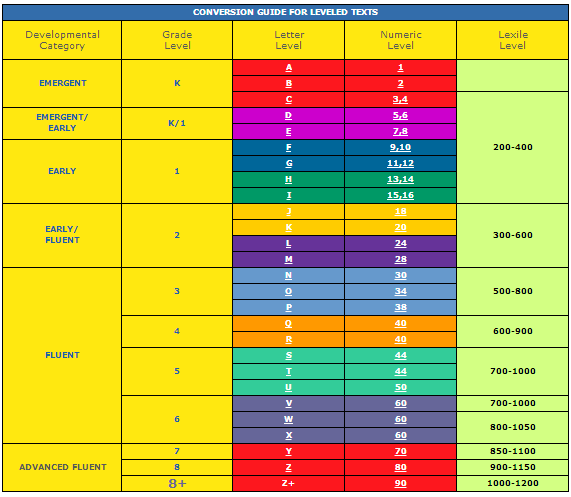 Books are always measured in their entirety. Publishers pay for this service, as well as the right to use the Lexile measure in their marketing materials.
Books are always measured in their entirety. Publishers pay for this service, as well as the right to use the Lexile measure in their marketing materials.
In order to ensure the most accurate Lexile measure, MetaMetrics’ text measurement process includes the following steps, with quality checks at each stage:
Several publishers and content developers use the Professional Lexile Analyzer and Lexile Analyzer Editor Assistant to help write text at certain reading levels and measure their texts developmental level before submitting for a certified Lexile measure. Upon submission to MetaMetrics, these files have been prepared using our text-preparation guidelines. These files are reviewed by our resource measurement coordinators to assure that the editing guidelines have been met. They are then submitted for Lexile code review and Lexile measures are returned to the publisher. It is only after review by MetaMetrics’ resource measurement team that these measures are deemed “certified" and then available for distribution via marketing materials, websites, and searchable in “Find a Book. "
"
The Lexile Analyzer works in steps: first by calculating a number of text complexity variables for a given text such as the length of sentences. Text complexity variables are then combined to calculate the Lexile measure of the text. The Lexile measure is an indication of the degree of challenge a particular text will pose for a particular reader. Lexile measures are units of measure just like degrees Fahrenheit.
Like the measurement of temperature, the measurement of text complexity requires different measurement instruments at different locations on the scale. For example, you would use a different instrument to measure a person’s body temperature than you would to measure the temperature inside your oven, but each instrument still provides measures on the same scale.
Similarly, for texts used in the early grades (generally texts intended for grades K thru 2), different text complexity variables are required to provide the most accurate measurement possible. For texts intended for readers above grade 2, a Lexile measure has a semantic and syntactic component represented by MLF (Mean Log Frequency) and LMSL (Log Mean Sentence Length) respectively. Research has shown that word frequency can be used as a proxy for vocabulary difficulty, and sentence length can be used as a proxy for sentence complexity. Word frequency is calculated using the MetaMetrics corpus of over 1.4 billion words intended for K–12 readers. For texts intended for readers in grades 2 and below, nine variables are used to measure four aspects of text important for early-reading: structure, syntax, semantics, and decoding. Structure refers to the systematic patterning and repetition often found in early-grades texts, but not typically found in texts for older readers. Decoding refers to the complexity of the orthographic patterns in the text and is related to the important task of learning to decode printed text into spoken or silently read words.
For texts intended for readers above grade 2, a Lexile measure has a semantic and syntactic component represented by MLF (Mean Log Frequency) and LMSL (Log Mean Sentence Length) respectively. Research has shown that word frequency can be used as a proxy for vocabulary difficulty, and sentence length can be used as a proxy for sentence complexity. Word frequency is calculated using the MetaMetrics corpus of over 1.4 billion words intended for K–12 readers. For texts intended for readers in grades 2 and below, nine variables are used to measure four aspects of text important for early-reading: structure, syntax, semantics, and decoding. Structure refers to the systematic patterning and repetition often found in early-grades texts, but not typically found in texts for older readers. Decoding refers to the complexity of the orthographic patterns in the text and is related to the important task of learning to decode printed text into spoken or silently read words.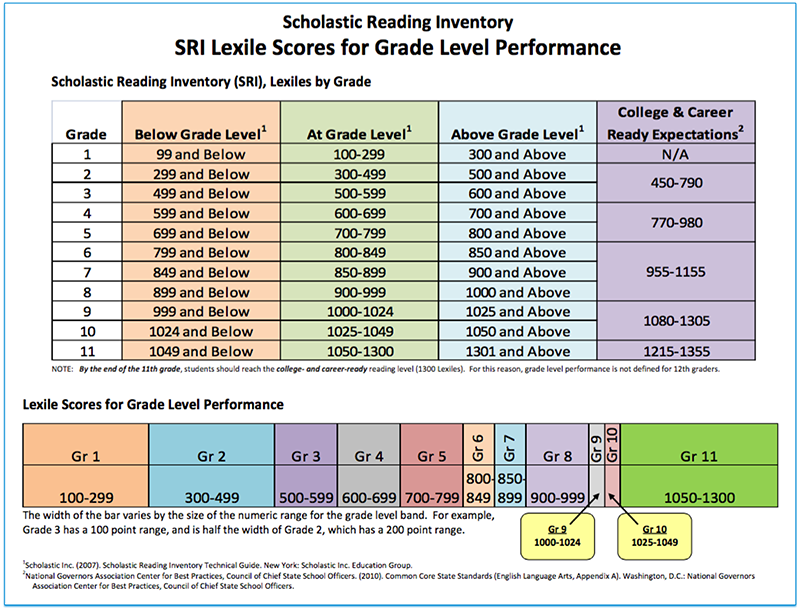
When a text is analyzed, all of its text complexity variables are calculated and a determination is made automatically as to whether the early-reading text complexity variables are required for analysis. For texts 650L and below, four additional early-reading indicators, relevant for early-grades texts, are reported: structure, syntax, semantics, and decoding.
Consequently, when using the Lexile Analyzer to measure text, you should keep in mind two keys to getting an accurate Lexile measure:
- All sentences must be automatically recognizable (capital letter at the beginning; end-punctuation at the end; no unconventional spacing or punctuation)
- End-punctuation recognized by the Lexile Analyzer includes the following: period (.), question mark (?), exclamation point (!), colon (:), semi-colon (;), and ellipses (.
 ..)
..)
- End-punctuation recognized by the Lexile Analyzer includes the following: period (.), question mark (?), exclamation point (!), colon (:), semi-colon (;), and ellipses (.
- All words must be automatically recognizable (correct spellings, spacing, and punctuation)
Proper file preparation, as detailed in the earlier section “Step 2: Prepare your text for the Lexile Analyzer" is the crucial step for ensuring Lexile measurement accuracy. File preparation errors or oversights, such as missing or incorrect punctuation or sections of unconventional prose or non-prose, may compromise your Lexile Analyzer results and return an estimated Lexile measure too far from the actual Lexile measure to be of use to you.
The measurement impact of editing errors and oversights is more severe the shorter the length of the input file. For this reason, special attention is encouraged when preparing a short passage, article, or children’s text for analysis.
We offer a free version of Lexile Analyzer that identifies what Lexile zone a text will fall into, as well as offers other basic data about the text (e. g., word count). This tool has a 1000 word limit and is intended for educators.
g., word count). This tool has a 1000 word limit and is intended for educators.
There are two Lexile Analyzer products offered on a paid subscription basis. These products are intended for commercial education companies and content developers. The products include:
- The Professional Lexile Analyzer®: With the Professional Lexile Analyzer, there are no word limit restrictions for measuring text. The Professional Lexile Analyzer offers early-reading indicator descriptors (for texts with Lexile measures that are 650L and below), as well as a Lexile history log of each measured text.
- The Lexile Analyzer® Editor Assistant™ is also available on a paid subscription basis. This product is ideal for content developers or companies trying to produce content at specific reading levels. In addition to the features of the Professional Analyzer, the Lexile Analyzer Editor Assistant also offers:
- A document management system which facilitates file sharing and category tagging between users
- Editing history
- Search capabilities
- Key information on text features that could present more or less of a challenge in early-reading content.
If you are interested in using the Lexile Analyzer for commercial purposes, visit Licensing the Professional Lexile Analyzer.
Once you are logged into your account, click on My Account on the top menu bar.
The next screen will show you what the products to which you have access.
You can also see your subscription type on the upper left hand corner once you are logged into your account. For example, if you have access to the Lexile Analyzer Editor Assistant, you will see this:
If you plan to measure the book yourself using the free Lexile Analyzer, we recommend measuring the entire text. The more text you can measure, the more accurate the Lexile measure will be. If this is not possible, you can use the following guidelines. For short books, such as children’s picture books, we recommend using the entire book. For longer books, such as chapter books or novels, we recommend using no less than 20 percent of the book. This 20-percent sample should be taken from various sections of the book, not just the beginning, middle or end. Unfortunately, if you choose to measure these books yourself there is no easy way around it. You must type at least 20 percent from various sections of the book to get a semi-accurate measure. Once again, we highly recommend the publisher submitting the book to MetaMetrics to receive a certified Lexile measure. This is the only real way you know the measure is accurate.
For longer books, such as chapter books or novels, we recommend using no less than 20 percent of the book. This 20-percent sample should be taken from various sections of the book, not just the beginning, middle or end. Unfortunately, if you choose to measure these books yourself there is no easy way around it. You must type at least 20 percent from various sections of the book to get a semi-accurate measure. Once again, we highly recommend the publisher submitting the book to MetaMetrics to receive a certified Lexile measure. This is the only real way you know the measure is accurate.
| Our Automatic Readability Checker takes a sample of your writing and calculates the number of sentences, words, syllables, and characters in your sample. (Note: We also have separate readability tools to calculate grade levels using the Fry Graph, Raygor Estimate Graph, Spache Formula, and New Dale-Chall Formula, located here: Free Readability Calculators and Text Tools). Directions: Paste in a sample of text and click "CHECK TEXT READABILITY." A sufficient sample size consists of 4-5 full sentences; approximately 200 - 600 words total. For larger texts, such as books, manuals, or dissertations, pull 1-2 sample sizes from each chapter. (Note: We limit the sample size to 3000 words. Sample sizes over 3K words are truncated.) Paste a sample of plain text in the box. Security check - Are you human?: Yes. (Click the box) Our free readability formula tool will analyze your text and output the results based on these readability formulas. Our tool will also help you determine the grade level for your text. 1. The Flesch Reading Ease formula will output a number from 0 to 100 - a higher score indicates easier reading. An average document has a Flesch Reading Ease score between 6 - 70. As a rule of thumb, scores of 90-100 can be understood by an average 5th grader. 8th and 9th grade students can understand documents with a score of 60-70; and college graduates can understand documents with a score of 0-30. 2. 3. The Fog Scale (Gunning FOG Formula) is similar to the Flesch scale in that it compares syllables and sentence lengths. A Fog score of 5 is readable, 10 is hard, 15 is difficult, and 20 is very difficult. Based on its name, 'Foggy' words are words that contain 3 or more syllables. 4. The SMOG Index outputs a U.S. school grade level; this indicates the average student in that grade level can read the text. For example, a score of 7.4 indicates that the text is understood by an average student in 7th grade. 5. The Coleman-Liau Index relies on characters instead of syllables per word and sentence length. 6. Automated Readability Index outputs a number which approximates the grade level needed to comprehend the text. For example, if the ARI outputs the number 3, it means students in 3rd grade (ages 8-9 yrs. old) should be able to comprehend the text. 7. Linsear Write Formula is a readability formula for English text, originally developed for the United States Air Force to help them calculate the readability of their technical manuals. Linsear Write Formula is specifically designed to calculate the United States grade level of a text sample based on sentence length and the number words used that have three or more syllables. StyleWriter software: use it to write better content! Download your free trial! | ||
 Our program takes the output of these numbers and plugs them into seven popular readability formulas. These readability formulas (see below) will let you know the reading level and grade level of your text and help you determine if your audience can read your writing.
Our program takes the output of these numbers and plugs them into seven popular readability formulas. These readability formulas (see below) will let you know the reading level and grade level of your text and help you determine if your audience can read your writing. Your sample can be between 150-3000 words. We do not store or reuse your text in any way.
Your sample can be between 150-3000 words. We do not store or reuse your text in any way. The Flesch-Kincaid Grade Level outputs a U.S. school grade level; this indicates the average student in that grade level can read the text. For example, a score of 7.4 indicates that the text is understood by an average student in 7th grade.
The Flesch-Kincaid Grade Level outputs a U.S. school grade level; this indicates the average student in that grade level can read the text. For example, a score of 7.4 indicates that the text is understood by an average student in 7th grade.  This formula will output a grade. For example, 10.6 means your text is appropriate for a 10-11th grade high school student.
This formula will output a grade. For example, 10.6 means your text is appropriate for a 10-11th grade high school student. Online English Vocabulary Test
This online test is designed to allow any user to evaluate their vocabulary for free and without registration. When testing, you will not only determine how many English words you know, but also the approximate level of English proficiency.
When testing, you will not only determine how many English words you know, but also the approximate level of English proficiency.
Start the test
How testing works
No test can accurately measure your vocabulary, our test is no exception, it only shows approximate data. But we tried to make its results as close as possible to real numbers and as informative as possible.
We have an English dictionary containing about 18,000 words, arranged in order of their frequency of use in the English language. For the test, we reduced this list of words to the 10,000 most popular words.
The most accurate way to test your vocabulary is to look at all the words and calculate how much you know. Unfortunately, this approach has a very significant disadvantage, since it will take quite a lot of time.
We decided for ourselves that the more often a word occurs in English speech, the easier it will be to remember and the easier it will be to remember.
| Easy | Medium | Hard |
| 1 the 2 of 3 and | 5001 fortress 5002 recipe 5003 bubble | 9998 diver 9999 sickly 10000 princely |
| 1st group | 50th group | 100th group |
After that we divided 10000 words into 100 groups of 100 words each. Next, we take one word from each group in random order and display them in the test. Accordingly, a total of one hundred words are used during testing.
In the next step, you will need to mark the words that you know for sure! Not those in which you doubt, but only those in which you are sure.
Be careful, we will automatically check your answers, and sometimes a confirmation window will pop up, where you will have to give a translation for the marked word. The more honest you are, the more accurate the test results will be, and you can actually learn your passive vocabulary.
The more honest you are, the more accurate the test results will be, and you can actually learn your passive vocabulary.
Test results
In order to give the results of this vocabulary test, we take the maximum score that could be scored in the test and, based on the results of the answers, we calculate your approximate vocabulary and other information on testing with other participants who have passed this test earlier .
Your approximate vocabulary:
7158 Words
You scored 3451 balls after passing the test
Your approximate level of language:
Language levels
calculated your approximate level of English, based on your vocabulary:
| № | Language level | words |
| A1 | Beginner, Elementary | 500 - 1000 |
| A2 | Pre-intermediate | 1000 - 3000 |
| B1 | Intermediate | 3000 - 5000 |
| B2 | Upper- Intermediate | 5000 - 8000 |
| C1 | Advanced | 8000 - 10000 |
| C2 | Proficient | 10000 and more0002 Other information about the testHere you can see your achievement after passing the test:
The correct and incorrect answers that you gave in the test earlier will also be shown. Here you can see the translation of words and listen to their pronunciation in English.
Start the test If you have questions or suggestions about the test, leave them in the comments below.
Rate our test4.7 rated: 194 people Vocabulary test 9 comments0003 Online English Tests
The task of our tests is to check the main aspects of the language: vocabulary, grammar (tenses, voice, etc. 
|
 Wrong answers or those words that you did not know before, you can add to your personal dictionary for further study. In order to do this, you need to click on the word and click on the add to dictionary button.
Wrong answers or those words that you did not know before, you can add to your personal dictionary for further study. In order to do this, you need to click on the word and click on the add to dictionary button.