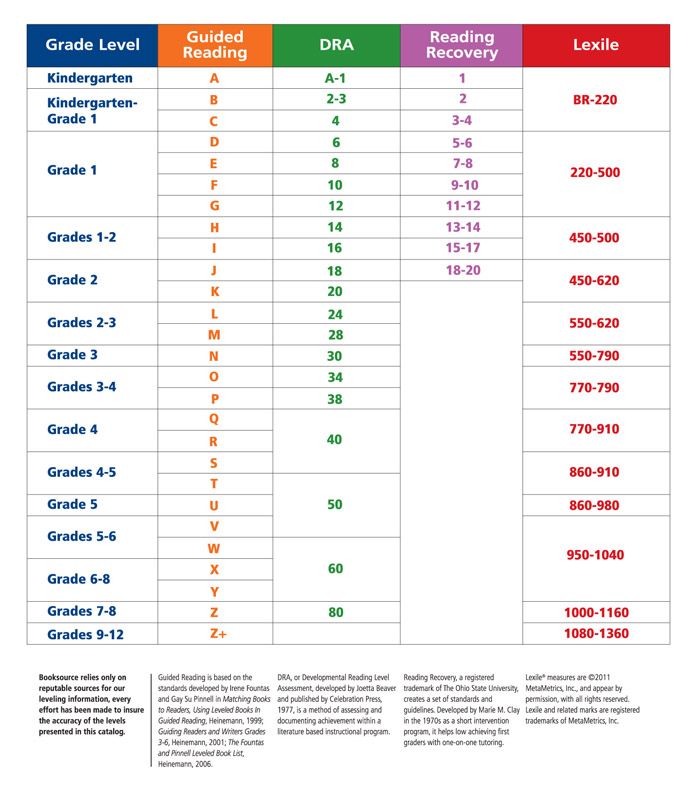
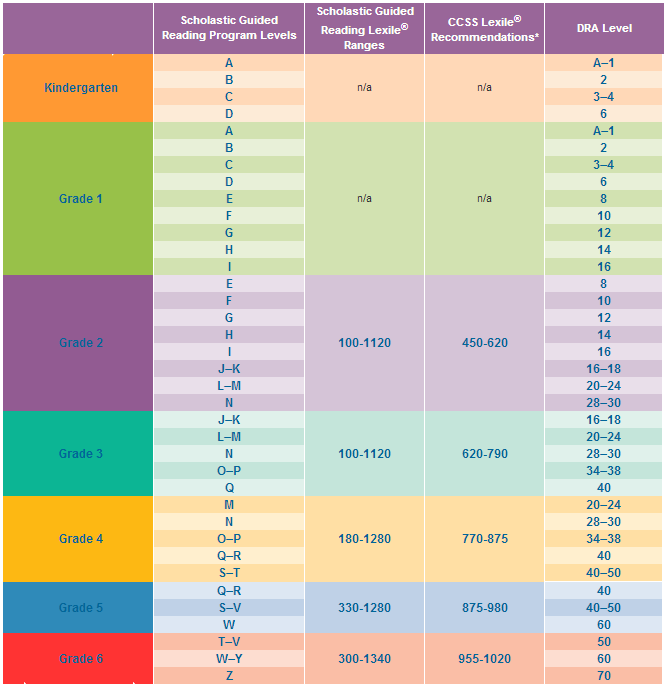
Second grade guided reading levels
2nd Grade / Fountas and Pinnell Reading Level Chart
-
Reading Levels
Grade Levels
A
K
B
K
1
C
K
1
D
1
E
1
F
1
G
1
H
1
2
I
1
2
J
2
K
2
L
2
3
M
2
3
N
3
O
3
4
P
3
4
Q
4
R
4
S
4
5
T
5
U
5
V
5
W
5
An overview of the guided reading levels
PSPKK12316 Comments
This post contains affiliate links. As an Amazon Associate I earn from qualifying purchases.
Sharing is caring!
This post will give you a simple overview of the guided reading levels from A-P.
This post contains affiliate links.
UPDATE COMING SOON: As I learn more about the science of reading, I am revising my approach. I absolutely believe in using small groups to teach our readers, but I no longer believe that this has to be guided reading in the traditional sense. Watch for an update to this post in the coming month!
Welcome to post number 2 in our series, How to Teach Kids to Read Using Guided Reading.
As a teacher of guided reading, it’s important that you have a consistent system for leveling your books. That’s because one essential of guided reading is leveled texts.
You need a system for analyzing texts and organizing them for teaching your small groups.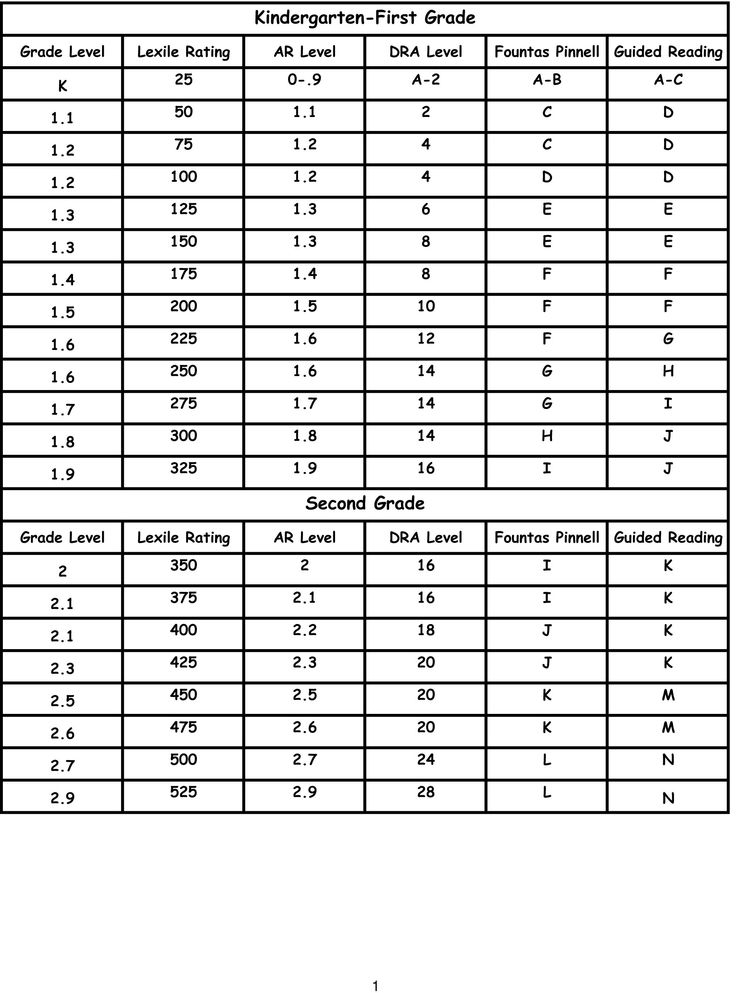
My favorite leveling system is the Fountas & Pinnell text level gradient – also called the guided reading levels. Let’s look at how these levels correspond to different grade levels in K-3.
Of course, kids will read at different levels. My oldest three kids all started school reading at level J or higher, while my fourth child started kindergarten at level B.
You’ll also find that you’ll have older readers who are reading at a lower level. It’s not unusual to have a second grader start the year at a level G, for example.
What’s the answer? A guided reading library of leveled books.
In the next post in this series, I’ll tell you where to find those books. For now?
Let’s take a look at examples of each level.
Level A Books
I Can Run Big Cat I Hug I See a Cat
- Have just one line of text per page
- Use predictable language patterns
- Have many simple sight words
- Use a large, clear font
- May be just 8 pages long
Level B Books
Up I See and See Pig Has a Plan Have You Seen My Cat?
- Are very much like level A
- Have up to 2 lines of text per page
Level C Books
Pie for Chuck Little Ducks Go The Fly Flew In Bad Dog
- Are similar to levels A & B
- May be longer, with 2-5 lines of text per page
- Include mostly 1-2 syllable words
- Have many easy decodable words
Level D Books
Car Goes Far Ed and Kip Fix This Mess Sick Day
- Are similar to level C
- Have slightly more complex stories
- May have sentences with 6+ words
Level E Books
Pete Won’t Eat A Night at the Zoo The End of the Rainbow Grace
- Have 2-8 lines of text per page
- Have more complex stories
- Have fewer repeating patterns
- May have sentences that carry over more than one line
- May have more pages than previous levels
Level F Books
Biscuit series Just Like Daddy “What is That?” Said the Cat A Hippo in Our Yard
- Are similar to level E
- Sentences may have 10+ words
- May have a slightly smaller font
- Stories start to have a clear beginning, middle, and end
Level G Books
Are You Ready to Play Outside? More Spaghetti, I Say! Just For You Sheep in a Jeep
- Are similar to level F
- Have 1, 2, and 3-syllable words
- Have more challenging vocabulary and ideas
Level H Books
Old Hat New Hat Just Me and My Dad Sammy the Seal The Watermelon Seed
- Include decodable words of 2 or more syllables
- May have a smaller font
- Have slightly more challenging ideas and vocabulary
- Are more literary and less repetitive
Level I Books
Don’t Let the Pigeon Drive the Bus! Hi Fly Guy Big Dog … Little Dog There’s a Nightmare in My Closet
- Are similar to level H
- Include complex and compound sentences
- Have more complex stories with varied themes
Level J Books
A Friend for Dragon Henry and Mudge series Poppleton series Mr.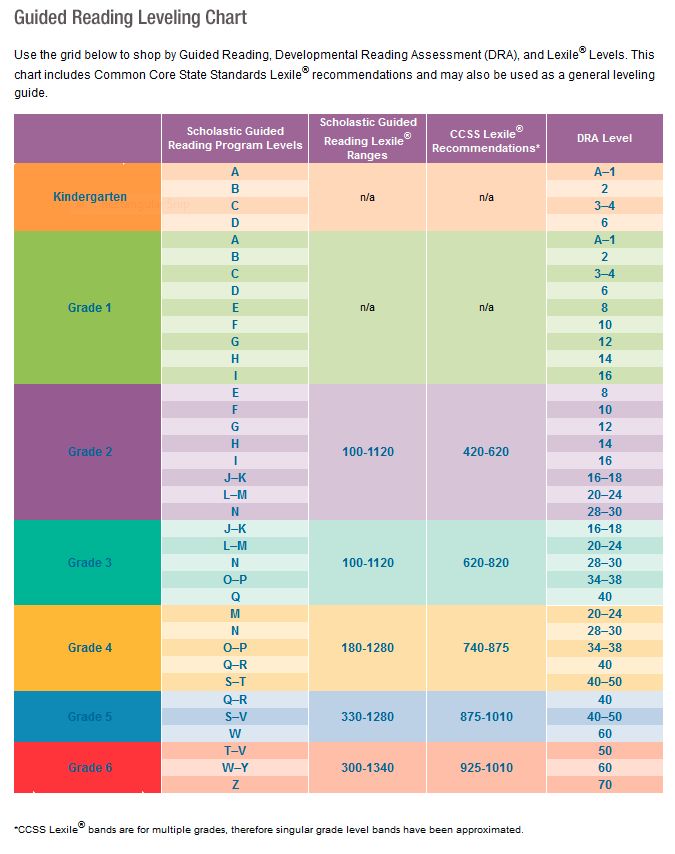 Putter & Tabby series
Putter & Tabby series
- Have 3-12 lines of text per page
- May have short chapters
- Include words with complex spelling patterns
- May have very few illustrations
Level K Books
Frog and Toad series Mercy Watson series Ling & Ting series Nate the Great series
- Are similar to level J, but are often longer
- Still have a reader-friendly layout
Level L Books
George and Martha books Oliver and Amanda pig books Pinky and Rex series Tacky the Penguin
- Have 5-24 lines of print per page
- Have a more challenging layout
- May have minimal or no illustrations
- May be 60-100 page long chapter books
- Are often simple chapter books with short chapters
- Include 1, 2, 3, and 4-syllable words
Level M Books
Judy Moody series Vacation under the Volcano Junie B. Jones series Marvin Redpost series
- Include longer, more complex stories
- Have elaborate plots and multiple characters
- May have no illustrations
Level N Books
The A to Z Mysteries series The Enormous Crocodile Gooney Bird series Nikki & Deja series
- Similar to level M, but slightly more challenging
Level O Books
Ramona series Mrs. Piggle Wiggle books Huey & Julian books Amber Brown series
Piggle Wiggle books Huey & Julian books Amber Brown series
- Similar to level N, but slightly more challenging
Level P Books
Bad Kitty books Encyclopedia Brown series Magic School Bus chapter book series Wayside School series
- Similar to Level O
- Slightly more complex themes
- Greater use of figurative language
And there you have it! An overview of the guided reading levels from A-P.
Check out our whole guided reading series:
Get your free overview of the guided reading levels!
CLICK TO DOWNLOAD
Free Reading Printables for Pre-K-3rd Grade
Join our email list and get this sample pack of time-saving resources from our membership site! You'll get phonemic awareness, phonics, and reading comprehension resources ... all free!
Sharing is caring!
Filed Under: Reading Tagged With: first grade, second grade, kindergarten, guided reading
You May Also Enjoy These Episodes:
Subtraction board game using flash cards
Easy prep winter crafts for kids in preschool
Trackbacks
Garbage collection basics | Microsoft Learn
- Article
- Reading takes 12 minutes
In the common language runtime (CLR), the garbage collector functions as an automatic memory manager. The garbage collector manages the allocation and deallocation of memory for an application. Therefore, developers working with managed code do not need to write code to perform memory management tasks. Automatic memory management can fix common problems such as forgetting to free an object and causing a memory leak, or trying to access freed memory for an already freed object.
The garbage collector manages the allocation and deallocation of memory for an application. Therefore, developers working with managed code do not need to write code to perform memory management tasks. Automatic memory management can fix common problems such as forgetting to free an object and causing a memory leak, or trying to access freed memory for an already freed object.
This article describes the basic concepts of garbage collection.
Benefits
Using the garbage collector provides the following benefits:
-
Developers do not have to deallocate memory manually.
-
Efficiently allocates memory for objects on the managed heap.
-
Destroy objects that are no longer in use, clean up their memory, and keep the memory available for future allocations. Managed objects automatically get clean content, so constructors don't have to initialize every data field.
-
Provides memory safety by ensuring that an object cannot use for itself the memory allocated to another object.
Memory Basics
The following is a list of important CLR memory concepts:
-
Each process has its own separate virtual address space. All processes on the same computer share the same physical memory and swap file, if any.
-
By default, on 32-bit computers, each process is allocated 2 GB of virtual address space in user mode.
-
Application developers only work with virtual address space and never directly manage physical memory. The garbage collector allocates and frees virtual memory for the developer on the managed heap.
Windows functions are used when writing native code to work with virtual address space. These functions allocate and deallocate virtual memory for the developer in their own heaps.
-
Virtual memory can be in three states.
Region Description Free The memory block is not referenced and is available for allocation. 
Reserved The memory block is available for your use and cannot be used for any other allocation request. However, you cannot store data in this block of memory until it is committed. Fixation Memory block assigned to physical storage. -
The virtual address space may be fragmented, which means there are free blocks, known as holes, in the address space. When a virtual memory allocation is requested, the virtual memory manager must find one free block large enough to satisfy the allocation request. Even if the system has 2 GB of free space, the 2 GB allocation operation will fail if that space is not located in the same address block.
-
Memory may run out if there is not enough virtual address space to reserve or physical space to allocate.
The paging file is used even if the physical memory shortage (physical memory requirement) is low. The first time physical memory is low, the operating system must make room in physical memory to store data, and it backs up some of the data that is stored in physical memory to the paging file.
 The data is not lined up until it is needed, so situations where physical memory pressure is low can lead to pagination.
The data is not lined up until it is needed, so situations where physical memory pressure is low can lead to pagination.
Memory allocation
When a new process is initialized, the runtime reserves a contiguous region of address space for it. This reserved address space is called the managed heap. This managed heap contains a pointer to the address from which memory will be allocated for the next object on the heap. This pointer is initially set to the base address of the managed heap. All reference types are allocated on the managed heap. When an application creates the first reference type, memory is allocated for it starting at the base address of the managed heap. When an application creates the next object, the garbage collector allocates memory for it in the address space immediately following the first object. As long as there is address space available, the garbage collector continues to allocate space for new objects in this manner.
Managed heap allocation is faster than unmanaged allocation.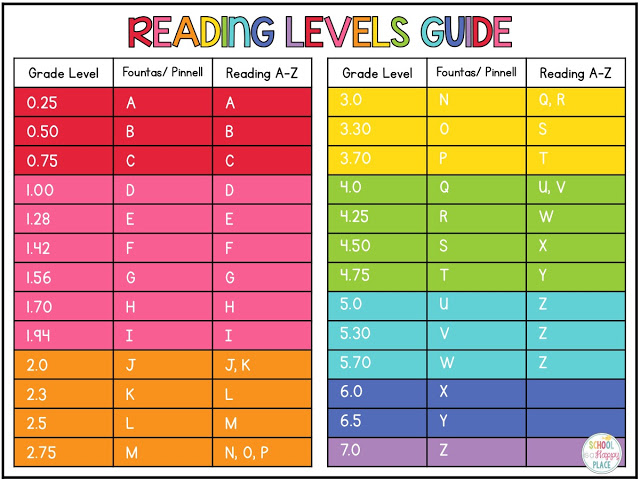 Because the runtime allocates memory for an object by adding a value to a pointer, this is almost as fast as allocating memory from the stack. Also, because new objects that are allocated sequentially are contiguous on the managed heap, the application can quickly access them.
Because the runtime allocates memory for an object by adding a value to a pointer, this is almost as fast as allocating memory from the stack. Also, because new objects that are allocated sequentially are contiguous on the managed heap, the application can quickly access them.
Deallocate memory
The garbage collector optimization engine determines the best time to run a collection based on memory allocations that have been made. When the garbage collector performs cleanup, it releases the memory allocated for objects that are no longer used by the application. It determines which objects are no longer used by parsing roots applications. Application roots contain static fields, local variables on the thread stack, processor registers, garbage collection descriptors, and completion queue. Each root either refers to an object residing on the managed heap or is NULL. The garbage collector can query the rest of the runtime for these roots. The garbage collector uses this list to create a graph containing all objects accessible from the roots.
Objects outside the graph are not accessible from application roots. The garbage collector treats unreachable objects as garbage and frees the memory allocated for them. During cleanup, the garbage collector inspects the managed heap, looking for blocks of address space that are occupied by unreachable objects. When an unreachable object is encountered, it uses the memory copy function to compact the reachable objects in memory, freeing up blocks of address space allocated for unreachable objects. After compacting the memory occupied by reachable objects, the garbage collector makes the necessary adjustments to the pointer so that the application roots point to the new locations of the objects. It also sets the managed heap pointer to a position after the last reachable object.
The memory is compacted only if a significant number of unreachable objects are found during cleanup. If all objects on the managed heap retain the collection, no memory compression is required.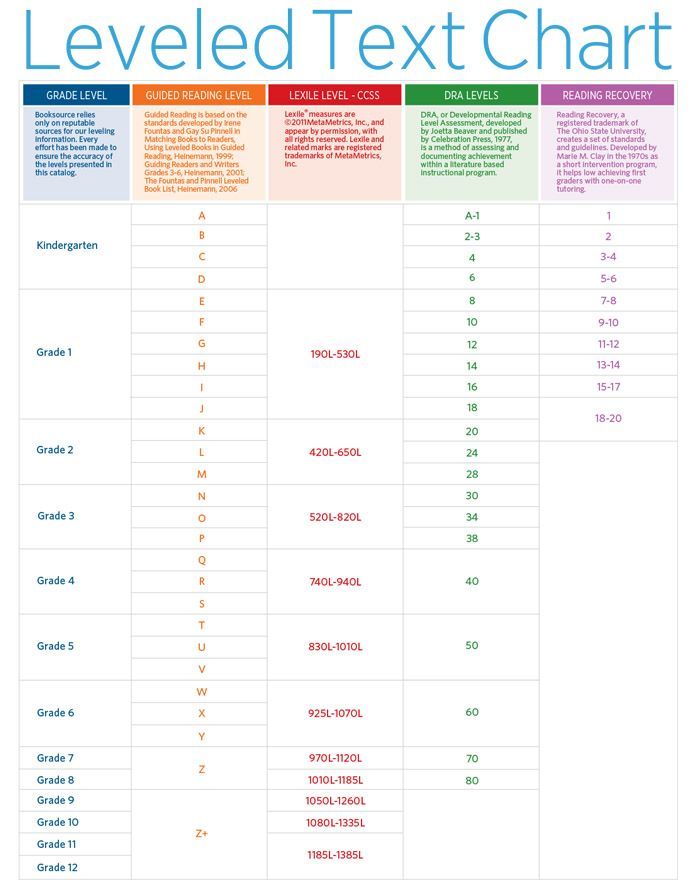
To improve performance, the runtime allocates memory for LOBs on a separate heap. The garbage collector automatically frees memory allocated for large objects. But to eliminate movements in LOB memory, this memory is usually not compressed.
Conditions for garbage collection
Garbage collection occurs when one of the following conditions is true:
-
Out of physical memory on the system. The memory size is determined by an out-of-memory notification from the operating system, or out-of-memory as specified by the host.
-
The amount of memory used by objects allocated on the managed heap exceeds the allowed threshold. This threshold is continuously adjusted during the execution of the process.
-
The GC.Collect method is called. In almost all cases, you do not need to call this method because the garbage collector runs continuously. This method is mainly used for unique situations and testing.
Managed heap
After the garbage collector is initialized, the common language runtime allocates a memory segment to store and manage objects. This memory is called the managed heap, as opposed to the operating system's own heap.
This memory is called the managed heap, as opposed to the operating system's own heap.
There is a managed heap for each managed process. All threads in a process allocate memory for objects on the same heap.
To reserve memory, the garbage collector calls the Windows VirtualAlloc function and reserves one memory segment at a time for managed applications. The garbage collector also reserves segments as needed and releases the segments back to the operating system (after cleaning them of any objects) by calling the Windows VirtualFree function.
Important!
The size of the segments allocated by the garbage collector is implementation dependent and can be changed at any time, including during periodic updates. The application should not make any assumptions about the size of a particular segment, rely on it, or attempt to adjust the amount of memory available for segment allocation.
The fewer objects allocated on the heap, the less work the garbage collector has to do.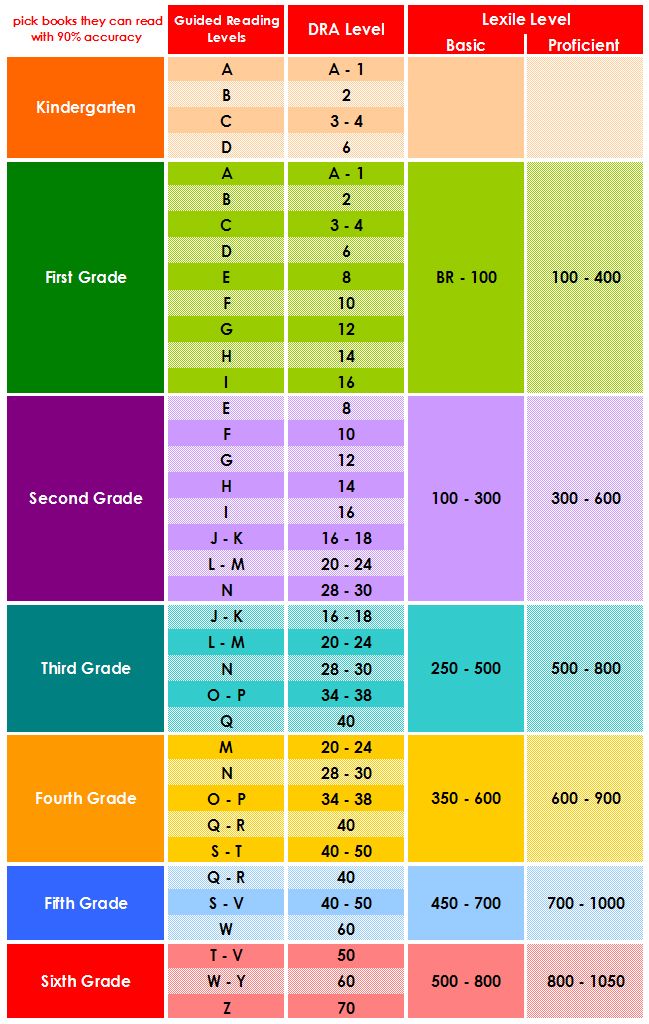 When allocating objects, do not use rounded values that exceed actual needs, for example, do not allocate 32 bytes when only 15 bytes are needed.
When allocating objects, do not use rounded values that exceed actual needs, for example, do not allocate 32 bytes when only 15 bytes are needed.
An activated garbage collection process releases memory occupied by unused objects. The deallocation process shrinks the living objects so they move together and the dead space is removed, thus making the heap smaller. This process ensures that objects allocated together remain on the managed heap to preserve their locality.
The amount of interference (frequency and duration) of garbage collections depends on the number of allocations and the memory remaining on the managed heap.
A heap can be thought of as a collection of two heaps: a large object heap and a small object heap. The large object heap contains objects larger than 85,000 bytes, usually represented by arrays. An instance object is rarely very large.
Tip
You can set the size threshold for objects placed on the large object heap.
Generations
The garbage collection algorithm considers the following:
- Compact memory for part of the managed heap faster than for the entire heap.
- New objects have a shorter lifetime and old objects have a longer lifetime.
- New objects are more closely related to each other and the application accesses them at approximately the same time.
Garbage collection basically comes down to the destruction of short-lived objects with a short lifetime. To optimize the performance of the garbage collector, the managed heap is divided into three generations: 0, 1, and 2. Therefore, objects with long and short lifetimes are handled separately. The garbage collector stores new objects in generation 0. Objects created early in the application and left over from garbage collections are promoted and persisted in generations 1 and 2. Since part of the managed heap can be compressed faster than the entire heap, this scheme allows the garbage collector to deallocate memory in a specific generation, rather than for the entire heap at each garbage collection.
-
Generation 0 : This generation is the youngest and contains transient objects.
 An example of a short-lived object is a temporary variable. Garbage collection is most often done in this generation.
An example of a short-lived object is a temporary variable. Garbage collection is most often done in this generation. Newly allocated objects form a new generation of objects and are implicitly generation 0 assemblies. However, if they are large objects, they go into the large object heap (LOH), which is sometimes referred to as generation 3 . Generation 3 is the physical generation that is logically collected as part of generation 2.
Most objects are garbage collected for generation 0 and do not survive to the next generation.
If an application tries to create a new object when generation 0 is full, the garbage collector executes the garbage collector to free the address space for the object. The garbage collector starts checking objects in generation 0 instead of all objects on the managed heap. Garbage collection on generation 0 alone often frees up enough memory for an application to continue creating new objects.
-
Generation 1 .
This generation contains short-lived objects and serves as a buffer between short-lived objects and long-lived objects.
When the garbage collector collects for generation 0, memory is compacted for reachable objects and they are promoted to generation 1. Since objects left after a collection tend to have a long lifespan, it makes sense to promote them to a higher generation. It is not necessary for the garbage collector to recheck generation 1 and 2 objects with every generation 0 garbage collection.0015
If the generation 0 collection does not free up enough memory for the application to create a new object, the garbage collector may execute the generation 1 collection and then generation 2. Objects in generation 1 left over from collections are promoted to generation 2.
-
Generation 2 . This generation contains long-lived objects. An example of a long-lived object is an object in a server application that contains static data that exists for the duration of a process.
Objects in generation 2 that retain the collection remain in generation 2 until they are no longer available in a future collection.
Objects in the large object heap (sometimes called generation 3 ) are also collected in generation 2.
Garbage collections occur in certain generations as a condition. Collection of a generation means collection of objects in that generation and all relevant lower generations. A generation 2 garbage collection is also called a full garbage collection because it frees objects across all generations (that is, all objects on the managed heap).
Survival and transitions
Objects that were not garbage collected are known as survivors and promoted to the next generation:
- Objects left after generation 0 garbage collection are moved to generation 1.
- Objects left over from generation 1 garbage collection are moved to generation 2.
- Objects left over from generation 2 garbage collection remain in generation 2.
When the garbage collector detects a high survival rate in a generation, it raises the allocation threshold for that generation. The next garbage collection frees up a significant portion of the occupied memory. The common language runtime constantly controls the balance of two priorities: not allowing the application's working set to become too large, delaying garbage collection, and not allowing garbage collection to occur too frequently.
Ephemeral generations and segments
Because objects in generations 0 and 1 are short-lived, these generations are called ephemeral generations .
Ephemeral generations are allocated in a memory segment called the ephemeral segment. Each new segment received by the garbage collector becomes a new ephemeral segment and contains objects that survived garbage collection for generation 0. The old ephemeral segment becomes a new generation 2 segment.
The size of the ephemeral segment depends on whether the system is 32-bit or 64-bit, and on the type of garbage collector that is running (workstation or server garbage collection). The following table shows the default ephemeral segment sizes:
| Workstation and server garbage collection | 32-bit version of | 64-bit version of |
|---|---|---|
| Workstation garbage collector | 16 MB | 256 MB |
| Server garbage collector | 64 MB | 4 GB |
| Server garbage collection with > 4 logical CPUs | 32 MB | 2 GB |
| Server garbage collection with 8 logical > CPUs | 16 MB | 1 GB |
This ephemeral segment can contain generation 2 objects. Generation 2 objects can use multiple segments, as long as your process needs and memory allows.
The amount of memory freed by ephemeral garbage collection is limited by the size of the ephemeral segment. The amount of free memory is proportional to the space occupied by dead objects.
Garbage collection process
Garbage collection consists of the following steps:
-
A marking step that searches for and lists all used objects.
-
Move step that updates links to compressible objects.
-
A compression step that frees up space occupied by unused objects and compresses surviving objects. The shrink stage moves the objects that survived the garbage collection towards the older end of the segment.
Because generation 2 assemblies can span multiple shards, generation 2 objects may be moved to an older shard. Both generation 1 and 2 survivors can be moved to another segment because they are promoted to generation 2.
Generally, the Large Object Heap (LOH) is not compressed because LOB copying imposes a performance penalty. However, in .NET Core and .NET Framework 4.5.1 and later, you can use the GCSettings.LargeObjectHeapCompactionMode property to compress a large heap of objects on demand. In addition, the LOB heap is automatically compressed when a hard limit is set with one of the following options:
- Container memory limit.
- GCHeapHardLimit or GCHeapHardLimitPercent runtime configuration options.
The garbage collector uses the following information to determine whether objects are in use.
-
Stack Roots : Stack variables provided by JIT compiler and stack stepping. JIT optimization allows you to reduce or increase the areas of code where stack variables are reported to the garbage collector.
-
Garbage collection handle: handles these objects that point to managed objects and that can be allocated by user code or the common language runtime.
-
Static data : Static objects in application domains that can refer to other objects. Each application domain maintains its own static objects.
All managed threads, except for the thread that started the garbage collection, are suspended before the garbage collection starts.
The following figure shows a thread that triggers garbage collection and causes other threads to be suspended:
Unmanaged resources
For most objects that an application creates, you can use garbage collection to automatically perform the necessary memory management tasks. However, explicit cleanup is required for unmanaged resources. The main type of unmanaged resources are objects that package operating system resources, such as a file handle, a window handle, or a network connection. Although the garbage collector can track the lifetime of a managed object that encapsulates an unmanaged resource, it does not have specific knowledge of how to clean up the resource.
When defining an object that encapsulates an unmanaged resource, we recommend that you provide the necessary code to clean up the unmanaged resource in the public Dispose method. By providing a Dispose method, you allow users of the object to explicitly release the resource when they are done with the object. When using an object that encapsulates an unmanaged resource, call Dispose as needed.
In addition, you need to provide a way to release unmanaged resources in case the consumer of the type does not call Dispose . You can use a protected handler to wrap an unmanaged resource, or you can override the Object. Finalize() method.
See cleanup of unmanaged resources.
See also
- Workstation garbage collection and server garbage collection
- Background garbage collection
- Configuration options for garbage collection
- Garbage collection
Disk type selection for Azure IaaS VMs - Managed Disks - Azure Virtual Machines
- Article
- Reading takes 20 minutes
Applies to: ✔️ Linux VMs ✔️ Windows VMs ✔️ Universal Scale Sets
Five types of Azure Managed Disks are currently available, each designed for specific user scenarios:
- Rims (price category "Ultra")
- SSD (Premium Pricing) Version 2
- Premium SSD drives;
- Standard SSD drives;
- HDD drives in the Standard price category.
Disc Type Comparison
The following table compares the five types of discs to help you decide which one to use.
| Disc (price category "Ultra") | SSD (Premium Pricing) Version 2 | SSD Drive (Premium Pricing) | SSD Drive (Standard Pricing) | HDD (Standard price category) | |
|---|---|---|---|---|---|
| Disc type | SSD | SSD | SSD | SSD | HDD |
| Scenario | I/O-heavy workloads (such as SAP HANA), top-level databases (such as SQL or Oracle), and transaction-heavy workloads | Production and bandwidth-sensitive workloads that consistently require low latency, high throughput, and high IOPS | High performance work environment | Web servers, rarely used enterprise applications, and development and test scenarios | Backup, non-critical and infrequent access |
| Maximum disc size | 65,536 GiB | 65. 536 Gib 536 Gib | 32,767 GiB | 32,767 GiB | 32,767 GiB |
| Maximum capacity | 4000 MB/s | 1200 MB/s | 900 MB/s | 750 MB/s | 500 MB/s |
| Max. IOPS | 160,000 | 80 000 | 20,000 | 6000 | 2000 |
| Available for use as an OS disk? | No | No | Yes | Yes | Yes |
Ultra Disk
Azure Ultra Disk is the highest performing storage option for Azure VMs. You can change the performance settings for these disks without having to restart the virtual machines. Ultra drives are suitable for data-intensive workloads such as SAP HANA, top-tier databases, and transaction-heavy workloads.
They can only be used as data disks and can only be created as blank disks. Pricing SSDs should be used as operating system (OS) drives. premium category (SSD).
premium category (SSD).
Ultra disk sizes
Azure disks (Ultra) support up to 32 TiB per region per subscription by default, but disks (Ultra) support higher capacity on demand. To request a capacity increase, request a quota increase or contact Azure Support.
The following table compares drive sizes and performance limits to help you decide which one to use.
| Disk Size (GiB) | IOPS limit | Bandwidth limit (Mbps) |
|---|---|---|
| 4 | 1200 | 300 |
| 8 | 2400 | 600 |
| 16 | 4800 | 1200 |
| 32 | 9600 | 2400 |
| 64 | 19 200 | 4000 |
| 128 | 38 400 | 4000 |
| 256 | 76 800 | 4000 |
| 512 | 153 600 | 4000 |
| 1024 - 65,536 (dimensions in this range increase in 1 TiB increments) | 160,000 | 4000 |
Ultra drives exhibit sub-millisecond latency and guarantee I/O and throughput for 99. 99% of business hours (as measured in the table above).
Ultra Drive Performance
Ultra drives offer a flexible performance configuration model that allows you to independently tune I/O and throughput both before and after provisioning. There are several fixed sizes of these drives available, ranging from 4 GiB to 64 TiB.
Ultra IOPS
Ultra drives support a maximum of 300 IOPS/GiB, up to a maximum of 160,000 per disk. To ensure that the drive reaches the target number of operations, make sure that the value you select for the drive does not exceed the limits of the virtual machine.
The current maximum IOPS limit for a single virtual machine in public sizes is 80,000. Ultra disks with high IOPS can be used as shared disks to support multiple virtual machines.
Minimum guaranteed IOPS per disk is 1 IOPS/GiB. The overall base minimum is 100 IOPS. For example, if you provisioned a 4 GiB Ultra disk, the minimum I/O for that disk would be 100, not four.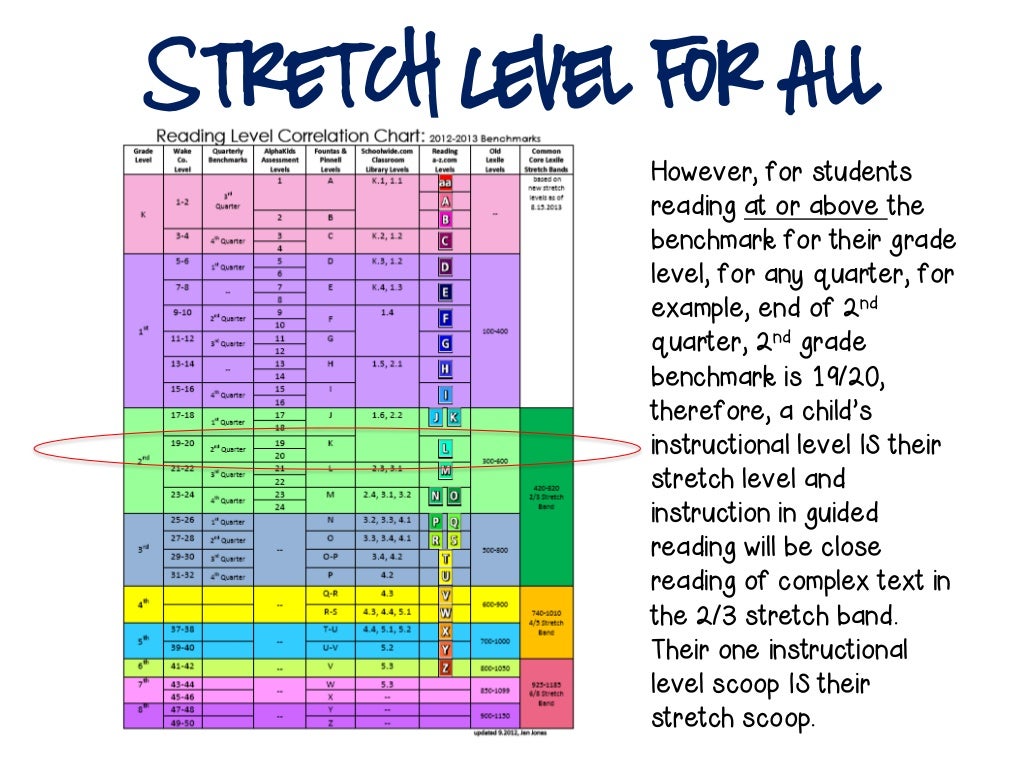
For more information about I/O, see Virtual machine and disk performance.
Ultra Bandwidth 96 bytes per second). The minimum guaranteed throughput per disk is 4 KiB/s for each provisioned I/O operation. The overall base minimum value is 1 Mbps.
Ultra disks can be configured for IOPS and throughput at run time without disconnecting the disk from the virtual machine. Once these metrics are configured, it can take up to one hour for the changes to take effect. You can change performance values up to four times within 24 hours.
Change performance metrics operation may fail due to insufficient bandwidth.
Ultra Drive Restrictions
Ultra Drives cannot be used as OS drives. Based on them, you can create only empty data disks. Ultra disks also cannot be used with some features and functionality, including disk export, disk type change, virtual machine images, availability sets, or Azure Disk Encryption. Azure Backup and Azure Site Recovery do not support drives in this category.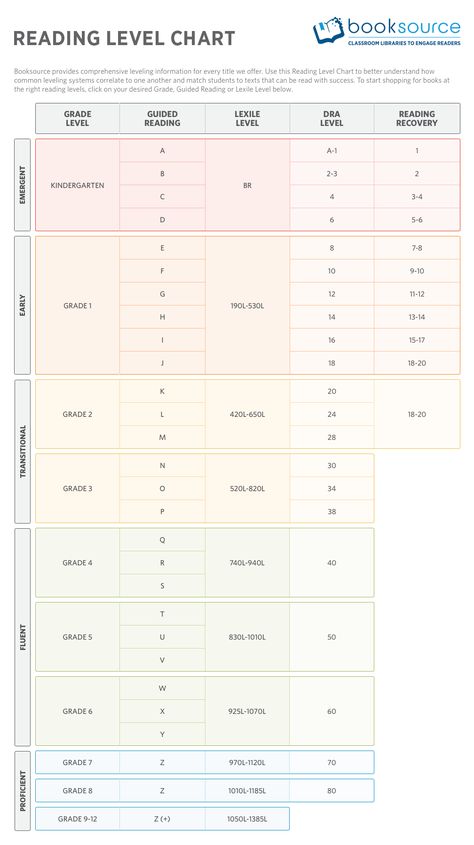 In addition, only non-cached reads and writes are supported for them. Snapshots for Ultra drives are currently available in public preview and only in central Sweden and western US 3 are not available in any other region.
In addition, only non-cached reads and writes are supported for them. Snapshots for Ultra drives are currently available in public preview and only in central Sweden and western US 3 are not available in any other region.
By default, Ultra drives support a 4K physical sector size. Sector size 512E is provided as a public offer and does not require registration. Most applications can work with a 4 KB sector size, but some require a 512 byte sector size. For example, Oracle Database requires release 12.2 or later to support 4K sector native disks. Older versions of Oracle DB require a sector size of 512 bytes.
The only infrastructure redundancy options currently available for Ultra drives are Availability Zones. Virtual machines that use any other redundancy settings cannot connect to the Ultra disk.
The following table lists the regions where Ultra discs are available and which availability options are supported.
Note
If the region listed below does not have an Availability Zone that supports Ultra disks, then all virtual machines in that region must be deployed without infrastructure redundancy to mount a disk of this category.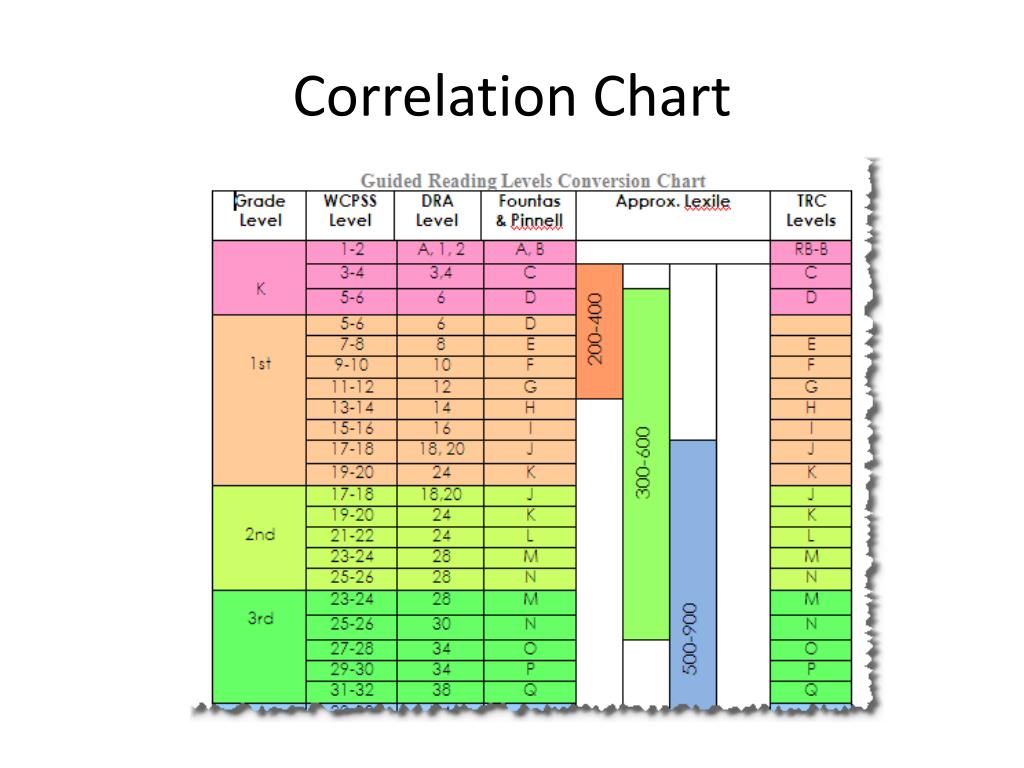
| Drive redundancy types | Regions |
|---|---|
| Individual virtual machines | Central Australia Southern Brazil Central India East Asia Central West Germany Republic of Korea Central Region Republic of Korea South Region North Central US, South Central US, US Western US Gov (Arizona) ), US Gov (Texas), US Gov (Virginia) |
| Single Availability Zone | North South Africa; Southeast Brazil Northern China 3 (provisional) Central Qatar Northern Switzerland |
| Dual Availability Zone | Central France |
| Tri-Zone | Eastern Australia Central Canada Northern Europe, Western Europe Eastern Japan Southeast Asia Central Sweden Southern UK Central US, Eastern US, Eastern US 2, Western US 2, Western US 3 |
Not every VM size is available in every supported region with the Ultra drive. The following table lists the virtual machine series that are compatible with Ultra disks.
The following table lists the virtual machine series that are compatible with Ultra disks.
| Virtual machine type | Dimensions | DESCRIPTION |
|---|---|---|
| General purpose | DSv3 Series, Ddsv4 Series, Dsv4 Series, Dasv4 Series, Dsv5 Series, Ddsv5 Series, Dasv5 Series | Balanced ratio of CPU and memory resources. Ideal for test and development, small to medium databases, and web servers with low to medium traffic. |
| Optimized for computing | Fsv2 Series | High CPU to memory ratio. Suitable for medium traffic web servers, network devices, batch processes and application servers. |
| Optimized for memory operations | ESv3 Series, Easv4 Series, Edsv4 Series, Esv4 Series, Esv5 Series, Edsv5 Series, Easv5 Series, Ebsv5 Series, Ebdsv5 Series, M Series, Mv2 Series, Msv2 Series or Mdsv2 | High memory to core resource ratio.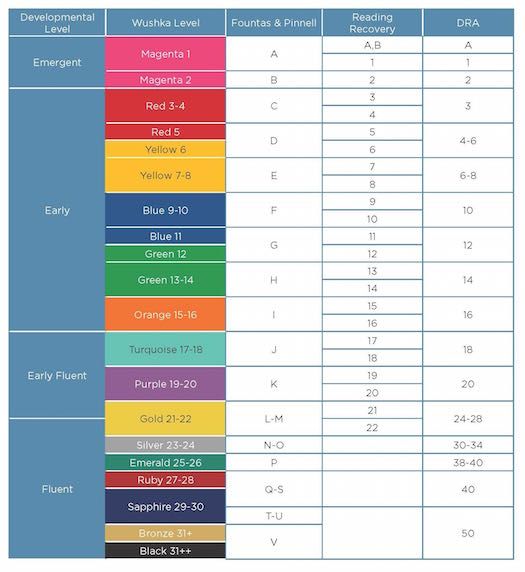 Great for relational database servers, medium to large caches, and in-memory analytics. Great for relational database servers, medium to large caches, and in-memory analytics. |
| Optimized for storage operations | Series LSv2, Lsv3, Lasv3 | High throughput and IOPS. Ideal for big data, SQL and NoSQL databases, storage systems and large transactional databases. |
| GPU optimized | NCv2, NCv3, NCasT4_v3, ND, NDv2, NVv3, NVv4 and NVadsA10 v5 series | Purpose-built virtual machines designed for intensive image rendering and video editing, as well as model training and inference using deep learning. Virtual machines are available with one or more GPUs. |
| Optimized for high performance | HB,HC and HBv2 Series | Virtual machines with the fastest and most powerful CPUs that can be configured with high bandwidth network interfaces (RDMA). |
If you'd like to get started with Ultra drives, check out How to use this solution from Azure.
Premium SSD v2
Premium Azure SSD v2 is designed for data-intensive enterprise workloads that require consistent sub-millisecond disk latency, high throughput, and high throughput at low cost. The performance (capacity, throughput, and IOPS) of SSDs (Premium Pricing) v2 can be configured independently at any time, making it easier to run more cost-effective scenarios while meeting performance requirements . For example, a transaction-heavy database workload might require high IOPS in a small size, or a game application might require high IOPS during peak hours. SSD (Premium Pricing) v2 is suitable for a wide range of workloads such as SQL Server, Oracle, MariaDB, SAP, Cassandra, Mongo DB, big data/analytics, gaming, virtual machines, or stateful containers.
Differences between SSD (Premium Pricing) and SSD (Premium Pricing) Version 2
Unlike SSD (Premium Pricing), SSD (Premium Pricing) Versions 2 has no dedicated dimensions. You can set your SSD (Premium Pricing) v2 to whatever supported size you want and fine-tune performance without downtime. SSD (Premium Pricing) Version 2 does not support host caching, but has significant benefits due to lower latency that addresses some of the same basic host caching address issues. The ability to adjust IOPS, throughput, and size at any time also eliminates the maintenance overhead associated with disk striping to suit your needs.
SSD (Premium Pricing) Version 2 Restrictions
- SSD (Premium Pricing) Version 2 cannot be used as an OS drive.
- SSD (Premium Pricing) v2 can only be attached to zoned virtual machines at this time.
- Snapshots are not currently supported and you cannot create an SSD (Premium tier) version 2 from another type of disk snapshot.
- Host encryption is not currently supported for Premium SSD v2. You can still attach Premium SSD v2 to virtual machines where you have enabled host encryption for disk types.
- Azure Disk Encryption (encrypting guest VMs with Bitlocker/DM-Crypt) is not supported for VMs with Premium SSD v2.
We recommend using encryption at rest with platform or client managed keys that are supported for SSDs Premium tier version 2.
- SSD (Premium Pricing) v2 cannot currently be attached to virtual machines in availability sets.
- Azure Backup and Azure Site Recovery are not supported for VMs with SSD drives (Premium Pricing) version 2.
Regional Availability
Currently only available in the following regions:
- US Eastern
- Western Europe
Performance SSD (Premium Pricing) Version 2
With SSD (Premium) version 2, you can customize capacity, throughput, and IOPS based on your workload needs, providing more flexibility and lower costs. Each of these values determines the cost of your disk.
SSD (Premium Pricing) v2 capacities
SSD (Premium Pricing) v2 capacities range from 1 GiB to 64 TiB in 1 GiB increments. Billed at a rate per GiB. See pricing page for details.
Ssd (Premium tier) version 2 offers up to 32 TiB per region per subscription by default, but supports higher capacity on demand.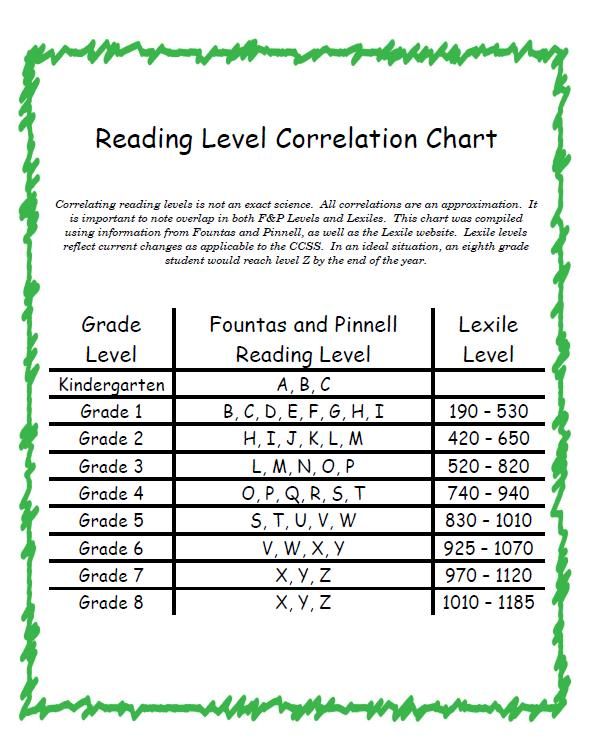 To request a capacity increase, request a quota increase or contact Azure Support.
To request a capacity increase, request a quota increase or contact Azure Support.
IOPS SSD (Premium Pricing) v2
All SSDs (Premium Pricing) v2 have a base IOPS of 3000, which is provided free of charge. After 6 GiB, the maximum IOPS a disk can have increases at 500 per GiB to 80,000 IOPS. So an 8 GB drive can have up to 4,000 IOPS, and a 10 GiB drive can have up to 5,000 IOPS. To set 80,000 IOPS on a disk, the disk must have a capacity of at least 160 GiB. Increasing the IOPS to over 3000 increases the cost of your disk.
Bandwidth SSD (Premium Pricing) v2
All SSD (Premium Pricing) v2 has a base throughput of 125 MB/s, which is free. Beyond 6 GiB, the maximum throughput that can be set increases by 0.25 MB/s per set of IOPS. If a disk has 3,000 IOPS available, the maximum throughput it can set is 750 MB/s. To increase the throughput of this drive above 750 MB/s, you need to increase its IOPS. For example, if you increase the number of IOPS to 4000, then the maximum throughput you can set is 1000. 1200 MB/s is the maximum throughput supported for drives with 5000 IOPS or more . Increasing bandwidth over 125 increases the cost of your drive.
SSD (Premium Pricing) v2 Sector Sizes
By default, SSD (Premium Pricing) v2 supports a physical sector size of 4K. Sector size 512E is also supported. Most applications can work with a 4 KB sector size, but some require a 512 byte sector size. For example, Oracle Database requires release 12.2 or later to support 4K sector native disks. Older versions of Oracle DB require a sector size of 512 bytes.
Summary
The following table compares drive capacities and performance limits to help you decide which one to use.
| Disc size | Maximum available IOPS | Maximum available bandwidth (MB/s) |
|---|---|---|
| 1 GiB-64 TiB | 3000 - 80000 (500 IOPS/GiB increase) | 125-1200 (0.25 MB/s increase per set of IOPS) |
For deployment of Premium SSD v2, see Deploy Premium SSD v2.
Premium SSD drives;
Azure SSDs (Premium Pricing) provide high-performance, low-latency disks for virtual machines designed for I/O-intensive workloads. Virtual machine disks can be migrated to SSD (Premium Pricing) to take advantage of their speed and performance. Premium SSDs are suitable for mission-critical workloads, but can only be used with compatible VM series.
For more information about the types and sizes of Azure virtual machines for Windows or Linux, see Virtual machine sizes in Azure. There you will also find information about what sizes of virtual machines are compatible with Premium storage. To find out, you need to read the description of each virtual machine of a certain size.
Premium SSD Dimensions
| Premium SSD Dimensions | P1 | P2 | P3 | P4 | P6 | P10 | P15 | P20 | P30 | P40 | P50 | P60 | P70 | P80 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Disk Size (GiB) | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16 384 | 32 767 |
| Prepared IOPS per disk | 120 | 120 | 120 | 120 | 240 | 500 | 1100 | 2300 | 5,000 | 7500 | 7500 | 16 000 | 18,000 | 20 000 |
| Provisioned throughput per disk | 25 MB/s | 25 MB/s | 25 MB/s | 25 MB/s | 50 MB/s | 100 MB/s | 125 MB/s | 150 MB/s | 200 MB/s | 250 MB/s | 250 MB/s | 500 MB/s | 750 MB/s | 900 MB/s |
| Maximum peak disk IOPS | 3500 | 3500 | 3500 | 3500 | 3500 | 3500 | 3500 | 3500 | 30,000 * | 30,000 * | 30,000 * | 30,000 * | 30,000 * | 30,000 * |
| Maximum peak throughput per disk | 170 MB/s | 170 MB/s | 170 MB/s | 170 MB/s | 170 MB/s | 170 MB/s | 170 MB/s | 170 MB/s | 1000 Mbps * | 1000 Mbps * | 1000 Mbps * | 1000 Mbps * | 1000 Mbps * | 1000 Mbps * |
| Maximum peak duration | 30 min | 30 min | 30 min | 30 min | 30 min | 30 min | 30 min | 30 min | Unlimited | Unlimited | Unlimited | Unlimited | Unlimited | Unlimited |
| Suitable for redundancy | No | No | No | No | No | No | No | No | Yes, up to one year | Yes, up to one year | Yes, up to one year | Yes, up to one year | Yes, up to one year | Yes, up to one year |
* Only applies to drives with on-demand acceleration enabled.
Capacity, IOPS, and throughput are only guaranteed when provisioning a premium storage disk. For example, when you create a P50 disk, Azure provisiones 4095 GB of storage capacity for it, along with 250 MB per second throughput and 7500 IOPS. An application can use full or partial capacity and performance resources. Premium SSDs deliver sub-10ms latency and guarantee 9 MHz I/O and throughput.9.9% of work time as described in the previous table.
Premium SSD Acceleration
Premium SSDs are designed with an acceleration capability that provides better fault tolerance against unpredictable changes in I/O patterns. Disk acceleration is especially useful during OS disk loading and for applications with bursts of traffic. For more information about how Azure disk acceleration works, see Disk-level acceleration.
Premium SSD Transactions
For SSDs (Premium tier), each I/O with a throughput less than or equal to 256 KiB counts as one I/O. I/Os with a throughput greater than 256 KiB are considered multiple 256 KiB I/Os.
Standard SSD drives;
Standard Azure SSDs are optimized for workloads that require consistent performance at lower IOPS. They are optimal for clients with heterogeneous workloads supported by local hard disk drive (HDD) solutions. Compared to standard HDDs, SSDs (Standard Pricing) provide better availability, consistency, reliability, and latency. SSD drives (Standard priced) are suitable for web servers, application servers with low IOPS, infrequently used enterprise applications, and experimental workloads. Like standard HDDs, SSDs (Standard pricing tier) are available on all Azure virtual machines.
Standard SSD Dimensions
| Standard SSD Dimensions | E1 | E2 | E3 | E4 | E6 | E10 | E15 | E20 | E30 | E40 | E50 | E60 | E70 | E80 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Disk Size (GiB) | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16 384 | 32 767 |
| IOPS per disk | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 | Before 2000 | Up to 4000 | Up to 6000 |
| Bandwidth per disk | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 400 MB/s | Up to 600 MB/s | Up to 750 MB/s |
| Maximum peak IOPS per disk | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 600 | 1000 | |||||
| Maximum peak throughput per disk | 150 MB/s | 150 MB/s | 150 MB/s | 150 MB/s | 150 MB/s | 150 MB/s | 150 MB/s | 150 MB/s | 250 MB/s | |||||
| Maximum peak duration | 30 min | 30 min | 30 min | 30 min | 30 min | 30 min | 30 min | 30 min | 30 min |
SSDs (Standard pricing tier) exhibit single-digit millisecond latencies and guarantee I/O and throughput for 99% of working hours (according to the values from the table above). Actual IOPS and throughput can sometimes change based on traffic patterns. Standard SSDs provide higher levels of availability and reliability than low latency HDDs.
Standard SSD Transactions
For SSD (Standard) drives, each I/O with a throughput less than or equal to 256 KiB counts as one I/O. I/Os with a throughput greater than 256 KiB are considered multiple 256 KiB I/Os. These transactions result in costs that appear on your invoices.
Standard SSD Acceleration
Standard SSD drives are designed to be accelerated to provide better fault tolerance for unpredictable changes in I/O patterns. The acceleration feature will be useful for OS boot disks and applications subject to bursts of traffic. For more information about how Azure disk acceleration works, see Disk-level acceleration.
HDD drives in the Standard price category.
Standard HDDs are reliable, cost-effective drives for virtual machines running latency-critical workloads. When using Standard storage, data is stored on HDDs. Their performance can vary over a wider range than SSD drives. Standard HDDs exhibit less than 10ms write latency and less than 20ms read latency for most I/O operations. However, their actual performance may vary based on I/O volume and workload pattern. HDDs (Standard Pricing) can be used for virtual machines in development and test scenarios, as well as for less critical workloads. HDDs (Standard Pricing) are available in all Azure regions and can be used with all Azure VMs.
Standard HDD sizes
| Standard drives | S4 | S6 | S10 | S15 | S20 | S30 | S40 | S50 | S60 | S70 | S80 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Disk Size (GiB) | 32 | 64 | 128 | 256 | 512 | 1024 | 2048 | 4096 | 8192 | 16 384 | 32 767 |
| IOPS per disk | 500 | 500 | 500 | 500 | 500 | 500 | 500 | 500 | Up to 1300 | Before 2000 | Before 2000 |
| Bandwidth per disk | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 60 MB/s | Up to 300 MB/s | Up to 500 MB/s | Up to 500 MB/s |
Standard HDD Transactions
For Standard HDDs, each I/O operation counts as one transaction, regardless of the amount of I/O. These transactions affect billing.
Billing
Managed disks are billed for the following.
- Disc type
- Managed Disk Size
- Snapshots
- Outgoing data transmission
- number of transactions;
Managed Disk Size . Managed disk billing depends on the size of the provisioned disk. Azure matches the provisioned size (rounded) to the closest suggested disk size. You can find out the proposed disk sizes in the previous tables. Each disk is mapped to one of the supported provisioned disk sizes and billed accordingly. For example, if you provisioned a 200 GiB SSD (Standard Pricing), it will be mapped to the suggested E15 (256 GiB) disk size. Any provisioned drive is billed pro rata based on hours at the monthly storage cost. For example, you prepare an E10 disk and remove it after 20 hours of operation. In this case, you will be charged for using the E10 offer for 20 hours, regardless of the amount of data written to the disc.
Snapshots. Snapshot charges are based on capacity used. For example, if you create a snapshot of a managed disk with a provisioned capacity of 64 GiB and an actual data usage of 10 GiB, you only pay for the data in use, which is 10 GiB. In this case, you are charged for the snapshot only for the 10 GiB data size used.
For more information about snapshots, see Overview of Azure Managed Disks.
Outgoing data transmission. Outbound data transfer (data in transit from Azure datacenters) is included in the charge for the bandwidth used.
Transactions. You are billed for the number of transactions that occur on a Standard managed disk. For SSDs (Standard pricing tier), each I/O with throughput less than or equal to 256 KiB counts as one I/O. I/Os with a throughput greater than 256 KiB are considered multiple 256 KiB I/Os. For HDDs (Standard Pricing), each I/O is counted as one transaction, regardless of the amount of I/O.
For more information about managed disk pricing and transaction costs, see this page.
Charge for Disk Reservation (Ultra Pricing) on Virtual Machines
For Azure VMs, you can specify whether they are compatible with disks (Ultra Pricing). Disk-compatible VM (Ultra Pricing) provides dedicated bandwidth between the compute VM instance and the block storage scale unit to optimize performance and reduce latency. When you add this capability to a virtual machine, a reservation fee applies. This only happens if you've enabled Ultra disks on the virtual machine but haven't mounted an Ultra disk. If you connect a disk (Ultra priced) to a compatible virtual machine, this fee is not charged. This charge is per vCPU provisioned on a virtual machine.
Note
For VM sizes with a limited number of cores, the reservation charge is based on the actual number of vCPUs, not the number of cores. For Standard_E32 8s_v3, the reservation fee will be based on 32 cores.