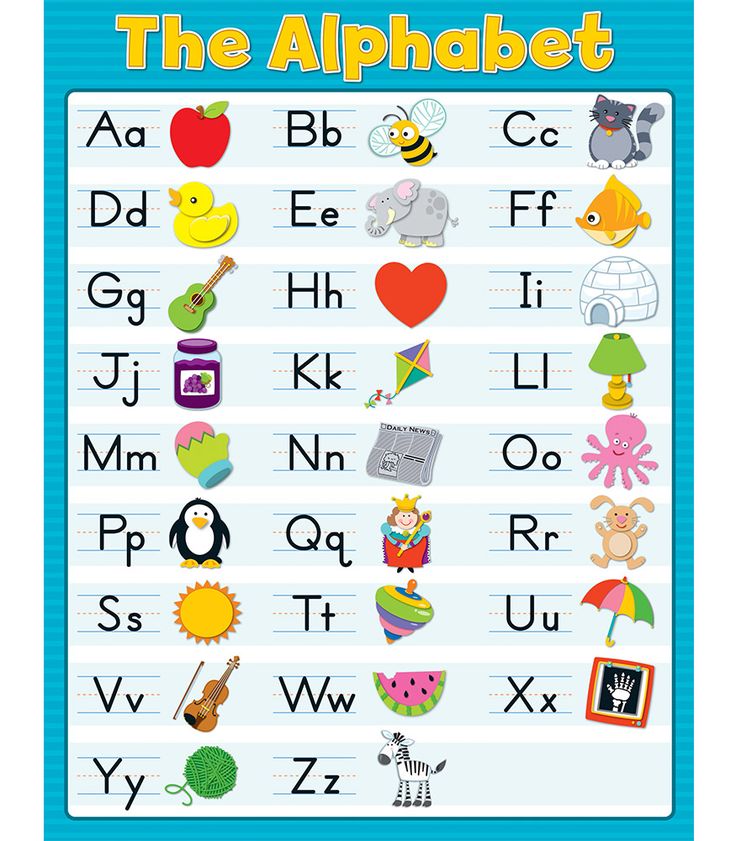
Teaching letter recognition games
Alphabet Letter Identification Activities - PreKinders
Here are 15 fun, active, hands-on alphabet letter identification activities for Pre-K, Preschool, and Kindergarten.
You can find many more Alphabet Activities here.
Letter Basketball
This is one of my prekinders favorite letter identification activities every year. To prepare this game, I cut copy paper or newsprint paper in half, and write letters on several pieces. I make enough papers for each child, plus one or two extra. I make a line with masking tape on the floor and place the trash can about 4 feet away. As each child has a turn, I tell them which letter to find. They pick up the letter, crumble the paper into a ball, and stand on the tape to toss it into the trash can. If they miss, they get as many chances as needed to get the “ball” in the basket and can move closer if needed. We always cheer when they make it in the basket! This game could also be played with alphabet bean bags if you have them.
Candy Letter Match
Write pairs of letters on sticker dots and place them on the bottom of several Hershey’s Kisses. For my Pre-K kids, I usually put out about 5-10 pairs of letters at a time. Children take turns lifting two Kisses at a time. If the letters match, they keep those Kisses. If they do not match, they have to put them back. At the end of the game, all of the Kisses are put in the middle of the table, and children can choose about 3 pieces to eat. We use this game to practice matching uppercase to uppercase letters, lowercase to lowercase, or uppercase to lowercase, depending on what we are working on.
Alpha-Band
Label each rhythm instrument with a letter. An easy way to make instruments is to put rice inside a plastic Easter egg, and hot glue it closed. We sing the traditional Alphabet Song, or another alphabet song, such as Dr. Jean’s “The Alphabet’s in My Mouth” or “Who Let the Letters Out”, or Jack Hartmann’s “Animal Alphabet Cheer”. Children shake their letter shakers only when they hear their letter called out in the song.
Letter Hunt
Children choose any 10 letters from the letter manipulatives (use foam letters, magnetic letters, letter tiles or other letter manipulatives). Go through a stack of shuffled letter cards, calling out each letter to the children. As the letters are called out, children look to see if they have that letter, and if they do, the letter is put back in the letter basket. We see who is first to clear all of their letters. It’s very similar to a bingo game. In Pre-K, we play until everyone has cleared all of their letters because our goal is learning letters, not competition with the little ones.
*To teach letter sounds: Call out a word and have children identify the first letter of the word.
ABC Sorting Tray
I found this divided tray in a kitchen store. I labeled each section by writing a letter on a sticker dot and placing the matching foam letters in each section of the tray. I placed the letters in a bowl and children sorted and matched the letters into the sections of the tray. When I want to change out the letters in the tray, I just remove the sticker dots and add new ones. I usually try to use letters that are similar, so that children are challenged and use visual discrimination skills to find the differences in the letters. For example, I might use Q, O, D, C, and G since those letters are similar in shape, or I, T, J, or W, V, U.
When I want to change out the letters in the tray, I just remove the sticker dots and add new ones. I usually try to use letters that are similar, so that children are challenged and use visual discrimination skills to find the differences in the letters. For example, I might use Q, O, D, C, and G since those letters are similar in shape, or I, T, J, or W, V, U.
ABC Sorting Box
Label a craft storage box with letter stickers. Children sort letter manipulatives into the sections of the box. These are magnetic letter tiles in the picture.
Letter Matching Uppercase to Uppercase
For this activity, each child chooses a colored letter box. Children work in pairs to match the letters that are the same. These letters came from a set of foam letters that are sadly no longer available from Lakeshore (bring them back, Lakeshore!) However, you could do the same activity by using handmade cards with the letters written in two different colors. You might also consider using paint chips (paint sample cards) in two different colors and making A-Z sets in the two different colors by writing on the cards with a black marker.
Letter Matching Uppercase to Lowercase
Children work in pairs to match the uppercase and lowercase foam or magnetic letters that are the same. You could also use purchased or handmade letter tiles.
Stamping Game
Write about ten letters on a piece of paper for each child. Put the same ten letters in a bowl or bag, and pass it around the table. Each child has a turn to pull a letter out of the bowl or bag, and announce the letter to the group. Children find the letter on their paper and stamp it out with a rubber stamp.
Other ways we play this game:
- I put every letter of the alphabet in the bowl or bag and children determine if the letter is on their paper or not.
- I place small objects in the bowl and children identify the beginning letter (e.g. B for ball).
Alphabet Bingo
Each child looks for the letter the teacher calls out on their bingo card. If they have it, they cover it. Play until a card is full.
Alphabet Soup
Children take turns scooping up a letter from a bowl with a spoon or soup ladle. The child identifies the letter, and walks around the room searching for the letter somewhere in the classroom.
The child identifies the letter, and walks around the room searching for the letter somewhere in the classroom.
*To teach letter sounds: Children search for an object in the room that begins with that letter.
Letter Clips
Children squeeze the clothespins and clip them to the sides of the box. I wrote letters on dot stickers and placed the dot stickers around the sides of the boxes. I wrote letters on the clothespins so the children would match the letters on the clothespins to the letters on the boxes. This is similar to activities where children clip clothespins to a paper plate or cardstock circle; however, in my experience, those were flimsy and awkward to use, which is why I like the box better. Any sturdy box could be used (shoe box, postal box). The boxes in this picture were stacking gift boxes that held chocolate covered nuts (a Christmas gift), and they worked out perfectly. (By the way, Sam’s Club has these chocolate covered nuts in the same stacking boxes every year, and they are awesome!)
Memory Game
Place about three letter manipulatives on a tray, cover them with a cloth, and take one away. When the letters are uncovered, children guess which letter is missing. Children find the letter that is missing among their own set of letter manipulatives. If the children are very interested in writing, they can write the letter that is missing on a dry erase lap board. To increase the difficulty of this game, try using 4 or 5 letters. Another options is to place three letters on the tray, cover them, and ask the children to recall all three letters that were on the tray.
When the letters are uncovered, children guess which letter is missing. Children find the letter that is missing among their own set of letter manipulatives. If the children are very interested in writing, they can write the letter that is missing on a dry erase lap board. To increase the difficulty of this game, try using 4 or 5 letters. Another options is to place three letters on the tray, cover them, and ask the children to recall all three letters that were on the tray.
Alphabet Path Games
I made these path games using stickers bought in a craft store (scrapbooking section), and I made individual mats with about 10 letters on them. Each child gets a mat, a game piece, and some plastic chips to cover the letters on their mat. They roll the dice and count out the spaces to move their game piece. If their game piece lands on a letter that is on the mat, they cover that letter with a chip. Play continues until they have covered every letter.
Other ways we use the path games:
- Children identify the letter they land on, then find that letter somewhere in the classroom.

- Children find an object in the classroom that begins with that letter’s sound.
You’ll also like these resources…
Letter Recognition Games
5 shares
- Share
- Tweet
Are you teaching letter recognition to your preschoolers and kindergarteners? Make it fun with these Letter Recognition Games!
These board and card games are an entertaining way for your kids to practice identifying letters by their names and shapes, matching capital and lowercase letters, and much more!
Not only will these alphabet games help your children learn and review the letters of the alphabet and other reading skills.
But, they will also work on developing their fine motor skills as they spin the spinner, roll the dice, pick up cards, and move their piece around the board.
What You'll Find On This Page
Why Are Play Games Important For Kids?
While playing these games, your preschoolers and kindergarteners will practice the letter recognition concepts that you are teaching them.
Working on these concepts will help your kids become confident with their letter knowledge and other pre-reading skills.
Through play, your young learners will also work on many different development skills that will help them as they learn to read and write.
Playing games is also a great way for your children to learn skills such as cooperation, taking turns, problem-solving, strategic thinking, and much more!
How Can These Alphabet Games Be Used?
This post may contain affiliate links. Please read our disclosure here.
If you are a preschool or kindergarten teacher, you can add these alphabet games to your morning tubs or literacy centers.
First, teach your students how to play the game during whole-class instruction or in small groups.
Depending on the games, your kids can then play them independently or with a partner.
If you are a homeschooler or a gameschooler, you can add these games to your lesson plans as a way to teach your children the letters of the alphabet.
You can pair many of them with books including The Very Hungry Caterpillar by Eric Carle or H Is for Hook: A Fishing Alphabet by Judy Young.
These Letter Recognition Games are a fun way for your preschoolers and kindergarteners to learn and review the letters of the alphabet and much more!
More Letter Recognition Games:
If you are looking for more letter recognition activities for your kids, try these engaging and entertaining games!
Fly Swatter Alphabet Game
10 Fun Games with ABC Pretzels from Books and Giggles
Apple Alphabet Game
Dump Truck Alphabet Game from Homeschool Preschool
ABC Bingo Game
You May Also Like This Letter Recognition Activity:
These Find The Letter: Alphabet Recognition Worksheets are a fun, hands-on way for children to practice recognizing lowercase and capital letters.
These spot and dot printables will also help your children work on visual discrimination and fine motor skills too. Click on the link or picture to learn more!
Click on the link or picture to learn more!
What is your favorite letter recognition game to play with your preschoolers and kindergarteners?
Didactic game "Alphabet in boxes" (Methodological development) | Methodological development for the development of speech (younger group):
Slide 1
Methodological development. Didactic game "Alphabet in boxes". (for preschool children) Kuznetsova T. V ., teacher GBDOU No. 97, St. Petersburg
Slide 2
Annotation "Alphabet in boxes" is an exciting educational game with which children can easily learn the alphabet. "The hand teaches the brain." So say researchers of the child psyche. Sensory, sensual experience serves as a source of knowledge of the world. When collecting boxes, children remember and understand more, thanks to tactile sensations, through interaction with real objects. You can use it from a young age to preparatory, complicating as you grow older.
Slide 3
Purpose: Development of children's cognitive activity. 2. Developing - to develop fine motor skills, visual perception - to develop attention, memory, thinking - to develop the ability to analyze - to form the ability to examine objects , the ability to bring the work begun to the end Tasks: 1. Educational - formation of the ability to hear and highlight the first sound in words - learn letters - remember the correct spelling of letters and learn to recognize them among other letters - exercise in the correct pronunciation of sounds
2. Developing - to develop fine motor skills, visual perception - to develop attention, memory, thinking - to develop the ability to analyze - to form the ability to examine objects , the ability to bring the work begun to the end Tasks: 1. Educational - formation of the ability to hear and highlight the first sound in words - learn letters - remember the correct spelling of letters and learn to recognize them among other letters - exercise in the correct pronunciation of sounds
Slide 4
Technologies: personality-oriented (encourage, push to think) polysensory (knowledge through the senses) communicative (cooperation, hear and listen) experimental research (soft, hard, compare facts and draw conclusions). Mnemonics (techniques for memorization, development of coherent speech).
Slide 5
Material: Box - a pasted matchbox in which there are objects or pictures with the letter on top. The items in the boxes are very different: toys, household items, natural materials, pictures, etc.
Slide 6
The vowels are red, but they can soften or harden a consonant. And then on the red box you will find blue or green.
Slide 7
There are hard and soft consonants, and then there are blue and green colors on the boxes.
Slide 8
And there are special consonants that are only hard and only soft.
Slide 9
Games can be very diverse.
Slide 10
Open and feel, study and reason why this or that object is in the box. We pronounce the words - select the first sound.
Slide 11
In order to make words, the box contains two identical letters. One on top, and the second on the bottom of the retractable part. Subsequently, we put in additional letters if necessary. Then you can make more complex words, even sentences.
Slide 12
We talk about the subject - we find the logic b - (wool) b- (stone)
Slide 13
Get all the items and find their place in the boxes.
Slide 14
Put in a box only those items that start with a specific letter. You can play both individually and collectively: Divide the children into subgroups and “who is faster” will sort the items into boxes. - "Guess what's hidden." The child hides the object in a box (for example: ball in "m") Children guess (bowl, chalk, poppy, etc.) In case of difficulty, leading questions are asked. So (the ball) “Tanya played it for them, dropped it into the river and cried ..” The one who guessed right becomes the leader.
You can play both individually and collectively: Divide the children into subgroups and “who is faster” will sort the items into boxes. - "Guess what's hidden." The child hides the object in a box (for example: ball in "m") Children guess (bowl, chalk, poppy, etc.) In case of difficulty, leading questions are asked. So (the ball) “Tanya played it for them, dropped it into the river and cried ..” The one who guessed right becomes the leader.
Slide 15
“Think of a word” Think of a word, laying them out with objects, not letters. For example: bowl + toys + fish = world. Or by replacing one or more letters with objects or pictures. M + TOYS + R = WORLD.
Slide 17
“Make whatever shape you want on any letter” If there are not enough objects or pictures, then let's take plasticine and mold it into what you need. A little imagination and nothing is impossible for us with magic boxes.
Slide 18
- Since the continuous educational activity in the kindergarten goes by topic, you can accordingly select objects - pictures (Vegetables, fruits, clothes, etc. ) For example, they found a tomato in a box with the letter P. Let's talk about it? What's this? Where does it grow? What form? etc.
) For example, they found a tomato in a box with the letter P. Let's talk about it? What's this? Where does it grow? What form? etc.
Slide 19
During the game, you can create problem situations, intentionally make mistakes. This encourages children to explore. For example, the game "Merry Train"
Slide 20
An unusual train has arrived at the railway station. Various letters of the alphabet are painted on its wagons. In order for him to go further, one item must be placed in each car. How to determine what and in which car to put? The letters above will tell you. Dunno made a mistake and the locomotive did not go. Help!
Slide 21
In the process, another author's fairy tale game appeared: "The Tale of Two Dwarfs from the ABCs" Once upon a time there were two gnomes, two brothers. They were so friendly that they built their own houses on the top of one hill. One of the gnomes was slender and strict, his name was Hardy, and the other was good-natured and fat, and his name was Makish. Singing steps led to each house on the hill. After all, vowel sounds can be sung! The steps that led to the house of the crumb were called: e, i, u, e, i, and the steps that led to the house of the Tough Man: a, o, u, s, e.
Singing steps led to each house on the hill. After all, vowel sounds can be sung! The steps that led to the house of the crumb were called: e, i, u, e, i, and the steps that led to the house of the Tough Man: a, o, u, s, e.
Slide 22
The brothers never quarreled among themselves, and the inhabitants of the ABC could easily visit the gnomes. But, getting into a strange house, they obeyed its rules. In the house of Tverdysh, all sounds sounded hard, but at the crumb - softly. Letters liked to visit the dwarfs and jump up and down the stairs, watching how differently they can sound. But there were also those who did not visit. "Y", "CH", "SCH" settled at the Miakish and were always pronounced softly. "Zh", "Sh", "Ts" lived in the house of Tverdysh and were pronounced only firmly.
Slide 23
Variants of the game: 1. To get to the dwarfs' houses, you need to climb the hill along the "singing steps" and sing vowel sounds. 2. Try to run each letter up the steps. Read.
Read.
Slide 24
Variants of the game can be varied. 3. Once the brothers went for a walk in the woods. Suddenly a strong wind picked up, it started raining like a bucket. The gnomes barely managed to hide in the fox's hole. When they returned, they saw that all the steps had been washed away with water. They can't get home. It is necessary to properly restore the stairs.
Slide 25
THANKS FOR YOUR ATTENTION! In the classroom, using these games, educational, educational and developmental tasks are solved.
Visual introduction to neural networks using the example of digit recognition
With the help of many animations, a visual introduction to the learning process of a neural network is given using the example of a digit recognition task and a perceptron model.
Articles on the topic of what artificial intelligence is have been written for a long time. But the mathematical side of the coin :)
We continue the 3Blue1Brown series of first-class illustrative courses (see our previous reviews on linear algebra and calculus) with a course on neural networks.
The first video is devoted to the structure of the components of the neural network, the second - to its training, the third - to the algorithm of this process. As a task for training, the classical task of recognizing numbers written by hand was taken.
A multilayer perceptron is considered in detail - a basic (but already quite complex) model for understanding any more modern versions of neural networks.
The purpose of the first video is to show what a neural network is. Using the example of the problem of digit recognition, the structure of the components of the neural network is visualized. The video has Russian subtitles.
Statement of the problem of digit recognition
Imagine you have the number 3, depicted in an extremely low resolution of 28x28 pixels. Your brain can easily recognize this number.
From a computational standpoint, it's amazing how easy the brain is to perform this operation, even though the exact arrangement of the pixels varies greatly from one image to the next. Something in our visual cortex decides that all threes, no matter how they are depicted, represent the same entity. Therefore, the task of recognizing numbers in this context is perceived as simple.
But if you were asked to write a program that takes as input an image of any number in the form of an array of 28x28 pixels and outputs the “entity” itself - a number from 0 to 9, then this task would cease to seem simple.
As the name suggests, the device of the neural network is somewhat close to the device of the neural network of the brain. For now, for simplicity, we will imagine that in the mathematical sense, in neural networks, neurons are understood as a certain container containing a number from zero to one.
Activation of neurons. Neural network layers
Since our grid consists of 28x28=784 pixels, let there be 784 neurons containing different numbers from 0 to 1: the closer the pixel is to white, the closer the corresponding number is to one. These numbers filling the grid will be called activations of neurons. You can imagine this as if a neuron lights up like a light bulb when it contains a number close to 1 and goes out when a number is close to 0.
These numbers filling the grid will be called activations of neurons. You can imagine this as if a neuron lights up like a light bulb when it contains a number close to 1 and goes out when a number is close to 0.
The described 784 neurons form the first layer of the neural network. The last layer contains 10 neurons, each corresponding to one of the ten digits. In these numbers, activation is also a number from zero to one, reflecting how confident the system is that the input image contains the corresponding digit.
There are also a couple of middle layers, called hidden layers, which we'll get to shortly. The choice of the number of hidden layers and the neurons they contain is arbitrary (we chose 2 layers of 16 neurons each), but usually they are chosen from certain ideas about the task being solved by the neural network.
The principle of the neural network is that the activation in one layer determines the activation in the next. Being excited, a certain group of neurons causes the excitation of another group. If we pass the trained neural network to the first layer the activation values according to the brightness of each pixel of the image, the chain of activations from one layer of the neural network to the next will lead to the preferential activation of one of the neurons of the last layer corresponding to the recognized digit - the choice of the neural network.
If we pass the trained neural network to the first layer the activation values according to the brightness of each pixel of the image, the chain of activations from one layer of the neural network to the next will lead to the preferential activation of one of the neurons of the last layer corresponding to the recognized digit - the choice of the neural network.
Purpose of hidden layers
Before delving into the mathematics of how one layer affects the next, how learning occurs, and how the neural network solves the problem of recognizing numbers, we will discuss why such a layered structure can act intelligently at all. What do intermediate layers do between input and output layers?
Figure Image Layer
In the process of digit recognition, we bring the various components together. For example, a nine consists of a circle on top and a line on the right. The figure eight also has a circle at the top, but instead of a line on the right, it has a paired circle at the bottom. The four can be represented as three lines connected in a certain way. And so on.
The four can be represented as three lines connected in a certain way. And so on.
In the idealized case, one would expect each neuron from the second layer to correspond to one of these components. And, for example, when you feed an image with a circle at the top to the neural network, there is a certain neuron whose activation will become closer to one. Thus, the transition from the second hidden layer to the output corresponds to the knowledge of which set of components corresponds to which digit.
Layer of images of structural units
The circle recognition task can also be divided into subtasks. For example, to recognize various small faces from which it is formed. Likewise, a long vertical line can be thought of as a pattern connecting several smaller pieces. Thus, it can be hoped that each neuron from the first hidden layer of the neural network performs the operation of recognizing these small edges.
Thus entered image leads to the activation of certain neurons of the first hidden layer, which determine the characteristic small pieces, these neurons in turn activate larger shapes, as a result, activating the neuron of the output layer associated with a certain number.
Whether or not the neural network will act this way is another matter that you will return to when discussing the network learning process. However, this can serve as a guide for us, a kind of goal of such a layered structure.
On the other hand, such a definition of edges and patterns is useful not only in the problem of digit recognition, but also in the problem of pattern detection in general.
And not only for recognition of numbers and images, but also for other intellectual tasks that can be divided into layers of abstraction. For example, for speech recognition, individual sounds, syllables, words, then phrases, more abstract thoughts, etc. are extracted from raw audio.
Determining the recognition area
To be specific, let's now imagine that the goal of a single neuron in the first hidden layer is to determine whether the picture contains a face in the area marked in the figure.
The first question is: what settings should the neural network have in order to be able to detect this pattern or any other pixel pattern.
Let's assign a numerical weight w i to each connection between our neuron and the neuron from the input layer. Then we take all the activations from the first layer and calculate their weighted sum according to these weights.
Since the number of weights is the same as the number of activations, they can also be mapped to a similar grid. We will denote positive weights with green pixels, and negative weights with red pixels. The brightness of the pixel will correspond to the absolute value of the weight.
Now, if we set all weights to zero, except for the pixels that match our template, then the weighted sum is the sum of the activation values of the pixels in the region of interest.
If you want to determine if there is an edge, you can add red weight faces around the green weight rectangle, corresponding to negative weights. Then the weighted sum for this area will be maximum when the average pixels of the image in this area are brighter, and the surrounding pixels are darker.
Activation scaling to the interval [0, 1]
By calculating such a weighted sum, you can get any number in a wide range of values. In order for it to fall within the required range of activations from 0 to 1, it is reasonable to use a function that would "compress" the entire range to the interval [0, 1].
The sigmoid logistic function is often used for this scaling. The greater the absolute value of the negative input number, the closer the sigmoid output value is to zero. The larger the value of the positive input number, the closer the value of the function is to one.
Thus, neuron activation is essentially a measure of how positive the corresponding weighted sum is. To prevent the neuron from firing at small positive numbers, you can add a negative number to the weighted sum - a bias, which determines how large the weighted sum should be in order to activate the neuron.
So far we've only talked about one neuron. Each neuron from the first hidden layer is connected to all 784 pixel neurons of the first layer. And each of these 784 compounds will have a weight associated with it. Also, each of the neurons in the first hidden layer has a shift associated with it, which is added to the weighted sum before this value is "compressed" by the sigmoid. Thus, for the first hidden layer, there are 784x16 weights and 16 shifts.
Each neuron from the first hidden layer is connected to all 784 pixel neurons of the first layer. And each of these 784 compounds will have a weight associated with it. Also, each of the neurons in the first hidden layer has a shift associated with it, which is added to the weighted sum before this value is "compressed" by the sigmoid. Thus, for the first hidden layer, there are 784x16 weights and 16 shifts.
Connections between other layers also contain the weights and offsets associated with them. Thus, for the given example, about 13 thousand weights and shifts that determine the behavior of the neural network act as adjustable parameters.
To train a neural network to recognize numbers means to force the computer to find the correct values for all these numbers in such a way that it solves the problem. Imagine adjusting all those weights and manually shifting. This is one of the most effective arguments to interpret the neural network as a black box - it is almost impossible to mentally track the joint behavior of all parameters.
Description of a neural network in terms of linear algebra
Let's discuss a compact way of mathematical representation of neural network connections. Combine all activations of the first layer into a column vector. We combine all the weights into a matrix, each row of which describes the connections between the neurons of one layer with a specific neuron of the next (in case of difficulty, see the linear algebra course we described). As a result of multiplying the matrix by the vector, we obtain a vector corresponding to the weighted sums of activations of the first layer. We add the matrix product with the shift vector and wrap the sigmoid function to scale the ranges of values. As a result, we get a column of corresponding activations.
Obviously, instead of columns and matrices, as is customary in linear algebra, one can use their short notation. This makes the corresponding code both simpler and faster, since the machine learning libraries are optimized for vector computing.
Neuronal activation clarification
It's time to refine the simplification we started with. Neurons correspond not just to numbers - activations, but to activation functions that take values from all neurons of the previous layer and calculate output values in the range from 0 to 1.
In fact, the entire neural network is one large learning-adjustable function with 13,000 parameters that takes 784 input values and gives the probability that the image corresponds to one of the ten digits intended for recognition. However, despite its complexity, this is just a function, and in a sense it is logical that it looks complicated, because if it were simpler, this function would not be able to solve the problem of recognizing digits.
As a supplement, let's discuss which activation functions are currently used to program neural networks.
Addition: a little about the activation functions. Comparison of the sigmoid and ReLU
Let us briefly touch on the topic of functions used to "compress" the interval of activation values. The sigmoid function is an example that emulates biological neurons and was used in early work on neural networks, but now the simpler ReLU function is more commonly used to facilitate neural network training.
The sigmoid function is an example that emulates biological neurons and was used in early work on neural networks, but now the simpler ReLU function is more commonly used to facilitate neural network training.
The ReLU function corresponds to the biological analogy that neurons may or may not be active. If a certain threshold is passed, then the function is triggered, and if it is not passed, then the neuron simply remains inactive, with an activation equal to zero.
It turned out that for deep multilayer networks, the ReLU function works very well and it often makes no sense to use the more difficult sigmoid function to calculate.
The question arises: how does the network described in the first lesson find the appropriate weights and shifts only from the received data? This is what the second lesson is about.
In general, the algorithm is to show the neural network a set of training data representing pairs of images of handwritten numbers and their abstract mathematical representations.
In general terms
As a result of training, the neural network should correctly distinguish numbers from previously unrepresented test data. Accordingly, the ratio of the number of acts of correct recognition of digits to the number of elements of the test sample can be used as a test for training the neural network.
Where does training data come from? The problem under consideration is very common, and to solve it, a large MNIST database was created, consisting of 60 thousand labeled data and 10 thousand test images.
Cost function
Conceptually, the task of training a neural network is reduced to finding the minimum of a certain function - the cost function. Let's describe what it is.
As you remember, each neuron of the next layer is connected to the neuron of the previous layer, while the weights of these connections and the total shift determine its activation function. In order to start somewhere, we can initialize all these weights and shifts with random numbers.
Accordingly, at the initial moment, an untrained neural network in response to an image of a given number, for example, an image of a triple, the output layer gives a completely random answer.
To train the neural network, we will introduce a cost function, which will, as it were, tell the computer in the event of a similar result: “No, bad computer! The activation value must be zero for all neurons except for the one that is correct.”
Setting the cost function for digit recognition
Mathematically, this function represents the sum of the squared differences between the actual activation values of the output layer and their ideal values. For example, in the case of a triple, the activation must be zero for all neurons, except for the one corresponding to the triple, for which it is equal to one.
It turns out that for one image we can determine one current value of the cost function. If the neural network is trained, this value will be small, ideally tending to zero, and vice versa: the larger the value of the cost function, the worse the neural network is trained.
Thus, in order to subsequently determine how well the neural network was trained, it is necessary to determine the average value of the cost function for all images of the training set.
This is a rather difficult task. If our neural network has 784 pixels at the input, 10 values at the output and requires 13 thousand parameters to calculate them, then the cost function is a function of these 13 thousand parameters, it produces one single cost value that we want to minimize, and at the same time in the entire training set serves as parameters.
How to change all these weights and shifts so that the neural network is trained?
Gradient Descent
First, instead of representing a function with 13k inputs, let's start with a function of one variable, C(w). As you probably remember from the course of mathematical analysis, in order to find the minimum of a function, you need to take the derivative.
However, the form of a function can be very complex, and one flexible strategy is to start at some arbitrary point and step down the value of the function. By repeating this procedure at each subsequent point, one can gradually come to a local minimum of the function, as does a ball rolling down a hill.
By repeating this procedure at each subsequent point, one can gradually come to a local minimum of the function, as does a ball rolling down a hill.
As shown in the figure above, a function can have many local minima, and which local minimum the algorithm ends up in depends on the choice of starting point, and there is no guarantee that the minimum found is the minimum possible value of the cost function. This must be kept in mind. In addition, in order not to "slip" the value of the local minimum, you need to change the step size in proportion to the slope of the function.
Slightly complicating this problem, instead of a function of one variable, you can represent a function of two variables with one output value. The corresponding function for finding the direction of the fastest descent is the negative gradient -∇С. The gradient is calculated, a step is taken in the direction of -∇С, the procedure is repeated until we are at the minimum.
The described idea is called gradient descent and can be applied to find the minimum of not only a function of two variables, but also 13 thousand, and any other number of variables. Imagine that all weights and shifts form one large column vector w. For this vector, you can calculate the same cost function gradient vector and move in the appropriate direction by adding the resulting vector to the w vector. And so repeat this procedure until the function С(w) comes to a minimum.
Imagine that all weights and shifts form one large column vector w. For this vector, you can calculate the same cost function gradient vector and move in the appropriate direction by adding the resulting vector to the w vector. And so repeat this procedure until the function С(w) comes to a minimum.
Gradient Descent Components
For our neural network, steps towards a lower cost function value will mean less random behavior of the neural network in response to training data. The algorithm for efficiently calculating this gradient is called backpropagation and will be discussed in detail in the next section.
For gradient descent, it is important that the output values of the cost function change smoothly. That is why activation values are not just binary values of 0 and 1, but represent real numbers and are in the interval between these values.
Each gradient component tells us two things. The sign of a component indicates the direction of change, and the absolute value indicates the effect of this component on the final result: some weights contribute more to the cost function than others.
Checking the assumption about the assignment of hidden layers
Let's discuss the question of how the layers of the neural network correspond to our expectations from the first lesson. If we visualize the weights of the neurons of the first hidden layer of the trained neural network, we will not see the expected figures that would correspond to the small constituent elements of the numbers. We will see much less clear patterns corresponding to how the neural network has minimized the cost function.
On the other hand, the question arises, what to expect if we pass an image of white noise to the neural network? It could be assumed that the neural network should not produce any specific number and the neurons of the output layer should not be activated or, if they are activated, then in a uniform way. Instead, the neural network will respond to a random image with a well-defined number.
Although the neural network performs digit recognition operations, it has no idea how they are written. In fact, such neural networks are a rather old technology developed in the 80s-90 years. However, it is very useful to understand how this type of neural network works before understanding modern options that can solve various interesting problems. But the more you dig into what the hidden layers of a neural network are doing, the less intelligent the neural network seems to be.
In fact, such neural networks are a rather old technology developed in the 80s-90 years. However, it is very useful to understand how this type of neural network works before understanding modern options that can solve various interesting problems. But the more you dig into what the hidden layers of a neural network are doing, the less intelligent the neural network seems to be.
Learning on structured and random data
Consider an example of a modern neural network for recognizing various objects in the real world.
What happens if you shuffle the database so that the object names and images no longer match? Obviously, since the data is labeled randomly, the recognition accuracy on the test set will be useless. However, at the same time, on the training sample, you will receive recognition accuracy at the same level as if the data were labeled in the right way.
Millions of weights on this particular modern neural network will be fine-tuned to exactly match the data and its markers.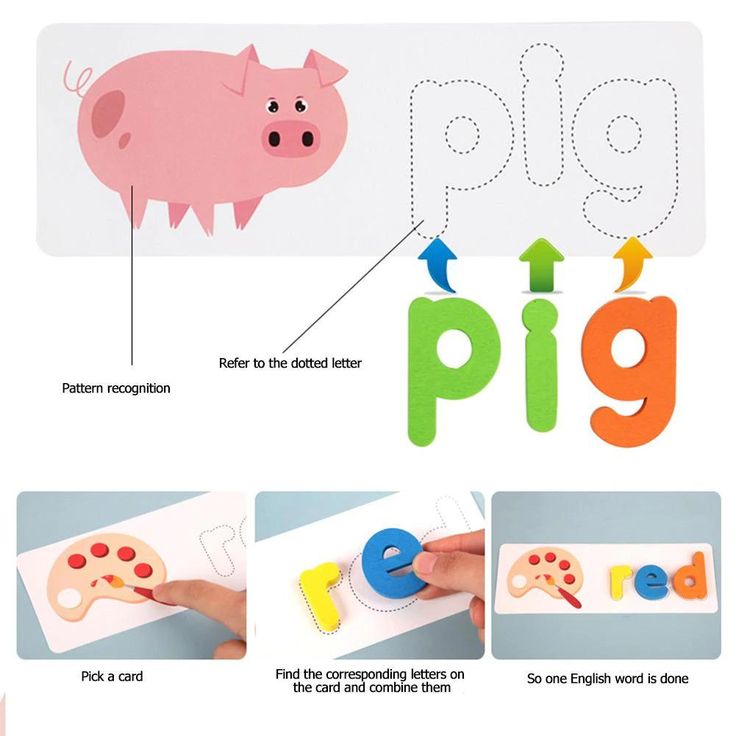 Does the minimization of the cost function correspond to some image patterns, and does learning on randomly labeled data differ from training on incorrectly labeled data?
Does the minimization of the cost function correspond to some image patterns, and does learning on randomly labeled data differ from training on incorrectly labeled data?
If you train a neural network for the recognition process on randomly labeled data, then training is very slow, the cost curve from the number of steps taken behaves almost linearly. If training takes place on structured data, the value of the cost function decreases in a much smaller number of iterations.
Backpropagation is a key neural network training algorithm. Let us first discuss in general terms what the method consists of.
Neuron activation control
Each step of the algorithm uses in theory all examples of the training set. Let us have an image of a 2 and we are at the very beginning of training: weights and shifts are set randomly, and some random pattern of output layer activations corresponds to the image.
We cannot directly change the activations of the final layer, but we can influence the weights and shifts to change the activation pattern of the output layer: decrease the activation values of all neurons except the corresponding 2, and increase the activation value of the desired neuron. In this case, the increase and decrease is required the stronger, the farther the current value is from the desired one.
Neural network settings
Let's focus on one neuron, corresponding to the activation of neuron 2 on the output layer. As we remember, its value is the weighted sum of the activations of the neurons of the previous layer plus the shift, wrapped in a scaling function (sigmoid or ReLU).
So to increase the value of this activation, we can:
- Increase the shift b.
- Increase weights w i .
- Swap previous layer activations a and .
From the weighted sum formula, it can be seen that the weights corresponding to connections with the most activated neurons make the greatest contribution to neuron activation. A strategy similar to biological neural networks is to increase the weights w i in proportion to the activation value a i of the corresponding neurons of the previous layer. It turns out that the most activated neurons are connected to the neuron that we only want to activate with the most "strong" connections.
A strategy similar to biological neural networks is to increase the weights w i in proportion to the activation value a i of the corresponding neurons of the previous layer. It turns out that the most activated neurons are connected to the neuron that we only want to activate with the most "strong" connections.
Another close approach is to change the activations of neurons of the previous layer a i in proportion to the weights w i . We cannot change the activation of neurons, but we can change the corresponding weights and shifts and thus affect the activation of neurons.
Backpropagation
The penultimate layer of neurons can be considered similarly to the output layer. You collect information about how the activations of neurons in this layer would have to change in order for the activations of the output layer to change.
It is important to understand that all these actions occur not only with the neuron corresponding to the two, but also with all the neurons of the output layer, since each neuron of the current layer is connected to all the neurons of the previous one.
Having summed up all these necessary changes for the penultimate layer, you understand how the second layer from the end should change. Then, recursively, you repeat the same process to determine the weight and shift properties of all layers.
Classic Gradient Descent
As a result, the entire operation on one image leads to finding the necessary changes of 13 thousand weights and shifts. By repeating the operation on all examples of the training sample, you get the change values for each example, which you can then average for each parameter separately.
The result of this averaging is the negative gradient column vector of the cost function.
Stochastic Gradient Descent
Considering the entire training set to calculate a single step slows down the gradient descent process. So the following is usually done.
The data of the training sample are randomly mixed and divided into subgroups, for example, 100 labeled images. Next, the algorithm calculates the gradient descent step for one subgroup.
Next, the algorithm calculates the gradient descent step for one subgroup.
This is not exactly a true gradient for the cost function, which requires all the training data, but since the data is randomly selected, it gives a good approximation, and, importantly, allows you to significantly increase the speed of calculations.
If you build the learning curve of such a modernized gradient descent, it will not look like a steady, purposeful descent from a hill, but like a winding trajectory of a drunk, but taking faster steps and also coming to a function minimum.
This approach is called stochastic gradient descent.
Supplement. Backpropagation Math
Now let's look a little more formally at the mathematical background of the backpropagation algorithm.
Primitive neural network model
Let's start with an extremely simple neural network consisting of four layers, where each layer has only one neuron. Accordingly, the network has three weights and three shifts. Consider how sensitive the function is to these variables.
Accordingly, the network has three weights and three shifts. Consider how sensitive the function is to these variables.
Let's start with the connection between the last two neurons. Let's denote the last layer L, the penultimate one L-1, and the activations of the considered neurons lying in them a (L) , a (L-1) .
Cost function
Imagine that the desired activation value of the last neuron given to the training examples is y, equal to 0 or 1, for example. Thus, the cost function is defined for this example as
C 0 = (a ( L) - y) 2 .
Recall that the activation of this last neuron is given by the weighted sum, or rather the scaling function of the weighted sum: (L) ).
For brevity, the weighted sum can be denoted by a letter with the appropriate index, for example z (L) :
a (L) = σ (z (L) ).
Consider how small changes in the weight w affect the value of the cost function (L) . Or in mathematical terms, what is the derivative of the cost function with respect to weight ∂C 0 /∂w (L) ?
Or in mathematical terms, what is the derivative of the cost function with respect to weight ∂C 0 /∂w (L) ?
It can be seen that the change in C 0 depends on the change in a (L) , which in turn depends on the change in z (L) , which depends on w (L) . According to the rule of taking similar derivatives, the desired value is determined by the product of the following partial derivatives:0459 (L) /∂w (L) • ∂a (L) /∂z (L) • ∂C 0 /∂a (L) .
Definition of derivatives
Calculate the corresponding derivatives: and desired.
The average derivative in the chain is simply the derivative of the scaling function:
∂a (L) /∂z (L) = σ'(z (L) )
/∂w (L) = a (L-1)
Thus, the corresponding change is determined by how activated the previous neuron is. This is consistent with the idea mentioned above that a stronger connection is formed between neurons that light up together.
This is consistent with the idea mentioned above that a stronger connection is formed between neurons that light up together.
Final expression:
∂C 0 /∂w (L) = 2(a (L) - y) σ'(z (L) ) a (L-1)
Recall that a certain derivative is only for the cost of a single example of the training sample C 0 . For the cost function C, as we remember, it is necessary to average over all examples of the training sample: The resulting average value for a specific w (L) is one of the components of the cost function gradient. The consideration for shifts is identical to the above consideration for weights.
Having obtained the corresponding derivatives, we can continue the consideration for the previous layers.
Model with many neurons in the layer
However, how to make the transition from layers containing one neuron to the initially considered neural network.